일반적인 Linux 커널 네트워킹 스택의 한계를 넘어 더 높은 패킷 처리량을 얻기 위한 커널 바이패스 기법들을 살펴본다.
URL: https://blog.cloudflare.com/kernel-bypass/
이전 두 개의 글에서 우리는 초당 100만 개의 UDP 패킷을 수신하는 방법과 왕복 지연 시간(RTT)을 줄이는 방법을 다뤘습니다. 실험은 Linux에서 진행했으며, 범용 운영체제라는 점을 고려하면 성능은 매우 좋았습니다.
하지만 표준(바닐라) Linux 커널 네트워킹 속도는 더 특수한 워크로드에는 충분하지 않습니다. 예를 들어 Cloudflare에서는 대규모 패킷 플러드(폭주)를 상시로 상대합니다. 기본 Linux는 초당 약 100만 pps(packet per second) 정도만 처리할 수 있습니다. 이는 우리 환경에서는 부족합니다. 특히 네트워크 카드가 훨씬 더 높은 처리량을 다룰 수 있기 때문입니다. 최신 10Gbps NIC는 보통 최소 1천만 pps 이상을 처리할 수 있습니다.
 CC BY 2.0 image by Tony Webster
CC BY 2.0 image by Tony Webster
하드웨어에서 더 많은 패킷을 쥐어짜는 유일한 방법은 Linux 커널 네트워킹 스택을 우회하는 것입니다. 이를 “커널 바이패스(kernel bypass)”라고 하며, 이 글에서는 이를 달성하는 다양한 방법을 파고들어 보겠습니다.
Linux를 우회하는 것이 정말로 필요하다는 점을 납득시키기 위해 작은 실험을 준비해봅시다. 완벽한 조건에서 커널이 얼마나 많은 패킷을 처리할 수 있는지 보겠습니다. 패킷을 유저 공간(userspace)으로 넘기는 것은 비용이 크므로, 대신 네트워크 드라이버 코드에서 빠져나오자마자 즉시 드롭(drop)해 보겠습니다. 제 지식으로는 커널 소스를 해킹하지 않고 Linux에서 패킷을 가장 빠르게 드롭하는 방법은 PREROUTING iptables 체인에 DROP 규칙을 넣는 것입니다:
$ sudo iptables -t raw -I PREROUTING -p udp --dport 4321 --dst 192.168.254.1 -j DROP
$ sudo ethtool -X eth2 weight 1
$ watch 'ethtool -S eth2|grep rx'
rx_packets: 12.2m/s
rx-0.rx_packets: 1.4m/s
rx-1.rx_packets: 0/s
...
위의 ethtool 통계는 네트워크 카드가 초당 1,200만 패킷의 라인 레이트(line rate)로 패킷을 수신하고 있음을 보여줍니다. ethtool -X로 NIC의 인다이렉션 테이블(indirection table)을 조작하여 모든 패킷을 RX 큐 #0으로 보냅니다. 보시다시피 커널은 단일 CPU로 해당 큐에서 초당 140만 pps를 처리할 수 있습니다.
단일 코어에서 140만 pps를 처리하는 것은 분명 매우 좋은 결과지만, 안타깝게도 이 스택은 확장성이 좋지 않습니다. 패킷이 여러 코어에 분산되면 수치가 급격히 떨어집니다. 패킷을 4개의 RX 큐로 보내면 어떤지 봅시다:
$ sudo ethtool -X eth2 weight 1 1 1 1
$ watch 'ethtool -S eth2|grep rx'
rx_packets: 12.1m/s
rx-0.rx_packets: 477.8k/s
rx-1.rx_packets: 447.5k/s
rx-2.rx_packets: 482.6k/s
rx-3.rx_packets: 455.9k/s
이제 코어당 약 48만 pps만 처리합니다. 이는 좋지 않은 소식입니다. 낙관적으로 더 많은 코어를 추가해도 성능이 더 떨어지지 않는다고 가정하더라도, 라인 레이트로 패킷을 처리하려면 CPU가 20개 이상 필요합니다. 즉 커널만으로는 해결되지 않습니다.
 CC BY 2.0 image by Matt Brown
CC BY 2.0 image by Matt Brown
Linux 커널 네트워크의 성능 한계는 새로운 이야기가 아닙니다. 수년에 걸쳐 이를 해결하려는 많은 시도가 있었습니다. 가장 흔한 기법은 하드웨어에서 매우 높은 속도로 패킷을 수신할 수 있도록 돕는 특수 API를 만드는 것입니다. 하지만 이러한 기법들은 여전히 변화가 심하며, 널리 채택된 단일 접근법은 아직 등장하지 않았습니다.
다음은 가장 잘 알려진 커널 바이패스 기법들의 목록입니다.
Packet_mmap은 빠른 패킷 스니핑을 위한 Linux API입니다. 엄밀히 말해 커널 바이패스 기법은 아니지만, 표준 커널에 이미 포함되어 있다는 점에서 목록에 포함할 가치가 있습니다.
PF_RING은 패킷 캡처를 빠르게 하려는 또 다른 유명한 기법입니다. packet_mmap과 달리 PF_RING은 메인라인 커널에 포함되어 있지 않으며, 특수 모듈이 필요합니다. ZC 드라이버와 transparent_mode=2를 사용하면 패킷은 커널 네트워크 스택이 아니라 PF_RING 클라이언트에게만 전달됩니다. 느린 부분이 커널이므로, 이렇게 하면 가장 빠르게 동작할 수 있습니다.
Snabbswitch는 주로 L2 애플리케이션 작성을 목표로 하는 Lua 기반 네트워킹 프레임워크입니다. 네트워크 카드를 완전히 장악하고, 유저 공간에서 하드웨어 드라이버를 구현하는 방식으로 동작합니다. 이는 PCI 디바이스 수준에서 userspace IO(UIO)의 한 형태로 이루어지며, sysfs를 통해 디바이스 레지스터를 mmap합니다. 매우 빠른 동작이 가능하지만, 패킷이 커널 네트워크 스택을 완전히 건너뛰게 됩니다.
DPDK는 Intel 칩을 위해 특별히 만들어진 C 기반 네트워킹 프레임워크입니다. 전체 프레임워크라는 점에서 snabbswitch와 유사하며, UIO에 의존합니다.
Netmap 역시 풍부한 프레임워크이지만, UIO 기법과 달리 몇 개의 커널 모듈로 구현됩니다. 네트워킹 하드웨어와 통합하려면 사용자가 커널 네트워크 드라이버에 패치를 적용해야 합니다. 복잡성이 늘어나는 대신, 잘 문서화된 벤더 중립(vendor-agnostic)이며 깔끔한 API를 얻습니다.
커널 바이패스의 목표는 커널이 패킷을 처리하지 않게 하는 것이므로 packet_mmap은 제외할 수 있습니다. 이는 패킷을 “가져가는” 방식이 아니라 단지 빠른 스니핑 인터페이스에 불과합니다. 마찬가지로 ZC 모듈 없는 일반 PF_RING은 주목적이 libpcap 가속이기 때문에 매력적이지 않습니다.
두 가지는 이미 제외했지만, 불행히도 우리 워크로드에서는 남은 솔루션들도 모두 받아들이기 어렵습니다!
왜 그런지 설명하겠습니다. 커널 바이패스를 달성하기 위해 남은 기법들인 Snabbswitch, DPDK, netmap은 모두 네트워크 카드를 통째로 장악하며, 해당 NIC로 들어오는 어떤 트래픽도 커널로 도달하지 못하게 합니다. Cloudflare에서는 특정 오프로딩(offloaded) 애플리케이션 하나를 위해 NIC 전체를 전용으로 할당할 여유가 없습니다.
그렇다고 해서 위 기법들이 쓸모없다는 뜻은 아닙니다. 다른 상황에서는 NIC를 바이패스 용도로 전용하는 것이 충분히 받아들여질 수 있습니다.
위에 나열한 기법들은 NIC 전체를 장악해야 하지만, 대안도 존재합니다.
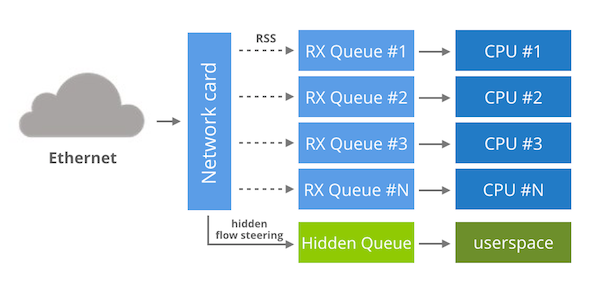
Solarflare 네트워크 카드는 마법 같은 네트워크 가속기인 OpenOnload를 지원합니다. OpenOnload는 유저 공간에 네트워크 스택을 구현하고, LD_PRELOAD로 대상 프로그램의 네트워크 syscall을 덮어쓰는 방식으로 커널 바이패스를 달성합니다. 네트워크 카드에 대한 저수준 접근을 위해 OpenOnload는 “EF_VI” 라이브러리에 의존합니다. 이 라이브러리는 직접 사용할 수도 있으며 문서도 잘 되어 있습니다.
EF_VI는 독점(proprietary) 라이브러리이므로 Solarflare NIC에서만 사용할 수 있습니다. 하지만 실제로 내부에서 어떻게 동작하는지 궁금할 수 있습니다. EF_VI는 일반적인 NIC 기능을 매우 영리하게 재활용합니다.
내부적으로 각 EF_VI 프로그램은 커널에서 숨겨진 전용 RX 큐에 접근 권한을 부여받습니다. 기본 상태에서는 이 큐는 어떤 패킷도 받지 않으며, EF_VI “필터(filter)”를 만들기 전까지는 그렇습니다. 이 필터는 숨겨진 플로우 스티어링(flow steering) 규칙에 불과합니다. ethtool -n으로는 보이지 않지만, 실제로 해당 규칙은 네트워크 카드에 존재합니다. RX 큐를 할당하고 플로우 스티어링 규칙을 관리한 뒤, EF_VI에 남은 일은 큐에 접근하기 위한 유저 공간 API를 제공하는 것뿐입니다.
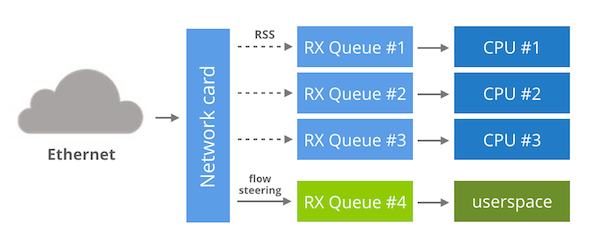
EF_VI는 Solarflare에만 해당되지만, 다른 NIC에서도 유사한 기법을 재현할 수 있습니다. 이를 위해서는 플로우 스티어링과 인다이렉션 테이블 조작을 지원하는 멀티 큐 네트워크 카드가 필요합니다.
이 기능들이 있으면 다음이 가능합니다:
네트워크 카드를 평소처럼 시작하고, 모든 것은 커널이 관리하게 둡니다.
인다이렉션 테이블을 수정하여 특정 RX 큐 하나로는 어떤 패킷도 흐르지 않게 합니다. 예를 들어 RX 큐 #16을 선택했다고 합시다.
플로우 스티어링 규칙으로 특정 네트워크 플로우를 RX 큐 #16으로 보냅니다.
이렇게 한 뒤 남은 단계는 다른 RX 큐에는 영향을 주지 않으면서, 유저 공간에서 RX 큐 #16으로부터 패킷을 수신할 수 있는 API를 제공하는 것입니다.
이 아이디어는 DPDK 커뮤니티에서 “분기(bifurcated) 드라이버”라고 부릅니다. 2014년에 분기 드라이버를 만들려는 시도가 있었지만, 아쉽게도 해당 패치가 아직 메인라인 커널로 들어가지는 못했습니다.
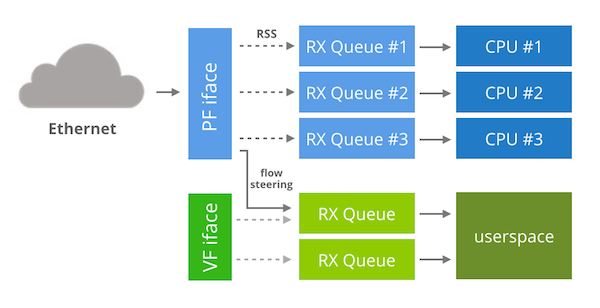
Intel 82599 칩에는 또 다른 대안 전략이 있습니다. 분기 드라이버 대신, NIC의 가상화 기능을 활용해 커널 바이패스를 할 수 있습니다.
먼저 약간의 배경 설명이 필요합니다. 가상화 세계에서는 호스트에서 게스트 VM으로 패킷을 전달하는 과정이 종종 병목이 됩니다. 가상화 성능 요구가 수년에 걸쳐 증가하면서, 네트워킹 하드웨어를 소프트웨어로 에뮬레이션하는 기존 방식은 큰 성능 부담이 되었습니다.
네트워크 카드 벤더들은 가상화 게스트를 가속하는 기능을 추가해 해결에 나섰습니다. 가상화 기법 중 하나는 네트워크 카드가 자신을 여러 개의 PCI 디바이스로 보이게 하는 것입니다. 이렇게 만들어진 가짜 가상 인터페이스는 호스트 운영체제의 협조 없이도 가상화 게스트 내부에서 사용할 수 있습니다. 실제로 어떤 모습인지 보여드리겠습니다. 예를 들어 아래는 82599 네트워크 카드의 기본(네이티브) 상태입니다. 이 “진짜” 디바이스는 PF(physical function) 인터페이스라고 부릅니다:
$ lspci
04:00.1 Ethernet controller: Intel Corporation 82599EB 10-Gigabit SFI/SFP+ Network Connection (rev 01)
이 디바이스에게 VF(virtual function) 디바이스 하나를 만들라고 요청합니다:
$ echo 1 > /sys/class/net/eth3/device/sriov_numvfs
$ lspci
04:00.1 Ethernet controller: Intel Corporation 82599EB 10-Gigabit SFI/SFP+ Network Connection (rev 01)
04:10.1 Ethernet controller: Intel Corporation 82599 Ethernet Controller Virtual Function (rev 01)
이 가짜 PCI 디바이스는 예를 들어 KVM 게스트에 쉽게 할당할 수 있습니다. 반대로 호스트 환경에서 사용하는 것도 가능합니다. 이를 위해 “ixgbevf” 커널 모듈을 로드하면 또 다른 “ethX” 인터페이스가 나타납니다.
이게 커널 바이패스에 어떻게 도움이 될까요? “ixgbevf” 디바이스는 커널이 일반 네트워킹을 처리하는 데 사용하지 않으므로, 이를 바이패스에 전용으로 사용할 수 있습니다. 또한 “ixgbevf” 디바이스에서 DPDK를 실행하는 것이 가능해 보입니다.
정리하면: PF 디바이스는 정상적인 커널 작업을 처리하도록 유지하고, VF 인터페이스 하나를 커널 바이패스에 전용합니다. VF가 전용이므로 “NIC 전체를 장악하는” 기법을 사용할 수 있습니다.
종이 위에서는 좋아 보이지만, 실제로는 그렇게 간단하지 않습니다. 첫째, DPDK만 “ixgbevf” 인터페이스를 지원하며, netmap, snabbswitch, PF_RING는 지원하지 않습니다. 둘째, 기본 설정에서는 VF 인터페이스는 어떤 패킷도 받지 않습니다. PF에서 VF로 일부 플로우를 보내려면 ixgbe에 대한 이 난해한 패치가 필요합니다. 이 패치를 적용하면 ethtool에서 “action” 큐 번호의 상위 비트에 VF 정보를 인코딩하여 VF를 지정할 수 있습니다. 예를 들면:
$ ethtool -N eth3 flow-type tcp4 dst-ip 192.168.254.30 dst-port 80 action 4294967296
마지막 장애물도 있습니다. 82599 칩에서 VF 기능을 활성화하면 RSS 그룹의 최대 크기가 줄어듭니다. 가상화 없이 82599는 16개 CPU 코어에 대해 RSS를 수행할 수 있지만, VF를 활성화하면 이 수치는 4로 떨어집니다. PF에서 트래픽이 적다면 4코어로만 분산해도 괜찮을 수 있지만, Cloudflare에서는 큰 RSS 그룹 크기가 필요합니다.
커널 바이패스를 달성하는 일은 그렇게 간단하지 않습니다. 많은 오픈소스 기법이 존재하지만, 모두 전용 네트워크 카드가 필요해 보입니다. 우리는 다음의 세 가지 가능한 대안 아키텍처를 보여줬습니다:
EF_VI 스타일의 숨겨진 RX 큐
DPDK 분기(bifurcated) 드라이버
VF 해킹(hack)
불행히도 우리가 조사한 많은 기법 중, 우리 환경에서 실용적이라고 볼 수 있는 것은 EF_VI뿐이었습니다. 전용 NIC를 요구하지 않는 오픈소스 커널 바이패스 API가 곧 등장하기를 바랍니다.