CPython JIT가 macOS AArch64와 x86_64 Linux에서 목표 성능을 예정보다 앞서 달성하게 된 배경과, 그 과정에서의 사람·운·설계 선택(트레이스 기록, 참조 카운트 제거), 그리고 협업의 중요성을 정리합니다.
17 Mar 2026
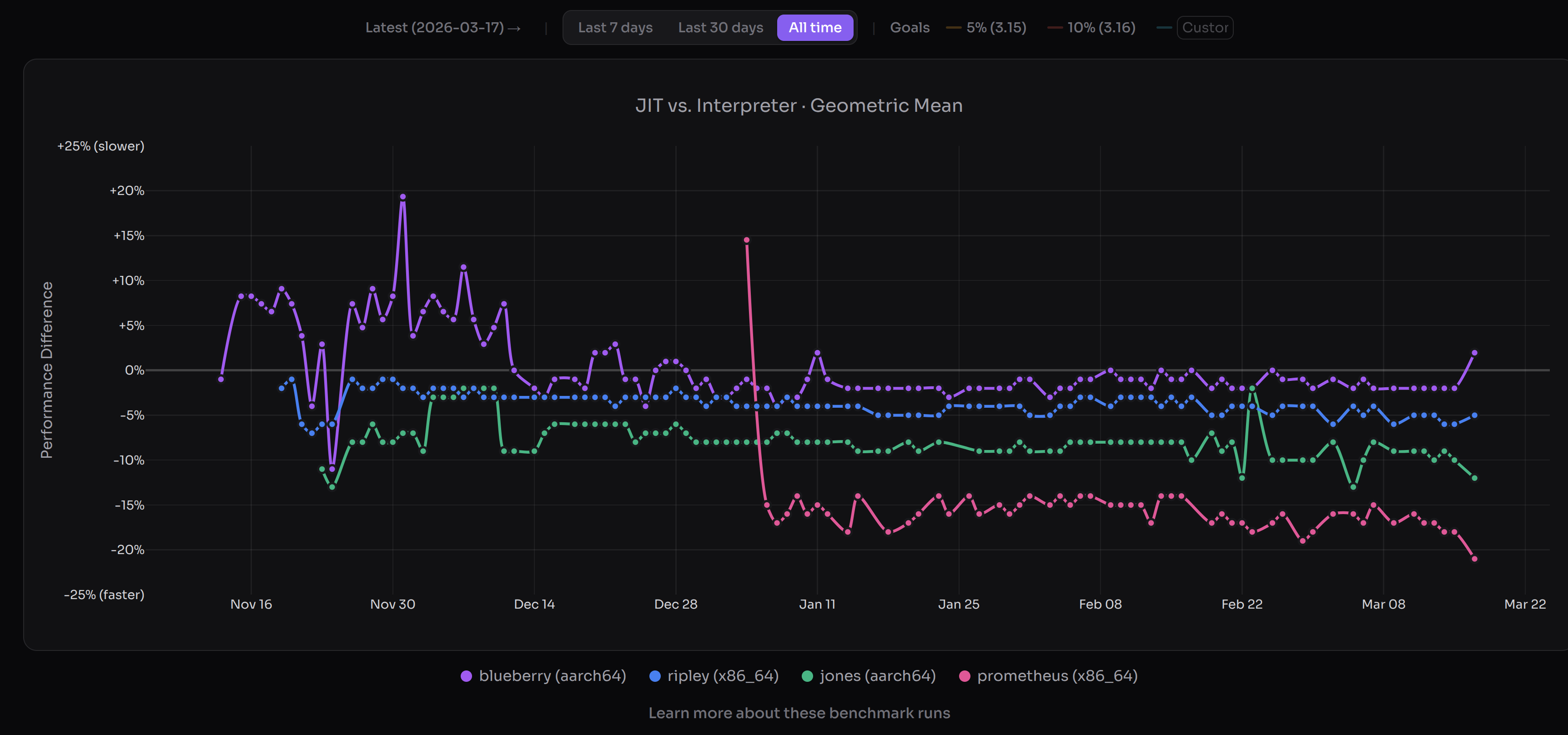 (3월 17일(PST) 기준 JIT 성능. 인터프리터 대비 낮을수록 좋습니다. 이미지 크레딧: https://doesjitgobrrr.com/).
(3월 17일(PST) 기준 JIT 성능. 인터프리터 대비 낮을수록 좋습니다. 이미지 크레딧: https://doesjitgobrrr.com/).
좋은 소식입니다—macOS AArch64에서는 1년 이상, x86_64 Linux에서는 몇 달 앞당겨, CPython JIT의(아주 소박한) 성능 목표를 달성했습니다. 3.15 알파 JIT는 macOS AArch64에서 테일 콜링 인터프리터보다 약 11-12% 빠르고, x86_64 Linux에서는 표준 인터프리터보다 5-6% 빠릅니다. 이 수치는 기하평균이며 예비 결과입니다. 실제 범위는( unpack_sequence 마이크로벤치마크는 제외하면) 대략 20% 느려짐부터 100%를 넘는 가속까지입니다. 아직 제대로 된 free-threading 지원은 없지만, 3.15/3.16에서 이를 목표로 하고 있습니다. JIT는 이제 다시 궤도에 올랐습니다.
이게 얼마나 힘들었는지 아무리 강조해도 부족합니다. 어느 시점에는 JIT 프로젝트가 과연 의미 있는 가속을 만들어낼 수 있을지 진지하게 의심했습니다. 요약하자면, 원래의 CPython JIT는 사실상 가속이 거의 없었습니다. 8개월 전, 저는 3.13과 3.14의 초기 CPython JIT가 종종 인터프리터보다 더 느렸다는 내용의 JIT 회고 글을 올렸습니다. 그 무렵 Faster CPython 팀은 주요 스폰서로부터의 자금 지원도 끊겼습니다. 저는 자원봉사자라 개인적으로는 영향이 없었지만, 더 중요한 건 거기서 일하던 친구들에게는 영향이 있었고, 한때는 JIT의 미래가 불확실해 보였습니다.
그렇다면 3.13/3.14에서 무엇이 바뀌었을까요? 실패의 턱에서 우리의 식견으로 JIT를 구해낸 영웅담을 늘어놓지는 않겠습니다. 솔직히 말해 지금의 성과는 운의 영향이 큽니다—좋은 타이밍, 좋은 자리, 좋은 사람들, 좋은 베팅. 핵심 JIT 기여자 중 단 한 명이라도—Savannah Ostrowski, Mark Shannon, Diego Russo, Brandt Bucher, 그리고 저—빠졌다면 이건 불가능했을 거라고 진심으로 생각합니다. 다른 활발한 JIT 기여자들을 배제하지 않기 위해 몇 분을 더 언급하자면: Hai Zhu, Zheaoli, Tomas Roun, Reiden Ong, Donghee Na, 그리고 아마 몇 명 더 빼먹었을 겁니다.
이 글에서는 JIT에서 비교적 덜 이야기되는 부분—사람, 그리고 약간의 운—을 다루려 합니다. 어떻게 했는지의 기술적 세부사항은 여기에 있습니다.
Faster CPython 팀은 2025년에 주요 스폰서를 잃었습니다. 저는 곧바로 커뮤니티 주도의 관리라는 아이디어를 꺼냈습니다. 당시에는 이게 제대로 될지 꽤 불확실했습니다. JIT 프로젝트는 새 기여자에게 친절한 것으로 유명하지 않습니다. 역사적으로도 많은 사전 전문지식이 필요했습니다.
케임브리지에서 열린 CPython 코어 스프린트에서 JIT 코어 팀이 모였고, 3.15까지 5% 더 빠른 JIT, 3.16까지 10% 더 빠른 JIT(그리고 free-threading 지원)를 목표로 하는 계획을 썼습니다. 덜 헤드라인을 탔지만 프로젝트의 건강에 필수적이었던 부가 목표도 있었는데, 바로 버스 팩터를 낮추는 것이었습니다. JIT의 3단계—프런트엔드(리전 셀렉터), 미들엔드(옵티마이저), 백엔드(코드 생성기)—각각에 활동적인 메인테이너 2명을 두고 싶었습니다.
이전에는 미들엔드에 반복적으로 기여하는 활동적인 사람이 2명뿐이었습니다. 오늘날에는 미들엔드에 4명의 활동적인 반복 기여자가 있고, 코어 개발자가 아닌 2명(Hai Zhu와 Reiden)도 유능하고 소중한 구성원이라고 봅니다.
사람을 끌어들이는 데 효과가 있었던 것은 통상적인 소프트웨어 엔지니어링 관행이었습니다. 복잡한 문제를 관리 가능한 조각으로 쪼개는 것이죠. Brandt는 3.14에서 이미 이 작업을 시작했는데, JIT 최적화를 단순한 과업들로 나누는 여러 메가 이슈를 열었습니다. 예를 들어 “JIT에서 단일 명령어 하나를 최적화해 보자”처럼요. 저는 Brandt의 아이디어를 받아 3.15에서 같은 방식을 썼습니다. 운 좋게도 제 이슈는 인터프리터 명령어를 더 쉽게 최적화 가능한 형태로 변환하는 일이어서, 상대적으로 수월한 편이었습니다. 새 기여자를 독려하기 위해, 저는 곧바로 실행 가능한 매우 자세한 지침도 정리해 두었습니다. 또한 작업 단위를 명확히 구분했습니다. 이게 도움이 되었던 것 같은데, 해당 이슈에 저를 포함해 11명이 참여해 인터프리터 거의 전부를 JIT 옵티마이저에 더 친화적인 형태로 바꾸고 있습니다. 핵심은, JIT를 불투명한 덩어리에서 “JIT 경험이 없는 C 프로그래머도 기여할 수 있는 것”으로 쪼갤 수 있었다는 점입니다.
효과가 있었던 다른 것들: 사람들을 격려하고, 크든 작든 성과를 축하하는 것. 각 JIT PR에는 명확한 결과가 있었고, 그게 사람들에게 방향감을 줬던 것 같습니다.
커뮤니티 최적화 노력은 성과를 냈습니다. 그 기간 동안 JIT는 x86_64 Linux에서 1% 빠름에서 3-4% 빠름으로(아래의 파란 선 참조) 개선되었습니다.
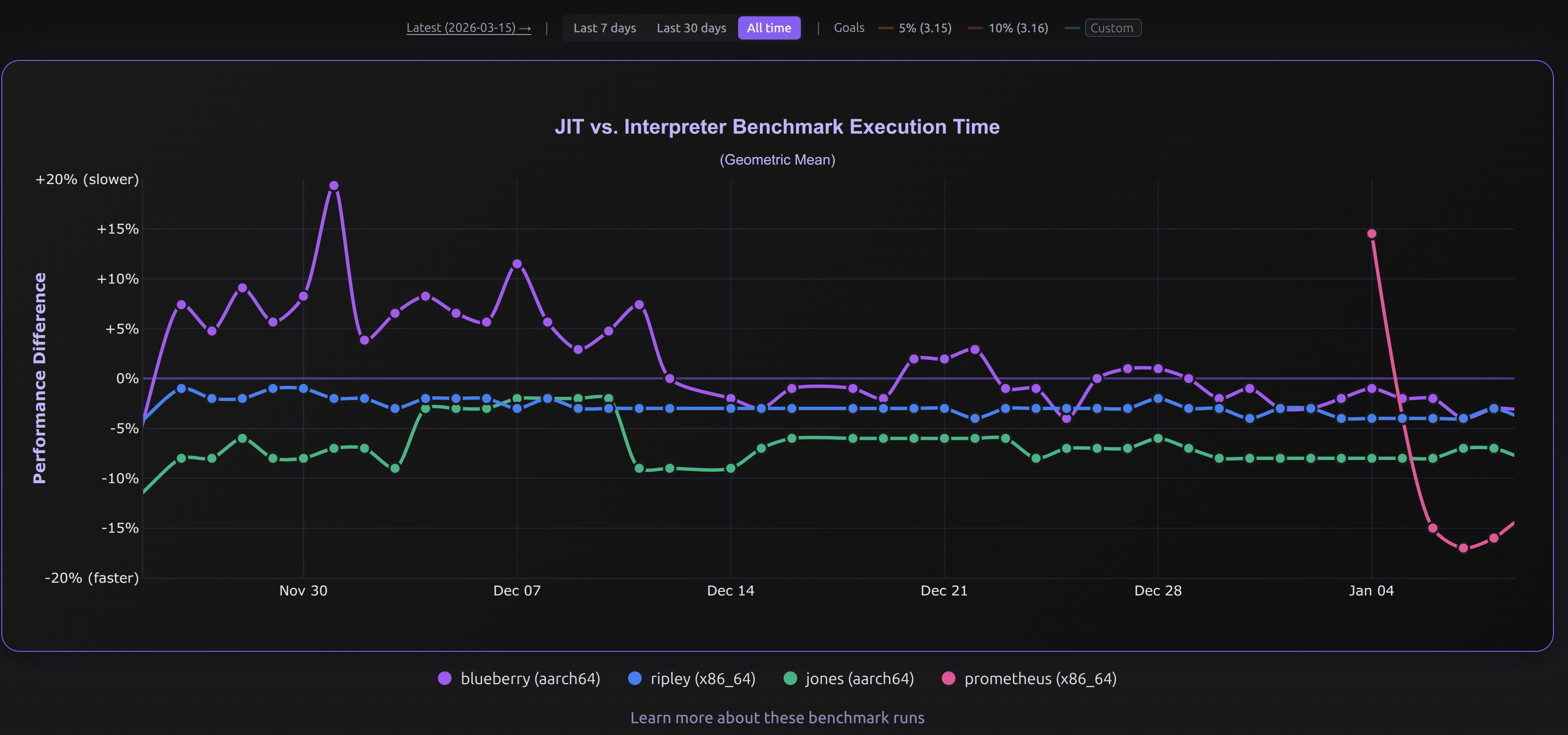 (이미지 크레딧: https://doesjitgobrrr.com/).
(이미지 크레딧: https://doesjitgobrrr.com/).
다시 말하지만, 이 또한 운이 많이 작용했다고 보는데, 케임브리지에서 열린 CPython 코어 스프린트 동안 Brandt가 저를 ‘너드 스나이프’해서 JIT 프런트엔드를 트레이싱 방식으로 다시 쓰게 만들었습니다. 처음에는 그 아이디어가 마음에 들지 않았지만, 우호적인 형태의 spite-driven-development로 “안 된다”는 걸 증명하려고 그냥 다시 써 보기로 했습니다.
초기 프로토타입은 3일 만에 동작했지만, 테스트 스위트를 깨지 않고 제대로 JIT가 돌게 만들기까지는 한 달이 걸렸습니다. 초기 결과는 참담했습니다—x86_64 Linux에서 약 6% 느려졌습니다. 저는 이 아이디어를 버리려 했는데, 그때 운 좋은 사고가 일어났습니다. Mark가 준 제안을 제가 잘못 해석했던 겁니다.
Mark는 이전에 디스패치 테이블을 인터프리터에 ‘스레딩’해서, 인터프리터 안에 디스패치 테이블을 두 개(하나는 일반 인터프리터용, 하나는 트레이싱용) 두자고 제안했습니다. Mark의 제안은 트레이싱 테이블이 일반 명령어들의 트레이싱 버전들이어야 한다는 것이었습니다. 하지만 저는 이를 오해해 더 극단적인 버전을 떠올렸습니다. 일반 명령어의 트레이싱 버전들을 만들기보다는, 트레이싱을 담당하는 단 하나의 명령어만 두고 두 번째 테이블의 모든 명령어가 그 하나를 가리키게 만든 겁니다. 네, 이 부분이 헷갈린다는 걸 압니다. 언젠가 더 잘 설명해 보겠습니다. 그런데 이 선택이 정말 정말 좋은 선택이었습니다. 초기의 듀얼 테이블 접근은 인터프리터의 크기가 두 배가 되면서 컴파일된 코드가 크게 부풀어, 당연히 느려졌던 겁니다. 단 하나의 명령어와 두 개의 테이블만 사용하면 인터프리터 크기는 명령어 1개만큼만 늘고, 기본 인터프리터는 초고속으로 유지됩니다. 저는 이 메커니즘을 애칭으로 dual dispatch라고 부릅니다.
트레이스 기록 인터프리터의 설계에는 더 많은 요소가 있습니다. 제 자화자찬이긴 하지만, 정말 미니 예술작품이라고 생각합니다. 전체적으로 더 빨라지도록 인터프리터를 다듬는 데 1주일이 걸렸습니다. dual dispatch를 적용한 뒤에는 6% 느림에서 대략 가속이 없는 수준으로 올라왔습니다. 그 뒤 트레이싱 인터프리터의 느린 엣지 케이스들을 다수 제거해 최종적으로 1.x% 정도 더 빠르게 만들었습니다. 제 추정으로 트레이싱 인터프리터 자체는 특화(specializing) 인터프리터보다 3-5배 정도만 느립니다. 핵심은 특화 인터프리터의 모든 일반 동작을 존중하고, 대체로 그 동작을 방해하지 않는다는 점입니다.
트레이스 기록이 얼마나 중요했는지 감을 드리자면, JIT 코드 커버리지를 50% 늘렸습니다. 즉 이후의 모든 최적화가(모든 코드가 동일하게 실행된다고 가정하면—물론 사실이 아니지만, 일단 감안해 주세요 :) ) 대략 50%는 덜 효과적이었을 가능성이 큽니다.
그래서 Brandt와 Mark에게, 제가 이런 좋은 해법을 ‘우연히’ 밟고 지나가도록 이끌어 준 데 대해 감사해야 합니다.
초기에 했던 또 하나의 운 좋은 베팅은 참조 카운트 제거(reference count elimination)를 시도한 것이었습니다. 이것 역시 원래는 Matt Page가 CPython 바이트코드 옵티마이저에서 했던 작업입니다(최적화에 관한 이전 블로그 글에 더 자세한 내용이 있습니다). 저는 바이트코드 옵티마이저 작업이 있어도 참조 카운트 감소마다 JIT된 코드에 분기가 하나 남아 있다는 것을 알아챘습니다. 그래서 “분기를 없애보면 어떨까?”라고 생각했고, 이게 얼마나 도움이 될지 전혀 감이 없었습니다. 그런데 분기 하나가 실제로 꽤 비싸고, 이런 것들이 시간이 지나며 누적됩니다. 특히 모든 Python 명령어마다 분기가 1개 이상이라면 더더욱요!
또 다른 운 좋은 점은, 이 작업이 병렬화하기 쉬웠고, 인터프리터와 JIT를 사람들에게 가르치는 훌륭한 도구가 되었다는 것입니다. 이 최적화가 우리가 Python 3.15 JIT에서 사람들에게 주로 맡겨 진행하도록 했던 메인 최적화였습니다. 대부분 수동 리팩터링 과정이긴 했지만, 사람들을 압도하지 않으면서 JIT에 대해 꼭 알아야 할 핵심 부분을 배우게 해 주었습니다.
우리에겐 훌륭한 인프라 팀이 있습니다. 농담 반 진담 반으로 이렇게 말하는데, 그건 한 사람뿐이기 때문입니다. 실제로 우리의 “팀”은 현재 Savannah의 옷장 속에서 돌아가는 4대의 머신입니다. 그럼에도 Savannah는 JIT를 위해 사실상 인프라 팀 전체에 해당하는 일을 해냈습니다. 성능 수치를 보고할 수 있는 것이 없었다면 JIT는 이렇게 빠르게 진전할 수 없었을 겁니다. 매일의 JIT 실행은 피드백 루프에서 게임 체인저였습니다. 이를 통해 JIT 성능의 회귀를 잡아낼 수 있었고, 우리의 최적화가 실제로 효과가 있는지도 알 수 있었습니다.
Mark는 기술적으로 뛰어나고, 인터넷이 이미 그에게 과도한 찬사를 보낸다는 걸 그도 알고 있다고 생각해서 여기서는 더 말하지 않겠습니다 :).
Diego도 훌륭합니다. 그는 ARM 하드웨어에서의 JIT를 담당하고 있고, 최근에는 JIT가 프로파일러에 친화적이도록 만드는 작업도 시작했습니다. 이게 얼마나 어려운 문제인지 아무리 강조해도 부족합니다.
Brandt는 머신 코드 백엔드의 원래 토대를 놓았고, 이것이 없었다면 새 기여자들이 어셈블리를 직접 작성해야 했을 텐데, 그랬다면 더 많은 사람들이 흥미를 잃었을 겁니다.
사람들과 대화하고 아이디어를 공유하는 것의 중요성도 장려하고 싶습니다.
PyPy에 대해 많은 것을 가르쳐 준 CF Bolz-Tereick에게도 감사 인사를 전합니다. 저는 몇 달 동안 PyPy의 소스 코드를 들여다봤고, 그게 전반적으로 저를 더 나은 JIT 개발자로 만들어줬다고 믿습니다. 도움이 필요할 때 CF는 정말 많은 도움을 줬습니다.
또한 Max Bernstein과의 친근한 컴파일러 채팅에도 참여하고 있는데, 그게 없었다면 저는 아마 오래전에 동기를 잃었을 겁니다. Max는 다작하는 글쓴이이자, 친절한 컴파일러 사람입니다.
아이디어는 고립된 공간에서 존재하지 않습니다. 저는 한동안 여러 컴파일러 사람들과 어울리면서 JIT를 더 잘 쓰게 된 것 같습니다. 최소한 PyPy를 들여다본 것만으로도 제 시야가 넓어졌습니다!
사람은 중요합니다. 그리고 약간의 운이 따라주면, JIT go brrr.