소프트웨어는 도메인 모델보다 유연해야 한다는 관점에서, 상태 머신, 외래 키 제약, 프로토버퍼 required 필드 사례를 통해 ‘하드한 제약’을 남발하면 변화와 운영에 취약해진다고 주장한다. 일부 잘못된 상태를 표현 가능하게 두는 것이 현실 세계의 요구를 충족하는 더 안전한 설계라는 논지.
좋은 소프트웨어 설계에 관해 내가 믿는 것들 가운데 가장 논쟁적인 것 중 하나는 코드가 도메인 모델보다 더 유연해야 한다는 점이다. 이는 인기 있는 많은 설계 조언과 정면으로 배치되는데, 그 조언들은 대개 코드를 도메인 모델에 최대한 단단히 결합하라고 말한다.
예컨대 좋은 소프트웨어 설계의 원칙으로 자주 언급되는 것이 “유효하지 않은 상태를 표현할 수 없게 만들어라”이다. 이는 보통 두 가지를 의미한다.
profiles 테이블의 user_id로 연결된다면, 불일치가 생길 수 있으니 users 테이블에 profile_id를 또 두지 말라는 식이다.사람들이 이 원칙을 좋아하는 이유를 나는 이해한다. 소프트웨어를 도메인 모델에 가깝게 제약할수록 사고하기가 쉬워진다. 하지만 지나치게 밀어붙일 수도 있다. 내 생각에 소프트웨어에는 가능한 한 ‘강한’ 제약을 최소한으로 두어야 한다. 현실 세계의 소프트웨어는 이미 현실 세계의 진짜 강제 조건들에 종속되어 있다. 여기에 소프트웨어를 더 단정하게 보이게 하려는 이유로 추가 제약을 덧붙이면, 정말 정말 바꿔야 할 때 바꾸기 어려워질 위험이 있다. 그렇기에 좋은 소프트웨어 설계는 시스템이 일부 ‘유효하지 않은 상태’를 표현할 수 있도록 허용해야 한다.
예를 들어 많은 복잡한 소프트웨어 프로세스를 “상태 머신”으로 표현하라는 조언이 인기다. 즉, 즉흥적인(ad-hoc) 코드를 쓰는 대신 시스템이 놓일 수 있는 다양한 상태에 이름을 붙이고, 상태 간에 어떤 전이가 가능한지 그래프로 정의한다. 그 그래프의 간선이 시스템의 ‘액션’이 된다.
예시를 들어보자. 앱 마켓플레이스를 운영한다면 “draft(초안)”, “pending review(검수 대기)”, “approved(승인)”, “published(게시됨)” 같은 상태 집합을 정의할 수 있다. 이 상태들을 연결하는 액션은 “submit(제출)”, “approve(승인)”, “reject(거절)”, “publish(게시)”, “hide(숨기기)”가 될 수 있다.
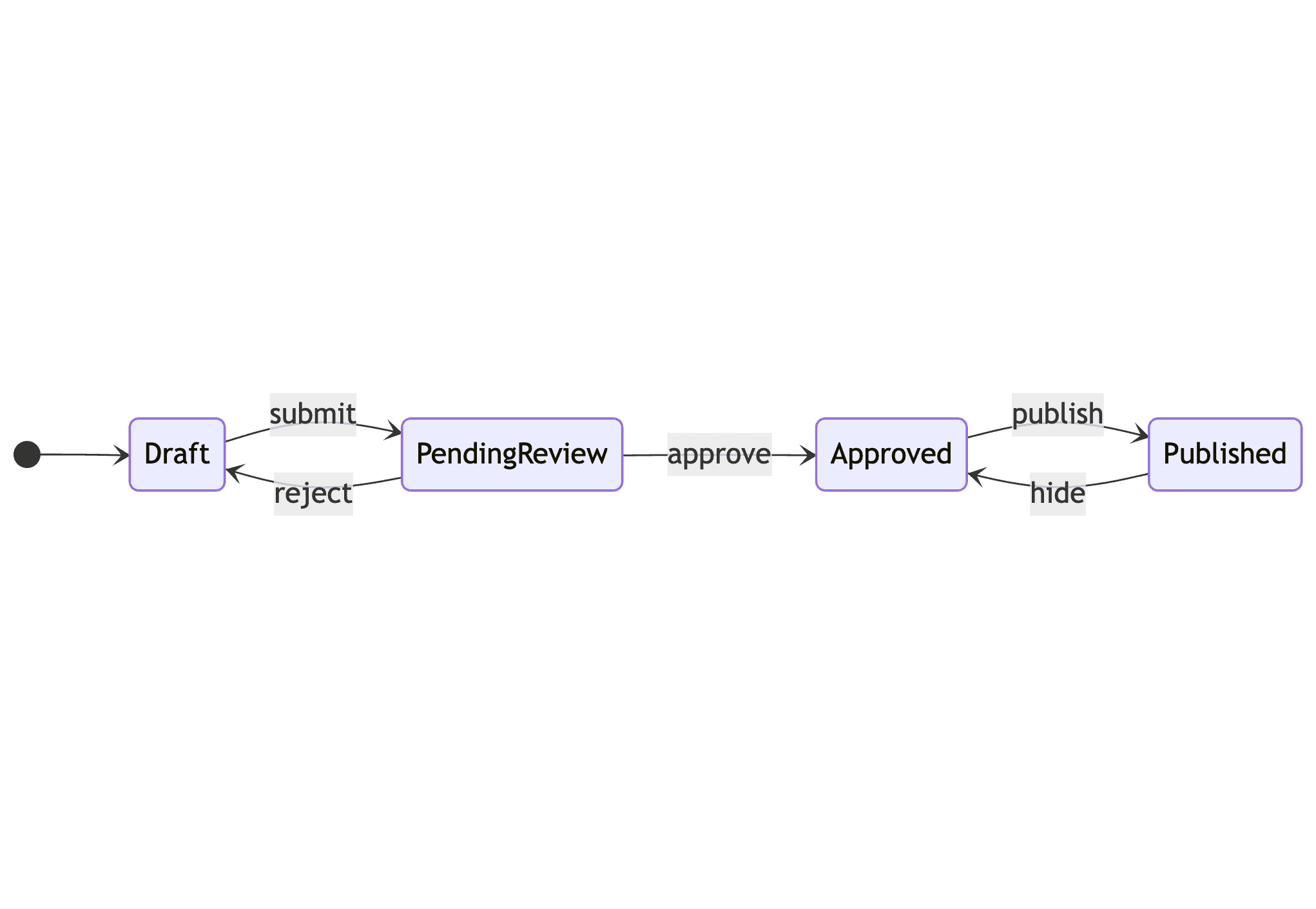
여기서 초안 앱만 제출할 수 있고, 검수 대기 앱만 거절할 수 있으며, 게시된 앱만 숨길 수 있고, … 같은 제약이 있다. 이런 제약 자체가 상태 머신을 쓰는 요점이다. 많은 앱 상태가 서로 독립적으로 뒤섞여 바뀔 수 있는 대신, 네 가지 가능한 상태와 다섯 가지 가능한 액션만 있으면 된다. 이 덕분에 시스템을 훨씬 쉽게 추론할 수 있다.
문제는 물론 엣지 케이스(예외 상황)다. 사내에서 개발되어 일반적인 검수 과정을 거치지 않아도 되는 “공식” 앱을 처리해야 하면 어떻게 할까? 핵심 파트너의 앱이 실수로 거절되었는데, 파트너에게 재제출을 강요하지 않고 엔지니어링 팀이 “거절을 되돌려” 달라는 요청을 받으면? 한 번 숨긴 게시 앱을 다시는 게시할 수 없게 숨겨야 하는 경우는?
상태 머신에서 예외를 다루는 방법은 두 가지다. 첫째, 설계를 업데이트한다. 예를 들어 검수 없이 곧바로 “published”로 갈 수 있는 “official” 상태를 추가하거나, 앱을 “draft”에서 곧장 “approved”로 보내는 “manually-approved” 액션을 추가하거나, “published”에서 다시 “draft”로 되돌리는 “hide-and-reject” 액션을 추가할 수 있다. 하지만 이렇게 하면 설계가 엄청나게 복잡해질 수 있다.
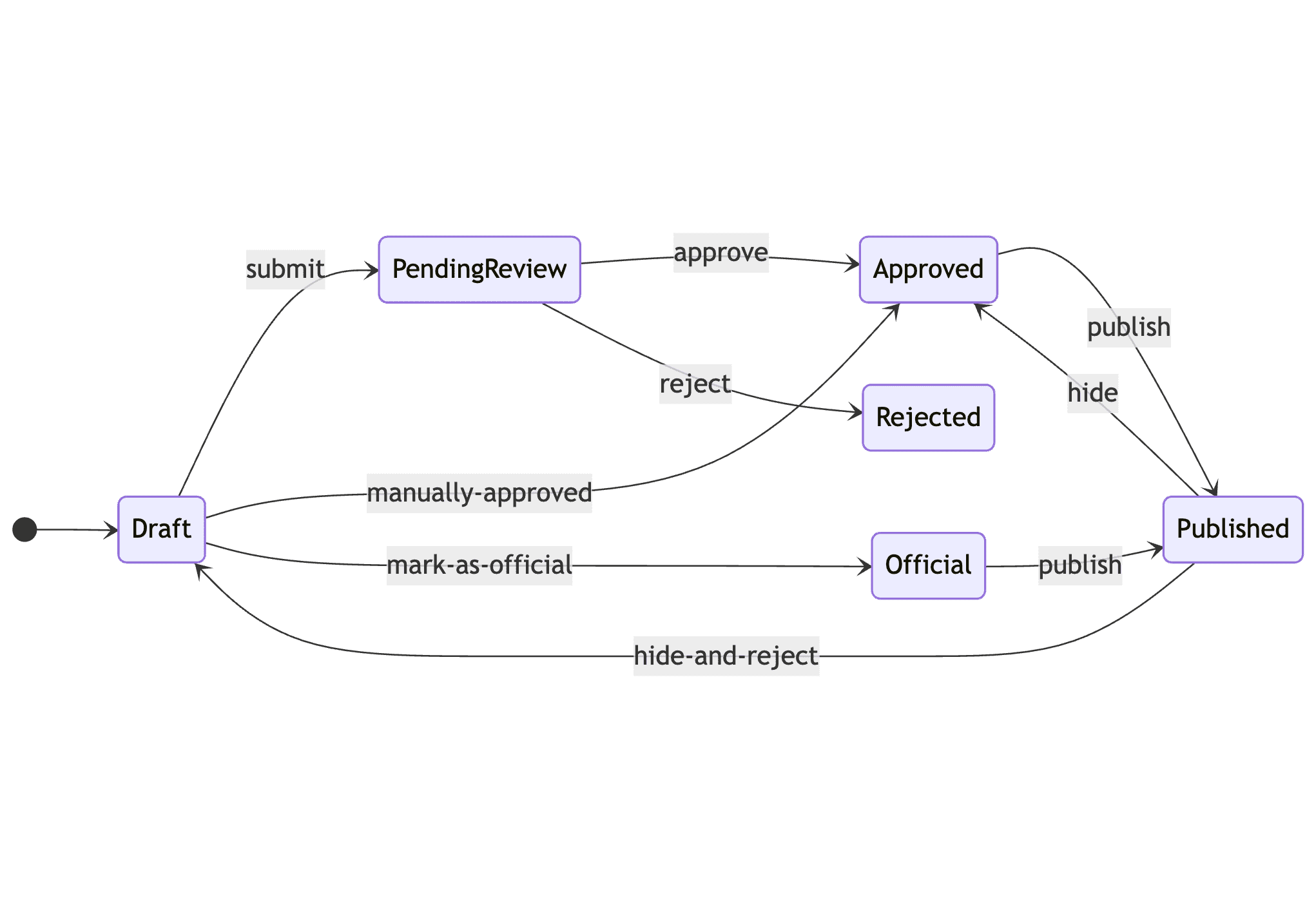
둘째 방법은 임의의 상태 전이를 허용하는 것이다. 즉, 상태 머신이 미리 정의된 액션을 통해서만 전이해야 한다는 제약을 완화하는 것이다. 이것은 예외를 허용하는 대가로 핵심 설계를 단순하게 유지해 준다.
거의 모든 경우에는 설계를 업데이트해야 한다(예컨대 앱 마켓플레이스라면 “hide-and-reject” 액션이 필요하다). 하지만 일부 임의 전이를 허용할 만큼은 유연하게 남겨 두어야 한다. 고객 대상 서비스를 운영하는 어떤 엔지니어링 팀도 항상 임의의 일회성 작업을 요청받는다. 그때마다 소프트웨어를 재설계해 허용하려 들면, 결국 지저분하게 얽히고 만다1. 그러니 기술적 제약을 절대적인 것으로 만들어서는 안 된다.
또 다른 고전적 예가 외래 키 제약이다. 관계형 데이터베이스에서는 테이블이 기본 키(보통 ID)로 관계를 맺는다. 예컨대 posts 테이블에는 어떤 사용자가 어떤 게시물을 소유하는지를 나타내기 위해 user_id 열이 있고, 이는 users 테이블의 id 열 값과 대응한다. 사용자 3의 게시물을 가져오고 싶다면 SELECT * FROM posts WHERE user_id = 3 같은 SQL을 실행한다.
외래 키 제약은 user_id가 users 테이블의 실제 행을 가리키도록 강제한다. 만약 user_id가 999인 게시물을 생성하거나 업데이트하려 하는데 해당 id의 사용자가 없다면, 외래 키 제약 때문에 SQL 쿼리가 실패한다.
겉으로는 훌륭해 보인다. 존재하지 않는 사용자를 가리키는 레코드는 유효하지 않은 상태다. 유효하지 않은 상태를 아예 표현 불가능하게 만드는 게 좋지 않을까? 하지만 GitHub과 Zendesk, 그리고 많은 대형 기술 기업들은 의도적으로 외래 키 제약을 쓰지 않는다. 왜일까?
주된 이유는 유연성이다2. 현실에서는 (사용자 없이 남은 게시물 같은) 일부 불법 상태를 애플리케이션 로직에서 처리하는 일이, 제약을 다루는 것보다 훨씬 쉽다. 외래 키 제약이 있으면 부모 레코드를 지울 때 항상 관련 레코드를 지워야 한다(주: ON DELETE SET NULL이 가능한 건 안다. 하지만 그건 해당 필드가 NULL 가능할 때만 되며, 그 자체가 도메인 모델에서는 유효하지 않은 상태일 수도 있다). 사용자와 게시물에서는 괜찮을 수도 있지만—그리고 매우 비싼 작업이 될 수도 있지만—관계가 덜 견고한 경우는 어떨까? 게시물에 reviewer_id가 있는데 그 리뷰어 계정이 삭제되면? 게시물을 지우는 건 분명 이상하다. 이런 식의 문제가 계속된다.
데이터베이스 스키마를 변경하고 싶을 때도 외래 키 제약은 큰 문제다. 테이블을 다른 데이터베이스 클러스터나 샤드로 옮기고 싶을 수 있다. 해당 테이블이 다른 테이블과 외래 키 관계를 맺고 있다면, 조심해야 한다! 그 테이블들을 함께 옮기지 않는다면, 어차피 외래 키 제약을 제거해야 한다. 설령 함께 옮긴다 해도, 제약을 준수하는 방식으로 데이터를 옮기는 일은 엄청 번거롭다. 단일 테이블만 따로따로 복제할 수 없고, 외래 키 관계를 보존하는 덩어리로 데이터를 옮겨야 하기 때문이다.
여기서의 원칙은 상태 머신과 같다. 언젠가는 당신이 그 깔끔한 제약을 위반할 수밖에 없는 일을 해야 하며, 그 제약을 정말로 움직일 수 없게 만들어 놓았다면 스스로 큰 골칫거리를 떠안게 된다.
세 번째 예로 Protocol Buffers(프로토버퍼)를 보자. 프로토버퍼는 구글의 인기 있는 오픈소스 직렬화 포맷이다. 1세대 프로토버퍼에서는 필드를 required로 표시할 수 있었다. 클라이언트가 프로토버퍼를 파싱할 때 required 필드가 빠져 있으면 메시지를 거부한다. 그럴듯하지 않은가? 어떤 종류의 메시지는 특정 값 없이는 의미가 없으니, 그 제약을 직렬화 계층에 인코딩하는 것이 좋지 않을까? 유효하지 않은 메시지를 아예 표현 불가능하게 만드는 게 좋지 않을까?
하지만 2세대에서는 어떤 필드도 required로 표시할 수 있는 능력을 없앴다. 꽤 논쟁적인 결정이었다. 실제로 모든 proto 필드는 항상 required여야 한다고 믿는 이들도 있다. 제약이 많을수록 타입이 더 우아하고 이해하기 쉬워진다는 주장이다. 반대편 관점은 프로토버퍼 설계자의 이 Hacker News 댓글을 참고하라.
내가 보기엔, 이 논쟁은 “여러 소비자가 있는 시스템에서 스키마를 변경하는 문제”를 얼마나 진지하게 보느냐에 달려 있다. 프로토버퍼에 required 필드를 새로 추가하려면 다음 순서로 해야 한다.
이 순서를 어기면 메시지가 중간에 떨어져 나가며, 대개 운영 중 장애로 이어진다. required 필드를 제거하는 경우도 비슷한 순서 의존 절차가 필요하지만, 역순이다. 소비자가 먼저 필드를 버리고, 그 다음 중간자, 마지막으로 생산자가 변경해야 한다. 소비자 서비스의 스키마 업데이트를 깜박하면(수천 개의 반쯤 잊힌 서비스가 있는 큰 회사에선 그리 드문 일도 아니다) 해당 서비스의 프로토버퍼를 필요로 하는 부분이 그냥 멈춰 버린다.
반면 모든 필드가 선택적임을 전제로 하면, 프로토버퍼 스키마를 순서와 무관하게 바꿀 수 있다. 모든 서비스가 각자의 일정에 맞춰 새 스키마로 업그레이드할 수 있다. 대가는, 생산자와 소비자 모두가 새 스키마로 업그레이드되기 전까지는 데이터를 갖지 못할 수 있으므로, 그 경우를 애플리케이션 코드에서 처리해야 한다는 점이다.
보시다시피, 나는 이 문제에서 프로토버퍼 쪽 입장이다. 여러 형태의 스키마 변경을 많이 겪어 본 입장에서, 올바른 순서로 서비스를 업그레이드하지 않으면 장애를 감수해야 하는 상황보다, 스키마 업그레이드 동안 애플리케이션 수준에서 불완전한 데이터를 용인하는 편이 더 안전하다고 생각한다. 다시 말해 애플리케이션 코드는 도메인 모델을 위반하는 데이터도 기꺼이 견딜 수 있어야 한다.
제약이 강할수록 위험하다. 여기서 강한 제약이란, 필요할 때 이를 되돌리기가 매우 어려운 것을 뜻한다. 어떤 것을 검증하는 코드 한 줄은 약한 제약이다. 필요하면 그 줄을 지우면 되기 때문이다. 반면 데이터베이스 스키마에 새겨 넣는 것은 더 강한 제약이다. 변경하려면 마이그레이션이 필요한데, (데이터 양과 읽기 트래픽에 따라) 운영상 매우 어렵기 때문이다. 어떤 제약은 시스템 전체의 아키텍처에 새겨져 있기도 하다. 블록체인이나 원장(ledger) 기반 시스템의 “데이터는 결코 진정으로 삭제되지 않는다” 같은 제약을 생각해 보라3.
대부분의 소프트웨어에서 도메인 모델은 현실 그 자체가 아니다. 도메인 모델은 현실 세계 프로세스의 ‘모델’일 뿐이다. 그렇기에 도메인 모델에 내재한 제약(예: “티켓은 아카이브되기 전에 반드시 완료로 표시되어야 한다”)은 진정한 의미의 강한 제약일 수 없다. 이는 대부분의 업무용 혹은 SaaS 소프트웨어에서 자명하며, 소프트웨어가 더 범용적이고 라이브러리 같아질수록 덜 자명해진다. 효율적인 행렬 곱셈 라이브러리를 작성한다면 사용자와 직접 맞닿는 코드를 쓸 때보다 훨씬 더 강한 제약을 둬도 된다. 자세한 내용은 내 글 Pure and impure software engineering을 보라.
모든 제약이 나쁘다고 주장하는 것은 아니다. 제약은 시스템을 추론 가능하게 만들고, 제약이 강할수록 그 역할을 더 잘한다. 제약이 전혀 없거나(혹은 아주 약한 제약만 있는) 시스템은 프로그램이라기보다 프로그래밍 언어에 가깝다. 나는 많은 종류의 강한 제약을 좋아한다. 예컨대 JSON보다 프로토버퍼를 선호하고, 타입 시그니처를 좋아하며, 스키마가 정해진 관계형 데이터베이스를 스키마리스 데이터베이스보다 훨씬 선호한다. 하지만 사용자 대상 소프트웨어는 그 소프트웨어의 ‘현실 세계의 목표’를 더 잘 달성하기 위해 결국 많은 제약을 어겨야 하는 상황에 놓이게 된다. 그러므로 일부 유효하지 않은 상태는 표현 가능해야 한다.
편집: 이메일 구독자 여러분께 사과드립니다. 이메일로 발송된 버전은 제목에 오타가 있었습니다(“unrepresentable” 대신 “representable”로 나갔습니다).
편집: 이 글은 Hacker News에서도 몇 가지 댓글을 받았습니다. 몇몇 댓글이 데이터베이스 스키마나 전송 포맷이 도메인 모델을 표현하는 방법의 일부가 아니라고 본다는 점이 놀라웠습니다. 내게는 그런 것들 역시 나머지 코드만큼이나 관련성이 큽니다. 나는 프레드 브룩스의 《맨먼스 미신》에 나오는 이 인용구가 좋다. “플로차트를 보여 주고 테이블을 숨긴다면 나는 계속 혼란스러울 것이다. 테이블을 보여 준다면 플로차트는 보통 필요 없다; 자명할 것이다.”
편집: 이 글은 lobste.rs에서도 훌륭한 댓글을 받았다.
↩ 2. 외래 키 제약은 규모가 커질수록 성능 문제를 일으키고, 외래 키 열을 건드리는 마이그레이션을 매우 어렵게 만들며, 소프트 삭제 같은 대기업의 흔한 패턴을 복잡하게 만든다.
↩ 3. 블록체인에서 진정한 데이터 삭제(예: GDPR 준수)를 가능하게 하려면 무엇이 필요할까? 카프카가 ‘진짜 삭제’를 처리하는 방식처럼 프로토콜을 바꿔야 할 것이다. 원장에 “묘비(tombstone)” 레코드를 기록하고, 모든 노드가 이를 안전하게 압축(compact)해 없애도록 허용하는 식으로 말이다. “제로 트러스트 환경에서 머클 트리의 일부를 안전하게 압축하려면?”은 독자에게 남겨 둔다.
이 글이 마음에 드셨다면, 내 새 글 소식을 이메일로 구독하시거나, Hacker News에 공유해 보시길.
2025년 9월 8일│ 태그: software design