Scala 3 컨텍스트 함수를 활용해 Reader/Writer/State/Abort 기능을 직접 스타일로 제공하는 경량 라이브러리 PureLogic의 동기, 사용법, 내부 구현, 성능, 적용 범위를 소개한다.
PureLogic를 방금 공개했습니다. 직접 스타일을 사용해 순수한 도메인 로직을 작성할 수 있는 새로운 오픈 소스 Scala 마이크로 라이브러리입니다. 이 글에서는 그 배경 동기와 동작 방식을 설명하겠습니다.
잘 알려진 소프트웨어 아키텍처 원칙(때로는 Functional Core, Imperative Shell로 불림)은 순수한 도메인 로직을 부수 효과로부터 분리하는 것입니다. 핵심 도메인 규칙(검증, 계산, 상태 전이)은 I/O를 수행하거나, 데이터베이스에 접근하거나, 외부 서비스를 호출하지 않고 입력을 받아 출력을 반환하는 순수 함수여야 합니다. 부수 효과는 애플리케이션의 경계로 밀어냅니다(제가 쓴 The Tri-Z Architecture 글 참고).
이 분리는 실질적인 이점이 있습니다. 순수 함수는 테스트가 아주 쉽습니다. 목(mock)도, 테스트 컨테이너도 필요 없고, 입력과 출력만 있으면 됩니다. 또한 외부 세계와의 숨은 상호작용이 없으니 추론하기가 쉽습니다. 그리고 다양한 맥락에서 재사용할 수 있습니다. 같은 검증 로직이 HTTP 핸들러에서 호출되든, CLI 도구에서 호출되든, 배치 작업에서 호출되든 그대로 동작합니다.
물론 모든 애플리케이션이 이 모델에 완벽히 들어맞는 것은 아닙니다. 도메인 로직이 본질적으로 I/O와 뒤섞여 있는 경우(프록시, 스트리밍 파이프라인)에는 얻을 것이 적습니다. 하지만 도메인 규칙이 풍부한 애플리케이션(금융 시스템, 게임, 이커머스)에서는 이런 분리가 빠르게 효과를 발휘합니다.
관심 있는 분들을 위해, 저는 이 주제를 Scala Matsuri 2022 (“Beautiful Domain Logic”)와 Lambda Days 2025 (“Anatomy of a Scala Game Server”)에서 했던 두 번의 발표에서 다룬 적이 있습니다.
Scala에서 이 순수 코어를 작성할 때는 보통 몇 가지 공통 패턴이 필요합니다:
Scala에서의 전통적인 함수형 접근은 ReaderWriterStateT나 ZPure 같은 모나드, 또는 이런 패턴을 다루기 위한 cats-mtl 같은 타입클래스를 사용합니다. 잘 동작하지만, 트레이드오프가 따릅니다.
모든 효과 연산은 flatMap이나 for-comprehension으로 순서를 연결해야 합니다. 리스트를 순회하면서 효과를 수행하려고 foreach를 그냥 쓸 수 없고 traverse가 필요합니다. 컴파일러가 모나드 트랜스포머 스택을 해석하려면 명시적인 타입 애너테이션이 필요한 경우가 많습니다. 그리고 새 팀원이 기여하려면 방대한 추상화 생태계를 먼저 배워야 합니다. 제가 ZPure를 좋아하는 이유 중 하나는 다른 선택지보다 마찰을 조금 줄여주기 때문이지만, 그래도 모든 코드는 여전히 for-comprehension이나 flatMap 체인 안에 있어야 합니다.
성능 비용도 있습니다. 모나딕 코드는 모든 연산을 데이터 구조로 감싸고 flatMap을 통해 체이닝하는데, 이는 매 단계 힙 할당을 의미합니다. 스택 트레이스가 flatMap과 map 프레임으로 가득 차서 디버깅이 고통스러워집니다. 프로파일러는 도메인 로직보다 효과 런타임의 내부를 보여줍니다.
이 오버헤드는 단지 경험담 수준이라고 치부되기도 합니다. 어떤 경우에는 그럴 수도 있지만, 저는 게임 서버에서 일하고 있고 도메인 로직이 충분히 복잡해서 전체 할당의 63%가 그로부터 나옵니다. 서버를 프로파일링했을 때 ZPure가 그 할당의 큰 부분을 차지하는 것으로 나타났습니다:
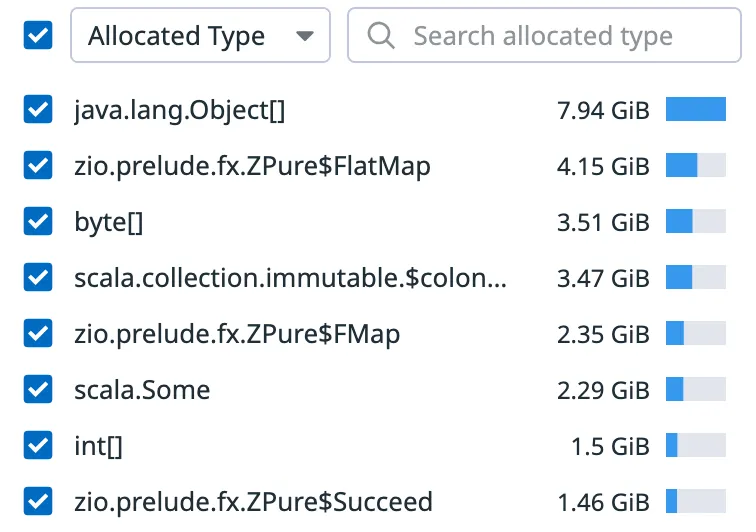
ZPure$FlatMap, ZPure$FMap, ZPure$Succeed는 flatMap, map, succeed 같은 기본 콤비네이터를 사용할 때 생성되는 모나딕 래퍼입니다. 빡빡한 도메인 로직 루프에서는 이 비용이 빠르게 누적됩니다. 이것이 PureLogic을 만든 주요 동기 중 하나였습니다.
PureLogic은 다른 접근을 취합니다. 모나드 대신 Scala 3의 컨텍스트 함수를 사용해 4가지 기능을 제공합니다: Reader, Writer, State, Abort. 이것들은 given/using을 통해 암묵적으로 전달되므로, 코드는 직접 스타일을 유지합니다: 일반적인 제어 흐름을 가진 평범한 Scala 코드입니다.
간단한 예시는 다음과 같습니다:
import purelogic.*
case class Account(balance: Int)
case class Config(price: Int)
def buy(quantity: Int) =
Logic.run(state = Account(50), reader = Config(10)) {
val price = read(_.price) * quantity
val balance = get(_.balance)
if (balance < price) fail("Insufficient balance")
set(Account(balance - price))
write("Purchase successful")
}
buy(2) // (Vector(Purchase successful),Right((Account(30),())))
buy(10) // (Vector(),Left(Insufficient balance))
이를 분해해 보면:
read(_.price)는 Config 객체에 접근해 price 필드를 추출합니다get(_.balance)는 Account 상태에 접근해 balance를 추출합니다fail(...)은 에러로 계산을 즉시 중단(쇼트서킷)합니다set(...)은 Account 상태를 갱신합니다write(...)는 로그 항목을 누적합니다for-comprehension도 없고, flatMap도 없고, yield도 없습니다. 그냥 val, if, 함수 호출뿐입니다. 기능은 Logic.run이 제공하고 블록 내부 어디에서나 사용할 수 있습니다.
차이를 더 명확히 보기 위해, 같은 로직을 ZIO Prelude의 ZPure로 쓴 경우와 PureLogic으로 쓴 경우를 비교해 봅시다:
// Monadic style (ZPure)
ZPure
.foreachDiscard(0 until n) { _ =>
for {
r <- ZPure.service[Int, Int]
s <- ZPure.get[Int]
next = s + r + 1
_ <- ZPure.set(next)
_ <- ZPure.log(next)
} yield ()
}
.flatMap(_ => ZPure.get[Int])
// Direct style (PureLogic)
(0 until n).foreach { _ =>
val next = get + read + 1
set(next)
write(next)
}
get
직접 스타일 버전은 더 짧고 표준 Scala 구성 요소를 사용합니다. 일반 foreach가 동작하므로 foreachDiscard가 필요 없습니다. 루프와 마지막 get을 연결하기 위해 flatMap을 쓸 필요도 없습니다. 그냥 코드입니다.
이 단순함은 코드베이스가 커질수록 더 크게 누적됩니다:
traverse / sequence 불필요: 리스트를 순회하며 효과를 수행하고 싶나요? 그냥 foreach나 map을 쓰면 됩니다.알아두어야 할 트레이드오프가 두 가지 있습니다. 첫째, 직접 스타일은 참조 투명성을 잃는다는 뜻입니다. 기능을 사용하는 표현식은 마음대로 재정렬하거나 중복 제거할 수 없습니다. 제 개인적인 의견으로는 이런 종류의 순수 로직 코드에서는 실무적으로 큰 문제가 되지 않을 것입니다. 둘째, 모나딕 코드는 트램폴리닝을 공짜로 얻습니다(flatMap마다 재귀 대신 데이터 구조를 반환). 그래서 깊게 재귀하는 모나딕 프로그램은 스택 오버플로우가 나지 않습니다. 직접 스타일에서는 재귀 함수를 @tailrec로 만들거나 깊은 재귀를 피하도록 구조를 바꿔야 합니다.
각 기능은 호출 지점에서 암묵적 인스턴스를 제공받는 trait입니다.
State[S]는 get과 set 메서드를 가진 trait입니다. State(initialValue) { ... }를 호출하면 PureLogic은 그 블록에 스코프가 한정된 가변 변수를 만들고, 그 변수에 읽기/쓰기를 수행하는 State 인스턴스를 제공합니다. 외부에서 보면 함수는 순수합니다: 같은 입력이면 같은 출력이고, 관찰 가능한 부수 효과가 없습니다. 이는 Haskell의 ST 모나드와 같은 원리입니다.
Abort[E]는 Scala 3의 boundary/break 메커니즘을 사용하며, 이는 로컬 throw/catch로 컴파일됩니다. 그래서 중단(abort)은 매우 빠릅니다. 모나딕 접근처럼 매 단계 Either로 감쌀 필요가 없습니다. Either는 Abort 경계에서 딱 한 번만 생성됩니다.
Reader[R]는 단순히 값을 보관하고 암묵적으로 사용할 수 있게 합니다. Writer[W]는 값을 버퍼에 모읍니다.
해당 apply 메서드로 프로그램을 감싸 실행합니다:
// Individual capabilities
val result = Reader(config) { ... }
val (logs, result) = Writer { ... }
val (finalState, result) = State(initialState) { ... }
val result: Either[E, A] = Abort { ... }
// All 4 at once
val (logs, result) = Logic.run(state = initialState, reader = config) { ... }
이 래퍼들은 어떤 순서로든 중첩할 수 있으며, 중첩 순서가 반환 타입의 형태를 결정합니다. Logic.run은 4가지를 합리적인 기본 순서로 감싸는 편의 기능입니다.
JMH를 사용해 Reader + Writer + State + Error 기능을 제공하는 다른 Scala 라이브러리들과 PureLogic을 벤치마킹했습니다:
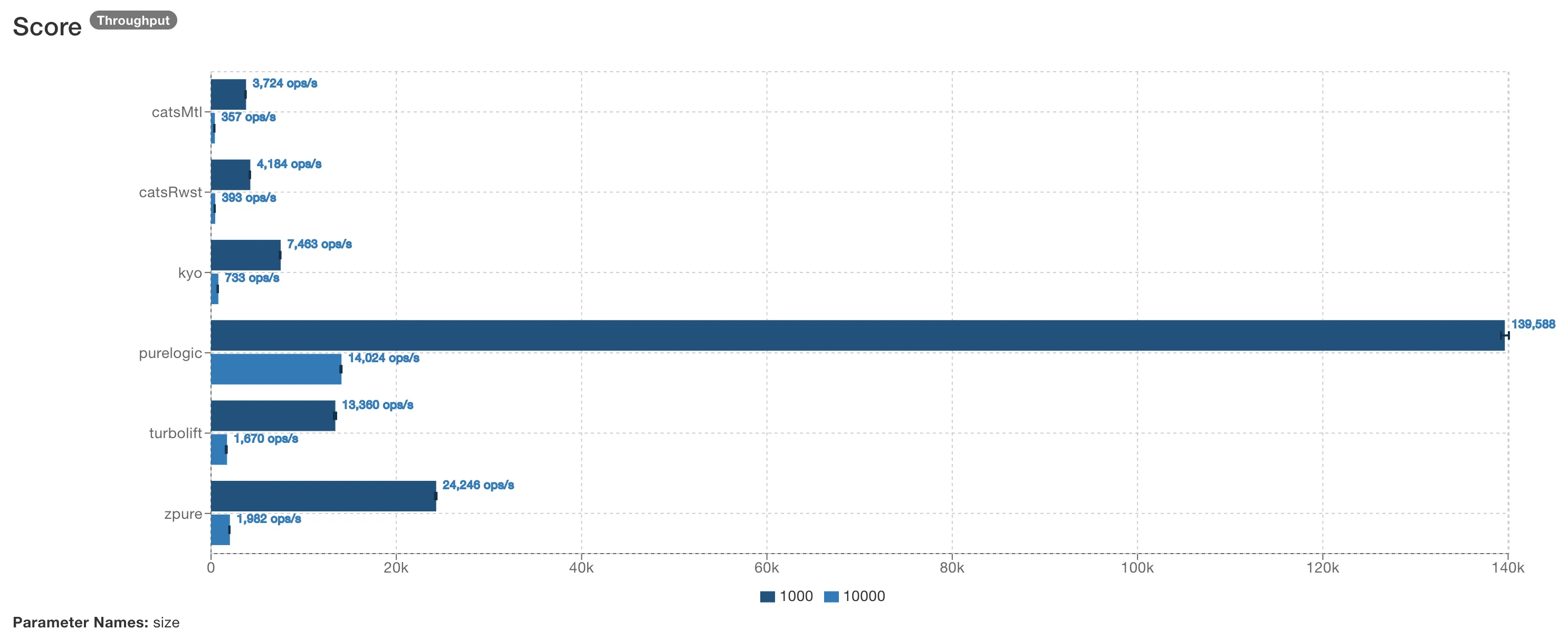
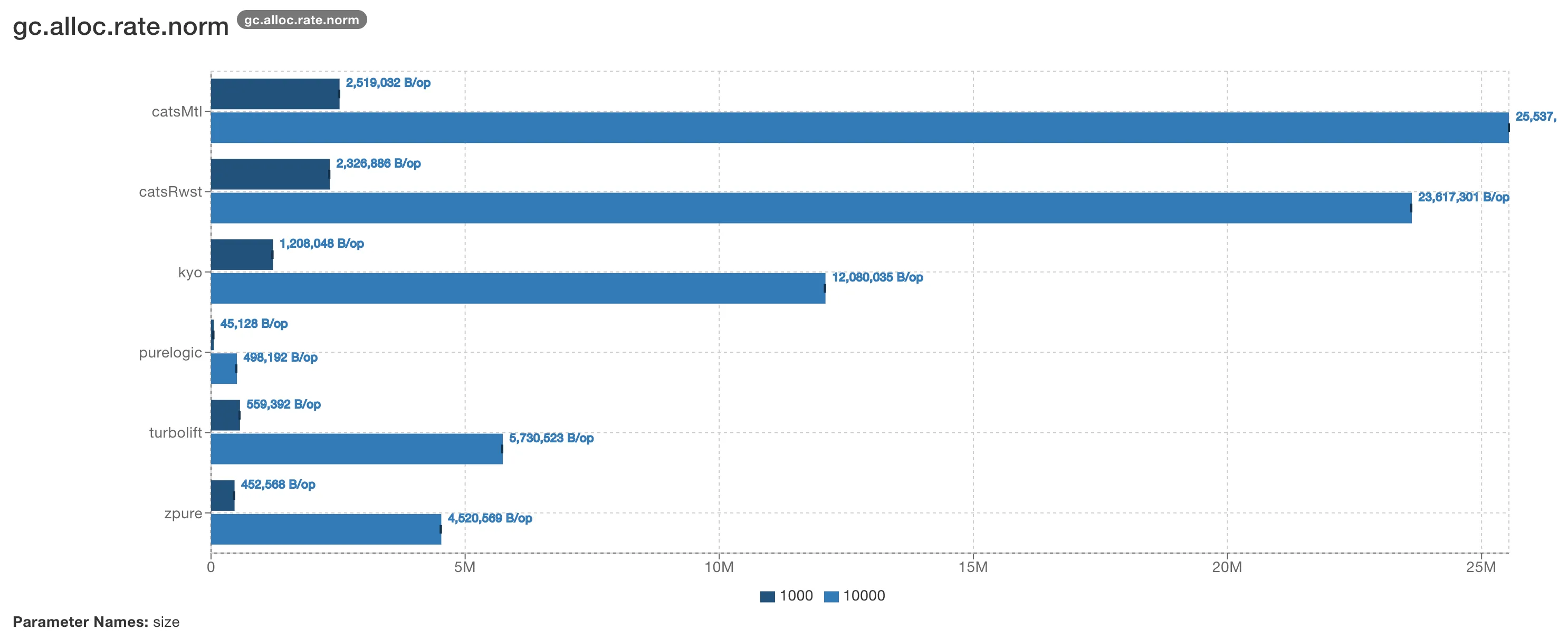 PureLogic은 라이브러리와 워크로드 크기에 따라 7-40배 더 빠르고, 10-50배 더 적은 메모리를 할당합니다. 이는 접근 방식의 직접적인 결과입니다. 할당할 모나딕 데이터 구조가 없고, 실행할
PureLogic은 라이브러리와 워크로드 크기에 따라 7-40배 더 빠르고, 10-50배 더 적은 메모리를 할당합니다. 이는 접근 방식의 직접적인 결과입니다. 할당할 모나딕 데이터 구조가 없고, 실행할 flatMap 체인도 없습니다.
또한 코드가 일반 Scala로 실행되기 때문에, 여러분의 함수들을 가리키는 의미 있는 스택 트레이스를 얻고, 시간이 실제로 어디에 쓰이는지 보여주는 정확한 프로파일링을 얻으며, 로직을 한 줄씩 따라가는 직관적인 디버깅이 가능합니다.
함수는 using 파라미터로 필요한 기능을 선언합니다:
def validateOrder(order: Order)(using Reader[Config], State[Cart], Abort[AppError]): Unit = {
val maxItems = read(_.maxItems)
val cart = get
if (cart.items.size > maxItems) fail(AppError.TooManyItems)
// ...
}
더 짧은 시그니처를 위해 컨텍스트 함수 문법을 사용할 수도 있습니다:
type MyProgram[A] = (Reader[Config], State[Cart], Abort[AppError]) ?=> A
def validateOrder(order: Order): MyProgram[Unit] = { ... }
기능은 자연스럽게 조합됩니다. 함수 A가 함수 B를 호출하고 둘 다 Reader[Config]가 필요하다면, 같은 인스턴스가 암묵적으로 전달됩니다. 파라미터를 수동으로 꿰어 넣을 필요가 없습니다. 또한 서로 다른 타입 파라미터를 가진 동일 종류의 기능을 여러 개 둘 수도 있으며(예: State[Account]와 State[Cart]), 컴파일러가 타입을 기반으로 이를 해석합니다.
각 기능에는 유용한 콤비네이터도 함께 제공됩니다. Reader에는 local(리더를 일시적으로 수정)과 focus(특정 하위 필드로 좁히기)가 있습니다. State에는 update, modify, localState(상태를 일시적으로 수정), focusState(상태의 일부에 대해 연산)가 있습니다. Abort에는 ensure, recover, 그리고 Option, Either, Try와의 통합이 있습니다. 전체 API는 문서를 참고하세요.
PureLogic은 애플리케이션의 순수 코어, 즉 I/O를 하지 않는 도메인 로직을 위해 설계되었습니다. ZIO나 Cats Effect 같은 이펙트 시스템을 대체하는 것이 아닙니다. 비동기 I/O, 동시성, 리소스 안전성을 관리하지 않습니다.
의도한 아키텍처는 다음과 같습니다:
경계에서 Logic.run을 호출해 평범한 값을 되돌려 받습니다. 어떤 스택과도 매끄럽게 통합됩니다. 연결할 것도 없고, 작성할 인터프리터도 없고, 설정할 런타임도 없습니다.
컨텍스트 함수와 기능에 기반한 PureLogic의 설계는 Scala의 향후 기능인 capture checking과 자연스럽게 잘 맞습니다. capture checking은 컴파일러가 기능이 자신의 스코프를 벗어나지 않는지 검증할 수 있게 해줍니다(예를 들어 State 참조가 Logic.run 바깥으로 유출되지 않도록 보장). PureLogic은 이를 염두에 두고 준비되어 있으며, capture checking이 Scala의 향후 버전에서 더 안정화되면 통합될 것입니다.
PureLogic은 의존성이 0개이며, Scala 3.3.x LTS 이상이 필요하고, JVM, Scala.js, Scala Native를 지원합니다.
libraryDependencies += "com.github.ghostdogpr" %% "purelogic" % "0.1.0"
문서와 예제를 확인해 시작해 보세요. 피드백과 기여도 환영합니다!