AI 에이전트의 장기적 성공률이 단순한 수학 모델로 설명될 수 있는지, 그리고 이 모델이 실제 데이터를 잘 설명하는지 살펴본다.
최근 Kwa 외(2025)의 실증 연구에 기반해, 필자는 그들이 다룬 연구-엔지니어링 과업 집합 내에서 AI 에이전트가 더 긴 기간의 과업에서 보이는 성능이 극히 단순한 수학적 모델—즉, 사람이 해당 과업을 수행하는 데 걸리는 각 분마다 일정 확률로 실패하는 모델—로 설명될 수 있음을 보여준다. 이는 과업 길이가 길어질수록 성공률이 지수적으로 감소함을 뜻하며, 각 에이전트는 자신만의 반감기(half-life)로 특징지을 수 있음을 의미한다. 이러한 경험적 규칙성을 바탕으로, 과업 길이에 따른 에이전트의 성공률을 추정할 수 있다. 또한 이 모델이 실제 데이터를 잘 설명한다는 점은, 장기 과업 실패의 근본 원인이 수많은 하위 과업 중 어느 하나라도 실패하면 전체가 실패하는 구조임을 시사한다. 이 모델이 다른 과업 집합에서도 일반적으로 적용되는지는 아직 밝혀지지 않았으며, 이는 향후 중요한 연구 주제이다.
METR 소속 Kwa 외(2025)의 최근 논문에서는 첨단 AI 에이전트가 해결할 수 있는 과업의 지속 시간에 지수적 경향이 있음을 발견했다. 즉, 약 7개월마다 해결 가능한 과업의 길이가 2배로 늘어난다.

이 주요 결과는 소프트웨어 엔지니어링, 사이버 보안, 일반 추론, 머신러닝 등 170개의 과업 묶음을 바탕으로 한다. 이 과업은 AI가 AI 연구에 도움을 줄 수 있는 작업을 대표할 수 있도록 세 가지 상이한 벤치마크에서 선별됐으며, 각 과업을 사람이 완료하는 데 걸리는 시간도 달랐다.

일반적으로 과업 기간이 늘어날수록 이를 수행하는 능력은 감소하기에, AI 에이전트가 서로 다른 길이의 과업에서 얼마나 성공했는지로 50% 성공률이 예상되는 과업 길이를 추정한다. 이후 이 길이가 프런티어 에이전트의 능력 향상과 함께 7개월마다 2배로 증가했음을 보였다. 인간이 같은 과업을 푸는 데 걸린 시간을 기준으로 과업 길이를 측정했다.
50% 성공률은 측정이 가장 용이해 주된 기준치로 삼았다. 물론 실용적인 활용을 위해선 80%, 99%, 99.9999%와 같이 훨씬 더 높은 성공률이 요구될 수 있다는 점도 인지하고 있다. 실험에서 80% 성공률도 측정했으며, 평균적으로 213일이 걸려(50% 성공률의 212일과 거의 같음, ±40일 오차) 두 성공률 임계점 모두에서 성공률 향상의 속도에 큰 차이가 없음을 발견했다.
하지만 50% 성공률에 해당하는 과업 길이와 80% 성공률에 해당하는 과업 길이에는 상당한 차이가 있다. 최고 성능의 모델(Claude 3.7 Sonnet)은 59분 이하의 과업에서 50% 성공률, 15분 이하에서는 80% 성공률이 가능했다. 만약 이런 결과가 다른 모델에도 일반화된다면, 80% 성공률 과업 길이는 50% 성공률에 비해 1/4에 그친다. 다시 말해, 지금은 50% 성공률로 가능한 과업이 14개월(즉, 두 번의 7개월 doubling) 후에는 80% 성공률로 가능해지는 셈이다.
이처럼 선택한 성공률 임계치에서 시간 수평선을 추적하며 AI 능력 향상 속도를 측정하는 아이디어는 새롭고 흥미롭다. AI 예측은 보통 성능 축(y축) 측정이 어렵다는 한계를 가진다. 하나의 특정 벤치마크 성능은 파악할 수 있지만, 이는 몇 년 내로 풀리는 경우가 많고, 다양한 벤치마크에 걸친 근본적 능력을 측정할 변인도 부족하다. METR의 이 측정법은 다양한 과업을 인간 기준 작업 시간이라는 공통 단위로 비교할 수 있게 해주며, 실제 발전 추세도 명확히 담아낸다.
비판할 지점도 있다. 특히 이런 결과가 이 과업 집합을 넘어서도 일반화될지는 미지수다. AI가 아직 해결 못하는 짧은 인간 과업(예: 단순 공간 추리, 직관적 물리) 또는 AI가 오히려 빨리 처리하는 작업(예: 기계적 수학 계산)도 있다. 즉, '인간 소요 시간'만으로 AI 능력을 전적으로 설명할 수 없다는 한계가 있다. Kwa 외도 이를 인지하고, 이 과업군이 실제 환경을 완전히 대변하지 않을 수 있는 여러 요인을 지적했다. 예를 들면:
본 에세이에서는 이 데이터를 '특정 과업 집합에서의 성능'으로 받아들이고, 그 배경에 깔린 메커니즘을 탐구해보려 한다.
이러한 결과는 무엇이 실제로 일어나고 있는지 설명을 요구한다. 예를 들어, 성공 확률이 높아질수록 시간 수평선(time horizon)은 어떻게 줄어들까? 에이전트가 8시간 과업은 가능한데 16시간 과업은 왜 안 되는 것일까? 결국 16시간 과업은 8시간 과업 두 번 연속 아닌가?
생존분석은 시간이 지남에 따라 실패 확률이 어떻게 변하는지 분석하는 분야다. 특정 시점에서 생존 확률 S(t), 즉, 그때까지 아직 실패하지 않았을 확률을 추적한다. 생존분석에서 가장 단순한 모델은 일정 위험률(constant hazard rate)이다. 즉, 지금까지 살아남았다면 다음 단계에서 실패할 확률이 항상 같다. 이 경우, 생존 곡선은 지수적으로 감소한다. 이 행동 양상은 방사성 붕괴와 똑같은데, 여기서도 아무리 시간이 지나도 언제나 동일 확률로 붕괴 발생 위험이 있어 생존율이 지수적으로 줄고, 반감기(half-life)로 주로 표현된다.
AI 에이전트의 성공률이 과업 기간에 따라 이처럼 감소한다면, Kwa 외가 제시한 각 에이전트의 50% 성공 기간은 곧 그 에이전트의 반감기인 셈이다. 방사성 동위원소의 반감기와 마찬가지로, 이는 단순히 중앙값이 아니라 아무 시점에서든 남은 생존 기간의 중앙값이기도 하다(오직 지수 곡선만이 이런 특성을 지님). 이 AI 반감기는 물리적 시간이 아니라 '인간이 과업을 수행하는 데 걸리는 시간' 기준으로 측정된다는 점만 다르다.
AI에 일정 위험률 모델이 적용될 수 있는 주요 이유는, 과업이 일련의 하위 단계(subtask)들을 성공적으로 넘어야만 완수되고, 과업이 길어질수록 이런 단계가 많아진다는 점에 있다. 좀 더 명확히 말하면, 과업이 같은 난도, 같은 길이의 작은 하위 과업 N개로 나뉠 수 있고 각 하위 과업마다 독립적으로 동일 실패 확률을 가진다면, 전체에서 한 번이라도 실패하면 전체가 실패이므로 성공률은 곱셈으로 계산돼 지수적 곡선이 된다(Pr(Task) = Pr(Subtask1) & Pr(Subtask2) & ... & Pr(SubtaskN)).
꼭 하위 과업 길이나 난도가 똑같을 필요는 없다. 이 모델은 과업을 어떻게 쪼개든, 총 길이 t의 하위 과업을 다 성공할 확률은 언제나 t길이 한번의 과업 성공 확률과 일치한다고 본다. 즉, 60분 과업을 한 번, 10분 × 6번, 20분 + 1분 × 40번 등 어떻게 보더라도, 결국은 전체 인간 기준 시간의 총합에 따라 성공률이 정해진다.
이 일정 위험률 모델은 80% 성공률 시간 수평선이 50% 성공률 시간 수평선의 약 1/3이 될 것임을 예측한다. 왜냐하면, 80% 성공률 구간을 3번 겹치면 0.8³ = 약 0.512 ≈ 50%이기 때문이다. 일반화하면, 성공 확률 p에 해당하는 시간 수평선은 ln(p)/ln(q) × q에 해당하는 시간 수평선 길이와 같다. 따라서 80% 시간 수평선은 ln(0.8)/ln(0.5) = 0.322배 50% 시간 수평선이 된다. Kwa 외는 Claude 3.7 Sonnet의 80% 시간 수평선이 실제로 0.25배라고 측정했으며, 이론치와 오차범위 내에서 일치했다. 다음 그래프가 이러한 관계와 지수 생존 곡선을 시각화한 것이다(T50 = 50% 시간 수평선 등).
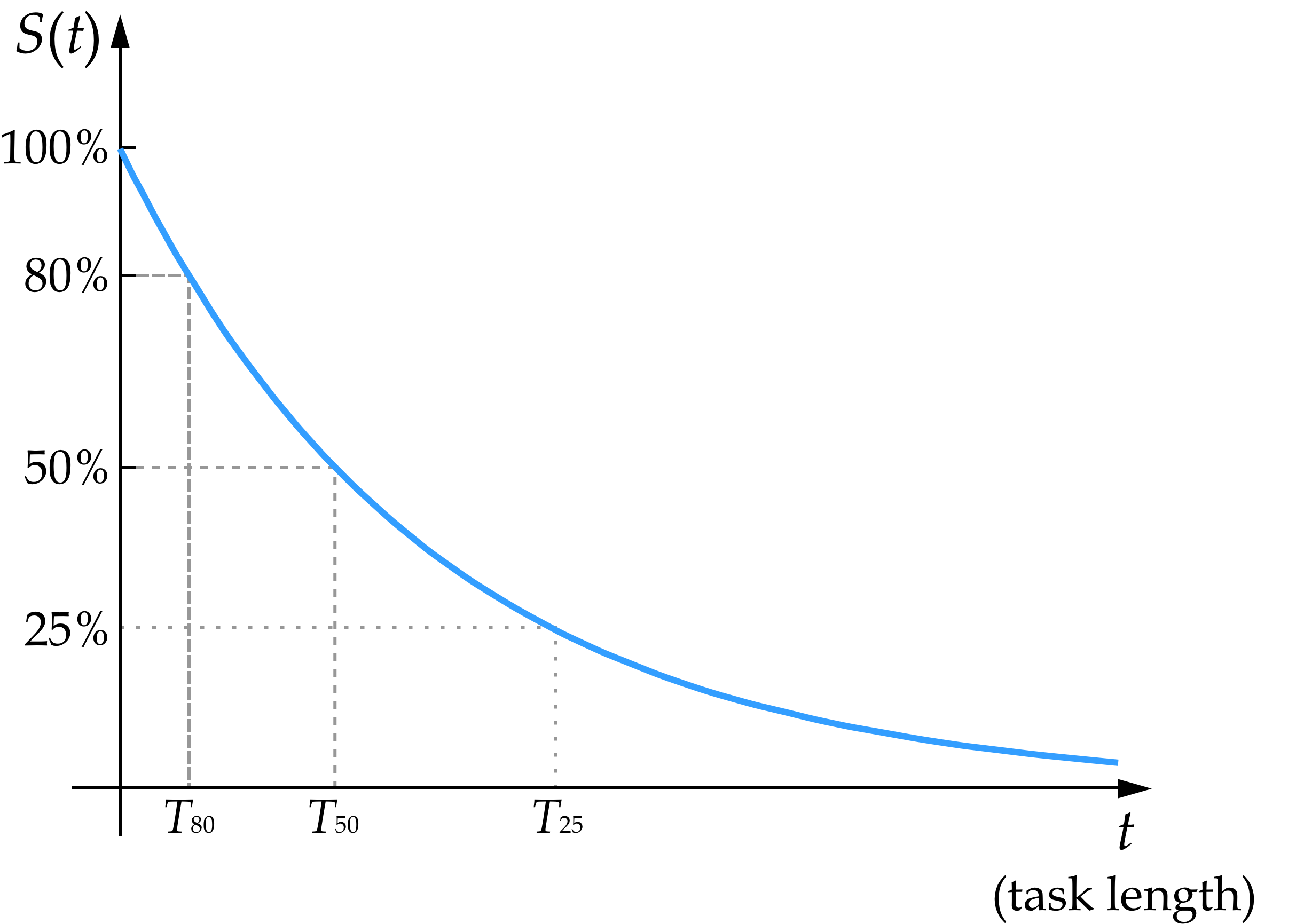
아래는 각 성공률 목표별 시간 수평선(T)과 50% 기준 시간 수평선(T50) 간의 관계 예시다:
또, 모델에 따르면 다음과 같은 기간 후에 더 높은 성공률 임계점도 같은 길이에 도달한다(성공률 50% 시간 수평선의 길이에 먼저 도달하는 후, 7개월 doubling 적용):
Kwa 외는 성공률과 시간 수평선의 관계형 함수도 피팅했다(아래는 해당 논문에서 수정한 그림). 시간 수평선을 로그 스케일로 표시하면 성공률이 시그모이드식 감소 곡선을 보인다(컬러 바). 논문은 이를 로지스틱 함수(검은 곡선)로 잘 적합시켰다고 언급한다. 그러나, 다른 함수와의 적합성을 직접 비교한 내용은 없다.

데이터는 지수함수로도 매우 잘 맞아떨어진다(로그 스케일 x축에서는 역시 시그모이드형처럼 보임). 위 그림의 점선 파란 곡선이 지수 함수 적합 결과다. 일부 모델(왼쪽 위 등)에서는 더 잘, 일부는 덜 맞지만 전체로 보면 대략 비슷하거나 더 간단하다(파라미터도 지수 모델은 1개, 로지스틱 모델은 2개). 참고로 논문에 사용된 검은 곡선은 진짜 단순 로지스틱이 아니라, 로그-로지스틱 분포여서 로그 스케일상에서만 시그모이드형을 띤다.
또한 논문은 _인간_의 장기 과업 성공률 곡선도 시각화했다:

흥미롭게도, 인간의 곡선은 상수 위험률(지수 예측)보다 성공률 하락 속도가 느리다. 예를 들어 1.5시간 시점에 대략 50% 성공률이었다면, 3시간엔 25%, 6시간엔 12.5%, 12시간엔 6.25%가 되어야 하지만, 실제로는 20% 이상을 유지했다.
이는 인간과 AI의 성공률-시간 수평선 스케일링 양상이 다름을 시사할 수 있다(예: 인간이 이전 하위 과업의 실패를 더 잘 보정?). 만약 인간과 AI의 과업 길이 scaling이 다르다면, 이는 현 AI 방식의 비효율성을 보여주는 중요한 결과가 될 수 있다. 추가 연구가 필요하다.
그 외, 또 다른 해석도 가능하다. 이 그래프가 여러 인간의 합계이기 때문에 생긴 현상일 수 있다. 즉, 개별 인간은 모두 상수 위험률을 가져 지수 곡선을 따른다고 해도, 위험률(즉, 반감기)이 제각각 다른 여러 인간을 합치면 여러 개 지수 함수의 가중합이 되고, 이는 더 느리게 (꼬리가 두꺼운) 감소곡선이 된다. (자세한 수식은 Ord(2023) 참고)
AI는 각 에이전트별로 별도 측정하니 위와 같은 혼합 효과가 없지만, 과업별로 본질적 난이도(위험률)가 다르면 AI도 aggregate 곡선상으론 꼬리가 두꺼워지는 비슷한 현상이 나타난다. 즉, 각 과업이 각자 지수 곡선을 가지면 전체는 가중평균이 되어 평균 위험률(감쇠 속도)이 느려진다. 이점은 위험률 기반 설명이 aggregate 전체엔 정확히 나타나지 않아도, 개별 과업 수준에선 분명히 적용될 수 있음을 시사한다. (역시 [Ord(2023)] 참고.)
만약 이 모델이 과업 성공률 감소의 주요 원인이라면, 다음과 같은 시사점이 있다:
AI가 분당 완전히 동일한 실패확률을 가진다고 주장하는 것이 아니라, 실질적으로 대략 그렇거나 확률적으로 그런 모습을 보인다는 것이다. 만약 시스템적으로 위험률이 시간에 따라 변하는 것이 데이터에서 분명히 나타난다면(예: 증가/감소 경향), 이는 위험률 기반 모델의 대안적 설명으로 기능할 수 있다.
또, 위험률 곡선이 무엇이든, 항상 k배만큼 낮추면 모든 성공률 임계치에서 시간 수평선도 k배 늘어난다(그래프가 수평확장됨). 즉, METR 측정 결과 각 성공률 임계마다 doubling 속도가 같다면, 이는 위험률이 동일하게 감소(즉, 7개월마다 반감)함을 의미한다.
지금까지의 논의와 데이터는 상수 위험률이 대략적으로 실재함을 시사할 뿐이다. 실제론 METR 데이터에 대해 지수함수와 로그-로지스틱 함수(논문 사용) 중 어느 쪽이 더 잘 맞는지 정량적 통계분석을 해볼 필요가 있다. 또한 인간 곡선과 AI 곡선을 robust하게 비교하여(예: 반감기 차이, 곡선 형태 차이 등), 실제 체계적 차이가 있는지 검증하는 것도 중요하다. 그리고 무엇보다 이 현상이 다른 과업군에도 적용되는지 후속 연구가 필요하다.
Thomas Kwa 외, Measuring AI Ability to Complete Long Tasks, arXiv:2503.14499 [cs.AI], 2025.
Toby Ord, The Lindy Effect. arXiv:2308.09045 [physics.soc-ph], 2023.