GraphQL 도입을 고민하는 팀을 위해 장점과 개발 경험의 이점, 그리고 3년 사용 경험에서 드러난 한계(타이핑, 에러 처리, 모니터링, 페이지네이션, 캐싱, N+1, 미디어 타입, 보안, 페더레이션/스티칭, 생태계 성숙도)를 REST와 비교하며 정리합니다.

읽는 데 15분
2023년 3월 21일
이미지를 전체 크기로 보려면 Enter 키를 누르거나 클릭하세요
Photo by Luca Bravo on Unsplash
프로젝트에서 GraphQL을 써야 할지 고민하고 있나요? “GraphQL은 미래다”와 “REST가 더 단순하다” 같은 주장으로 개발자들이 다투고 있나요? 팀에서 무수히 논쟁했던 내용을 여기에서 요약해 보겠습니다.
면책 고지: GraphQL은 유행이고, 그것이 얼마나 놀라운지에 대한 글을 셀 수 없이 많이 찾을 수 있습니다. 하지만 3년간 써본 뒤로 저는 이 기술에 약간은 씁쓸하고 실망했습니다. 그러니 제 말을 절대적인 진리로 받아들이진 마세요.
새로운 기술을 고려하기 전에 제가 스스로에게 던지는 첫 번째 질문은 “왜 이걸 써야 하지?”입니다.
GraphQL의 경우, 가장 좋은 답은 페이스북이 처음 겪었던 문제로 돌아가는 것입니다. 2015년 9월의 원문 글이 그 문제를 완벽히 설명합니다.
“2012년으로 거슬러 올라가, 우리는 Facebook의 네이티브 모바일 애플리케이션을 재구축하려는 노력을 시작했습니다. 당시 iOS와 Android 앱은 모바일 웹사이트 뷰를 감싼 얇은 래퍼에 불과했습니다. 이는 ‘한 번 작성하고 어디서나 실행한다’는 모바일 앱의 이상에 가까웠지만, 실제로는 우리의 모바일 웹뷰 앱을 한계를 넘어 밀어붙였습니다. Facebook의 모바일 앱이 복잡해지면서 성능이 나빠지고 자주 크래시가 발생했습니다. 네이티브로 구현된 모델과 뷰로 전환하면서, 우리는 처음으로 뉴스피드의 API 데이터 버전이 필요하다는 사실을 깨달았습니다 — 그전까진 HTML로만 전달됐거든요.
뉴스피드 데이터를 모바일 앱에 전달하는 옵션으로 RESTful 서버 리소스와 FQL 테이블(Facebook의 SQL 유사 API)을 평가했습니다. 우리는 우리가 앱에서 사용하고자 하는 데이터와, 서버 쿼리가 요구하는 데이터의 차이에 좌절했습니다. 우리는 데이터를 리소스 URL, 보조 키, 조인 테이블 관점으로 생각하지 않습니다; 우리는 객체의 그래프 관점으로 생각합니다.
페이스북은 특정 문제에 직면했고, 맞춤형 해결책인 GraphQL을 만들었습니다. 그래프 형태의 데이터를 노출하기 위해, 그들은 계층적 쿼리 언어를 설계했습니다. 즉, GraphQL은 객체 간의 관계를 자연스럽게 따라갑니다. 중첩 객체를 가질 수 있고, 하나의 네트워크 호출로 모두 반환할 수 있습니다.
그들은 데이터베이스가 아니라 프로토콜을 만들었습니다. 페이스북은 이미 스토리지를 보유하고 있었죠. 서버의 각 GraphQL 필드는 임의의 함수로 뒷받침되며, 비즈니스 로직을 스토리지로부터 분리합니다.
마지막으로, 전 세계에 사용자가 있고 셀룰러 데이터 요금제가 늘 저렴하지 않은 상황에서, GraphQL 프로토콜은 모바일 고객을 위해 “필요한 것만 전송”하도록 최적화되었습니다.
GraphQL이 페이스북의 문제를 어떻게 해결하는지는 이해하기 쉽습니다. 남은 질문은 “이게 여러분의 문제도 해결하나요?”입니다.
아주 틈새 문제를 해결함에도, GraphQL은 다음과 같은 장점 덕분에 개발자 커뮤니티의 많은 이들을 설득했습니다:
저는 이러한 세일즈 포인트를 충분히 이해했고, 기술 자체에도 꽤 열광적이었습니다.
모바일 팀은 회사 내에서 GraphQL의 강력한 옹호자였습니다. 데스크톱 프론트엔드 팀도 타입 아이디어를 좋아했습니다. 우리는 이미 REST API를 가지고 있었지만 2019년에 GraphQL을 도입했습니다. 팀은 GraphQL을 위한 새로운 엔드포인트 구축에 시간을 투자했습니다. 우리는 React.js, Kotlin, Swift 클라이언트를 제공하는 Apollo 라이브러리를 선택했습니다.
첫 번째 엔드포인트는 정말 손쉽게 설정되었습니다. Apollo 서버는 백엔드에서 express.js와 잘 맞으며, REST와 GraphQL 두 API 엔드포인트가 동일한 앱에서 공존할 수 있습니다.
“한 번의 요청으로 여러 리소스” 덕분에 프론트엔드 코드는 GraphQL로 훨씬 단순해졌습니다. 예를 들어, 사용자가 특정 아티스트의 상세 정보(이름, id, 트랙 등)를 얻고 싶다고 합시다. 전통적인 REST 패턴에서는 프론트엔드가 /artists와 /tracks 두 엔드포인트 사이를 오가며 요청하고, 그 결과를 병합해야 합니다. 그러나 GraphQL에서는 아래와 같이 쿼리에서 필요한 모든 데이터를 정의할 수 있습니다:
artists(id: "1") {
id
name
avatarUrl
tracks(limit: 2) {
name
urlSlug
}
} 첫 번째 엔드포인트가 잘 되자, 우리는 더 많은 엔드포인트를 추가하기 시작했고, 2020년에는 50개가 넘었습니다.
2년이 지나고 보니, GraphQL의 일부 이점이 우리 프로젝트에는 부가 가치를 주지 않는다는 걸 깨달았습니다.
앞서 언급했듯, 이 패턴의 주요 이점은 클라이언트 코드를 단순하게 만드는 것입니다. 하지만 일부 엔지니어들은 네트워크 호출을 최적화하고 앱의 로딩 속도를 높이기 위해 이를 사용하고 싶어 했습니다.
저는 이것이 유효한 최적화라고 생각하지 않습니다:
GraphQL은 클라이언트 앱의 필요에 따라 데이터를 선별적으로 선택함으로써 전송량을 최소화하는 것을 목표로 합니다. 작은 화면의 모바일 클라이언트는 더 큰 웹 앱 화면보다 적은 정보를 가져올 수 있죠. 고정된 데이터 구조를 반환하는 엔드포인트 대신, GraphQL 서버는 단일 엔드포인트만 노출하고 클라이언트가 요청한 데이터에 정확히 응답합니다.
저는 이 주장에 크게 공감하지 않습니다.
스포티파이 앨범 화면에서는 데스크톱에 세 가지 추가 필드(재생 수, 트랙 길이, 앨범 길이)만 있습니다(즉 JSON당 약 30바이트 절약). 아마존에서도 데스크톱 화면에는 두 개의 추가 데이터 필드만 있습니다. Spendesk 앱도 마찬가지여서 페이로드 크기를 최적화하는 데 이 기능의 실제 이점이 거의 없습니다.
정말 로딩 시간을 최적화하고 싶다면, 모바일에서 저화질 이미지를 내려받도록 하는 게 더 낫습니다. 하지만 뒤에서 보겠듯, GraphQL은 문서(바이너리)와는 궁합이 좋지 않습니다.
반대로, GraphQL은 클라이언트가 정확히 필요한 것을 얻기 위해 쿼리를 실행할 권한을 줍니다. 즉, 사용자는 원하는 만큼 많은 리소스에서 원하는 만큼 많은 필드를 요청할 수 있습니다. 쿼리는 잠재적으로 수천 개의 속성을 응답으로 반환하게 만들어 서버를 무릎 꿇릴 수 있습니다.
마이크로 최적화는 대체로 실수입니다. 밀리초나 몇 바이트를 아끼려고 아키텍처를 선택해선 안 됩니다.
수년 전 WSDL처럼, GraphQL은 API의 모든 타입, 커맨드, 쿼리를 graphql.schema 파일에 정의합니다. 저는 타입의 열렬한 팬입니다. 하지만 GraphQL의 타입 지정은 혼란스러울 수 있다는 걸 알게 됐습니다.
우선, 중복이 많습니다. GraphQL은 스키마에서 타입을 정의하지만, 우리는 백엔드(TypeScript + node.js)와 모바일 앱(Swift, Kotlin)에서도 유사한 타입을 다시 정의해야 했습니다.
이 문제를 해결하려고 다음 두 가지 솔루션이 등장했습니다:
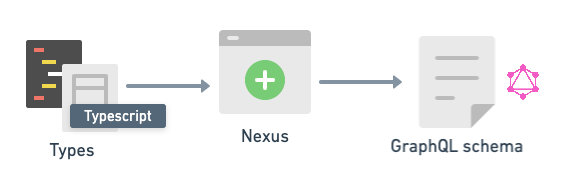
a. 코드 우선 타입 지정
첫 번째 솔루션(nexus, typegraphql 등)은 TypeScript에서 타입을 선언하고, 그 기반으로 GraphQL 스키마를 생성합니다.
이미지: 작성자 제공
우리 팀은 2020년에 nexus를 시도했다가 한 달 만에 접었습니다. 코드는 난해했고 우리가 타입 지정에 사용하던 zod.js와도 궁합이 좋지 않았습니다. 페더레이션 같은 기능을 지원하지 않았고 null 값도 제대로 동작하지 않았습니다. 생성된 GraphQL 스키마를 디버깅하는 것도 쉽지 않았습니다. 끔찍한 경험이었고 추천하지 않습니다.
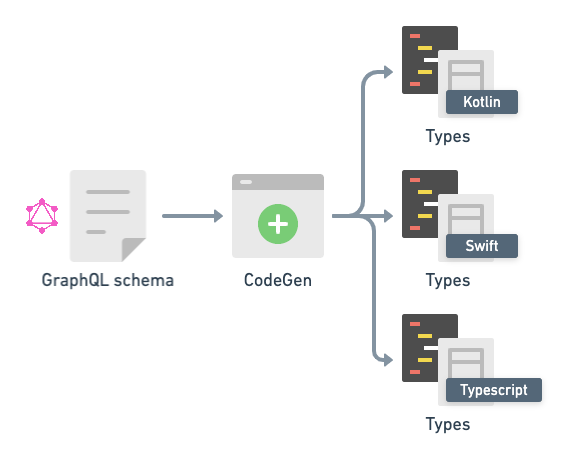
b. 스키마 우선 타입 지정
다른 솔루션은 반대입니다. Apollo(JS)나 Ariadne (Python), CodeGen이 이런 방식을 씁니다. 먼저 스키마를 만들고, 스크립트가 schema.graphql 파일을 바탕으로 타입을 생성합니다.
이미지: 작성자 제공
우리는 현재 Codegen을 사용해 TypeScript 타입을 자동 생성합니다. 확실히 경험이 더 좋지만, 여전히 완벽하진 않습니다. 프론트엔드와 백엔드 간 스키마를 공유해야 합니다. 프론트엔드는 스키마가 바뀔 때마다 다시 빌드해야 최신 변경을 반영합니다. 우리는 최신 스키마를 얻기 위해 인트로스펙션으로 스키마를 끌어옵니다.
TypeScript가 선택적(optional)로 이해하지 못하는 “nonnullable” 타입, TypeScript에는 없는 GraphQL의 enum, 그리고 복잡한 리졸버 반환 타입 등 여전히 문제가 있습니다.
GraphQL의 enum은 결국 다음과 같은 두 개의 TypeScript 타입이 됩니다:
enum FourEyesProcedureStatus {
VALIDATION_PENDING
CANCELLED
VALIDATED
REJECTED export type FourEyesProcedureStatus =
| 'CANCELLED'
| 'REJECTED'
| 'VALIDATED'
| 'VALIDATION_PENDING'; export type FourEyesStatusEnum =
| 'CANCELLED'
| 'REJECTED'
| 'VALIDATED'
| 'VALIDATION_PENDING';
리졸버를 위한 생성 타입은 복잡합니다. 문제는 중첩 객체에서 발생합니다. 리졸버는 전체 객체를 반환하지 않고, 일부만 반환한 뒤 다른 resolver가 나머지 필드를 채우도록 합니다.
이 작가의 최신 글을 받아보려면 Medium에 무료로 가입하세요.
정적 타입 언어는 이 패턴을 기본으로 지원하지 않습니다. TypeScript에서는 Codegen이 코드에 any를 넣고, 매우 복잡한 타입을 만들어냅니다.
blockAccount: async (_, args, context): Promise<any> => {}
export type BlockAccountResultResolvers<
ContextType = any,
ParentType extends ResolversParentTypes['BlockAccountResult'] = ResolversParentTypes['BlockAccountResult'],
= ResolversObject<{
account?: Resolver<ResolversTypes['AccountDetails'], ParentType, ContextType>;
__isTypeOf?: IsTypeOfResolverFn<ParentType, ContextType>;
}>; REST API에서는 내부 타입과 일부 외부 DTO만 정의합니다. 중복이 조금 있긴 하지만 GraphQL보다 훨씬 단순합니다.
우리가 GraphQL을 쓰기 시작했을 때, insomnia나 Postman 같은 제품은 GraphQL을 지원하지 않아 도구에 회의적이었습니다. 이제는 상황이 나아져 기본으로 모두 지원합니다.
아직도 마음에 걸리는 게 하나 있습니다. 디버깅이 더 어렵다는 점입니다. 두 웹사이트를 보세요. 하나는 GraphQL을 도처에 쓰고, 다른 하나는 REST 엔드포인트를 씁니다. 크롬 개발자 도구에서 모든 엔드포인트가 똑같이 보여서 찾고 있는 것을 찾기가 어렵습니다. REST에서는 URL만 봐도 어떤 데이터를 가져오는지 알 수 있습니다.
REST는 404 Not Found, 400 Bad Request 같은 HTTP 에러 코드를 활용할 수 있지만, GraphQL은 그렇지 않습니다. GraphQL은 응답 페이로드 안에 에러 메시지를 넣은 채 200 코드를 반환하도록 강제합니다. 어느 엔드포인트가 실패했는지 알기 위해 각 페이로드를 확인해야 합니다.
또한 어떤 객체는 찾을 수 없어서 비어 있을 수도 있고, 에러 때문에 비었을 수도 있습니다. 둘의 차이를 구분하기 어렵습니다.
이전 주제와 관련하여, HTTP 에러는 각자 에러 코드가 있어 모니터링이 매우 쉽지만 GraphQL은 그렇지 않습니다. 쉬운 해결책이 없습니다. Apollo가 이 문제를 해결하려 노력 중이며, 곧 해법이 나올 것이라고 생각합니다.
앞의 문제들은 불편함에 가깝습니다. 하지만 GraphQL을 3년 사용하며 더 큰 문제들도 발견했습니다.
공짜는 없습니다. GraphQL API를 수정할 때, 일부 필드를 사용 중단(deprecate)할 수 있지만 하위 호환을 유지해야 합니다. 해당 필드를 사용하는 오래된 클라이언트를 위해 여전히 필드를 남겨두어야 합니다. GraphQL에서는 버전을 유지하지 않아도 되지만, 그 대가로 모든 필드를 계속 유지보수해야 합니다.
분명히 하자면, REST 버저닝도 고통스럽습니다. 하지만 기능을 폐지(sunset)하기 쉬운 성질을 제공합니다. REST에서는 모든 것이 엔드포인트이므로, 사용 중단된 엔드포인트를 신규 사용자에게 쉽게 차단할 수 있고, 누가 아직 구 엔드포인트를 쓰는지도 측정할 수 있습니다.
GraphQL 모범 사례 페이지에서 다음과 같은 문구를 볼 수 있습니다:
GraphQL 명세는 네트워크 처리, 인증, 페이지네이션 같은 API의 중요한 이슈들에 대해 의도적으로 침묵합니다.
아주 편리하죠 😅. 요컨대, 페이지네이션은 GraphQL에서 고통스럽다는 걸 곧 알게 될 겁니다.
캐싱은 이전 계산 결과를 저장해 서버 응답을 더 빠르게 얻는 것입니다. REST에서는 URL이 접근하려는 리소스의 고유 식별자입니다. 따라서 리소스 단위 캐싱이 가능합니다. 캐싱은 HTTP 명세에 내장되어 있습니다. 브라우저와 모바일도 이 URL 식별자를 활용해 리소스를 로컬에 캐시할 수 있습니다(이미지나 CSS처럼).
GraphQL에서는 같은 엔터티를 다루더라도 쿼리가 매번 다를 수 있어 복잡해집니다. 필드 수준 캐싱이 필요하지만, 단일 엔드포인트를 사용하는 GraphQL에서는 구현이 쉽지 않습니다. Prisma, Dataloader 같은 라이브러리가 유사한 시나리오를 돕기 위해 개발되었지만, 여전히 REST의 능력에는 미치지 못합니다.
데이터가 그래프 형태가 아닐 때 발생하는 문제입니다. 저자를 가져오고 그들의 모든 책을 가져오고 싶다고 상상해 보세요. SQL 같은 스토리지는 사실 책과 저자를 서로 다른 테이블에 저장합니다.
query {
authors {
name
books {
title
}
}
} 리졸버는 다음과 같을 것입니다:
resolvers = {
Query: {
authors: async () => {
return ORM.getAllAuthors()
}
}
Author: {
books: async (authorObj, args) => {
return ORM.getBooksBy(authorObj.id)
}
},
}
책 리졸버가 id마다 호출되기 때문에, 쿼리는 다음과 같이 됩니다
SELECT * FROM authors; SELECT * FROM books WHERE author_id == 1;
SELECT * FROM books WHERE author_id == 2;
SELECT * FROM books WHERE author_id == 3;
각 저자마다 DB 호출을 해야 하므로, SELECT * FROM books WHERE author_id in (1,2,3) 같은 SQL 기능을 사용할 수 있는 능력을 잃게 됩니다. 즉 DB에 2번이면 될 것을 N+1번 쿼리해야 합니다. 한 가지 해결책은 dataloader이지만, 이는 코드에 또 다른 복잡성 레이어를 추가하게 되어 성능 문제를 디버깅하기 더 어렵게 만듭니다.
우리는 문서를 업로드하고 표시하는 API를 가지고 있습니다. GraphQL은 기본적으로 multipart-form-data로 문서를 업로드하는 것을 제대로 지원하지 않습니다. Apollo는 file-uploads라는 해결책을 내놓았지만 설정이 어렵습니다. 게다가, 문서를 가져올 때 브라우저가 파일을 적절히 표시할 수 있도록 하는 미디어 타입 헤더(MIME type)를 GraphQL은 지원하지 않습니다.
GraphQL에서는 원하는 것을 정확히 쿼리할 수 있지만, 이는 복잡한 보안 함의를 동반합니다. 악의적인 사용자가 서버를 과부하시키기 위해 비용이 큰 중첩 쿼리를 제출하면 DDoS(서비스 거부 공격)에 취약해집니다.
노출되면 안 되는 필드에 접근할 수도 있습니다. REST에서는 URL 수준에서 권한을 제어할 수 있습니다. GraphQL에서는 필드 수준에서 제어해야 합니다.
user {
username <
email <
post {
title <
}
데이터 그래프가 커지면 데이터를 여러 서비스로 분할할 수 있습니다. 스티칭(Stitching)과 페더레이션(Federation)은 GraphQL 스키마를 더 작은 조각으로 나누도록 해주는 해결책입니다. 하지만 중요한 차이가 있습니다.
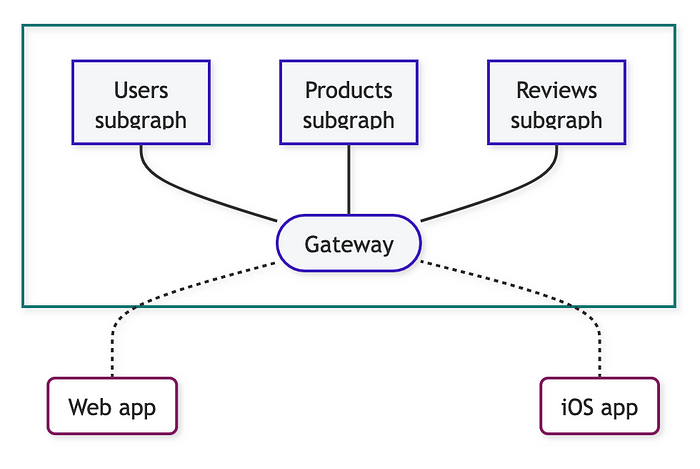
페더레이션은 회사의 스키마가 분산된 책임이어야 한다고 가정합니다. 다음과 같습니다:
이미지를 전체 크기로 보려면 Enter 키를 누르거나 클릭하세요
이미지: 작성자 제공
페더레이션(Apollo가 지원)에서는 각 서비스가 자신에게 해당하는 GraphQL 스키마 부분을 유지관리할 책임이 있습니다. 그런 다음 페더레이션 서버가 각 스키마를 가져와 하나로 병합합니다.
페더레이션은 여러 GraphQL 팀이 있는 조직이 전사적인 GraphQL 스키마를 연합시키는 데 도움이 됩니다.
GraphQL 경계를 지키는 한 페더레이션은 잘 작동합니다. 모든 것이 타입화되어 있어 에러를 쉽게 감지할 수 있습니다. 여러 스키마에 걸쳐 객체를 조인하기 위해 @key를 정의할 수 있습니다. 하지만 기본으로 핫 리로드를 지원하지 않습니다. 즉, 서브그래프가 변경될 때마다 게이트웨이를 재시작하거나, Apollo의 독점 솔루션인 Managed Federation을 사용해야 합니다.
스티칭은 회사의 스키마가 중앙집중적 책임이어야 한다고 가정합니다.
이미지를 전체 크기로 보려면 Enter 키를 누르거나 클릭하세요
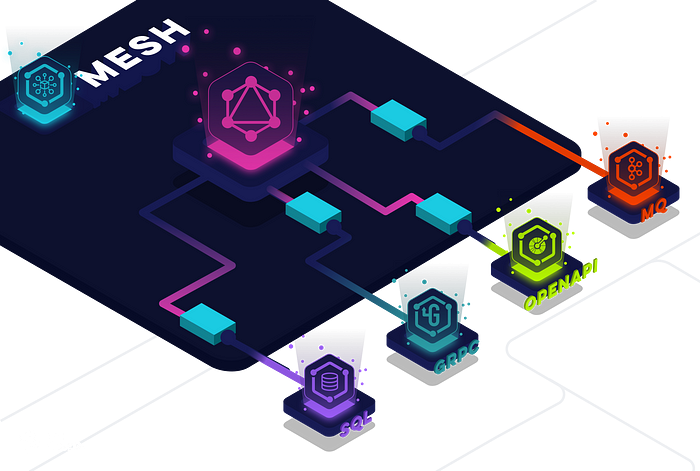
스티칭(mesh, hasura, stepzen 지원)은 중앙 데이터 API 팀이 유지관리하는 여러 데이터 소스를 가로질러 조인하는 데 도움이 됩니다. 게이트웨이에 하나의 메인 GraphQL 스키마를 정의하고, 데이터를 노출하는 각 서비스(gRPC, REST, SQL)에서 데이터를 자동으로 가져오도록 리졸버를 사용합니다.
스티칭은 서브 서비스에 GraphQL을 강제하지 않기 때문에 페더레이션보다 더 유연합니다. 어떤 데이터 소스든 소비할 수 있습니다. 하지만 제 경험상 스티칭은 다음과 같은 더 어두운 길로 이끄는 경향이 있습니다:
공정하게 말하면, 둘 다 꽤 복잡합니다. 이 선택은 기술적인 문제만이 아니라 조직 구조와도 연결됩니다. 팀이 독립적이고, 모든 곳에 GraphQL을 강제하고 싶지 않다면 스티칭이 더 나은 해법입니다.
제 생각에 생태계는 아직 성숙하지 않았고, 이것이 마지막 도전입니다.
GraphQL은 2012년 페이스북 내부에서 만들어져 2015년에 오픈소스화되었습니다. 2019년 페이스북은 GraphQL 재단을 설립해, 명세와 Node.js의 기본 구현(graphql.js)을 유지하는 중립적 비영리 조직을 만들었습니다.
그 이후로 많은 플레이어가 등장했고 생태계는 더 복잡해졌습니다. 2021년 5월 기준, Node.js만 해도 다른 구현이 네 가지(Apollo, Express, Yoga, Helix) 있고, Go에는 여섯 가지, Python에는 네 가지가 있습니다.
페이스북은 여전히 relay 같은 도구에 관여하고 있지만, 최종 의사결정자는 아닙니다. 생태계에는 지금 두 개의 주요 플레이어가 더 있습니다:
제안이 다양해지면서 생태계를 탐색하기가 어려워졌습니다. 명확한 가이드라인을 얻는 것도 어렵다고 느꼈습니다. 일부 플레이어들은 GraphQL의 미래에 대해 의견이 일치하지 않습니다. 스티칭 vs 페더레이션은 흥미로운 갈등 지점입니다.
반대로, 또 다른 오픈소스 프로젝트인 React는 전적으로 페이스북이 유지합니다. 이 경우 명확한 가이드라인을 갖기가 더 쉽습니다. 페이스북이 클래스 컴포넌트에서 훅으로 마이그레이션하기로 결정했을 때, 그 방향은 분명했습니다. 저는 공통 해법으로 수렴하는 생태계를 선호합니다.
REST가 새로운 SOAP였다면, 이제 GraphQL은 새로운 REST입니다. 역사는 반복됩니다. GraphQL이 그저 한때의 유행으로 사그라들지, 아니면 진짜 판을 바꾸는 존재인지 말하긴 어렵습니다. 분명한 건 아직 초기 단계이고, 우리 팀을 완전히 설득하지는 못했다는 것입니다.
Spendesk의 모바일과 프론트엔드 팀은 GraphQL을 사랑합니다. 놀라운 도구, API를 쉽게 탐색할 수 있는 능력, 강한 타입(특히 Kotlin과 Swift)은 더 나은 개발자 경험을 제공합니다. 페이스북의 초기 문제를 떠올리면 말이 됩니다. GraphQL은 모바일 문제를 해결하기 위해 개발되었으니까요. 하지만 이러한 이점이 여러분의 프로젝트에 꼭 관련 있는 것은 아닐 수 있습니다.
대부분의 문제는 백엔드 엔지니어와 이야기하기 시작하면서 드러납니다. 제대로 된 페이지네이션, 캐싱, MIME 타입의 부재는 실제 이슈입니다. GraphQL 타입과 네이티브 타입을 함께 관리하는 것은 복잡해지고, 리졸버는 유지보수가 더 어려워집니다. 프로젝트가 커질수록 큰 스키마를 해결하기 위해 스티칭이나 페더레이션 같은 매우 비싼 도구에 투자해야 합니다. 마지막으로, 생태계가 아직 성숙하지 않았고, 이 솔루션을 유지하는 비용이 REST API에 비해 너무 높다고 생각합니다.
합리적인 결정을 내리려면, 데이터의 모양(shape), 위치, 소유권, 접근 권한 등 비즈니스 요구사항을 이해해야 합니다. 또한 개발자 수, GraphQL에 익숙한지, 팀의 조직 구조 등 조직적 제약에도 달려 있습니다. Conway의 법칙이 말하듯, 조직은 결국 자신의 커뮤니케이션 구조를 닮은 시스템을 설계하게 됩니다.