git이 소스 저장소로서는 뛰어나지만 분산 워크플로 도구로서는 왜 충분하지 않은지, 특히 stacked PR과 변경 가능한 작업 흐름의 관점에서 설명합니다.
이 글은 git에 대한 글이다. 하지만 내가 이 글을 쓴 이유는 jj 때문이다.
jj에 대해 말하자면, 나는 그것을 사랑한다. 정말 좋아하고, 당신도 분명 좋아하게 될 거라고 확신한다. jj에 당신에게 치명적인 문제만 없다면, 진지하게 한번 써봐야 한다고 생각한다.
하지만 git이 괜찮다고 생각한다면 아마 그러지 않을 것이다. 그리고 그건 안타까운 일이다. 왜냐하면 git은 괜찮지 않기 때문이다.
git은 두 가지 일을 한다. 하나는 소스의 분산 저장소이고, 다른 하나는 분산 워크플로 도구다. 첫 번째 일은 너무도 훌륭하게 해냈기 때문에, 우리 대부분은 두 번째 일에 대한 git의 해법이 대체로 사후적으로 덧붙여졌다는 사실을 잘 보지 못한다. 그리고 실제로 의미 있는 방식으로 분산 협업을 한다면, 아니 스스로 인식하지 못하더라도 실제로는 그렇게 하고 있다면 — 시간 차를 두고, 자기 자신과 혹은 다른 사람들과 — 당신은 그 고통을 느끼고 있다. 왜냐하면 East River Source Control이 말하듯, 비동기 개발은 기본 요건이기 때문이다.
git을 잘 모른다면(사실 알고 있겠지만), git은 분산 버전 관리 시스템이며, 임계 규모에 도달한 최초의 DVCS이자 이제는 사실상 모두가 쓰는 거의 유일한 VCS다. rebase가 무엇인지 아는 거의 모든 엔지니어는 git 명령과 git의 개념으로 그것을 배웠다. 게다가 git은 여전히 작고 빠르며 효율적인, 조금은 기적 같은 도구이기도 하다. 그 결과, 우리 대부분은 아래처럼 생긴 작은 다이어그램을 보았거나 직접 그려본 적이 있다. 이것은 안정 상태의 로컬 기능 브랜치를 나타낸다.
이런 다이어그램은 git로 사고하는 방식의 핵심이다. 커밋과 브랜치. 커밋은 소스 코드와 그 역사이며, 불변이다. 브랜치는 로그가 달린 가변 포인터다.
하지만 이 완벽한 다이어그램 뒤에는 악마가 숨어 있다. 우리가 코드로 작업하는 방식을 표현하는 git의 모델에는 결함이 있다. 이제 그것을 드러내 보자.
멀리 떨어진 시간대에 있는 누군가와 협업한다고 해보자. 그 사람의 리뷰를 받기 전에는 아무것도 병합하고 싶지 않다. 그렇다면 그 시간대 지연이 있는 상황에서 어떻게 처리량을 유지할까?
CPU가 하는 방식과 같다. 작업을 파이프라이닝하면 된다. 하나의 PR을 작성하고, 제출하고, 끝날 때까지 기다렸다가 다음 것을 시작하는 대신, 첫 번째 PR을 작성해 제출하고, 그 위에 두 번째 PR을 작성해 제출하고, 그다음도 같은 식으로 이어가며, 순차적인 여러 PR을 동시에 리뷰에 올리는 것이다. 이렇게 말이다.
이를 가리키는 전문 용어가 바로 “stacked PRs”다. 그런데 안타깝게도 git은 stacked PRs를 다루기 매우 어렵게 만든다.
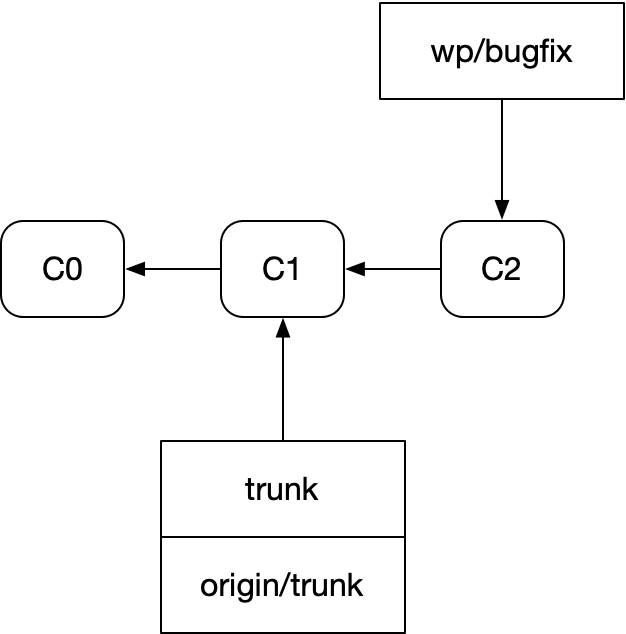
왜 그런지 보기 위해, fast-forward와 rebase 흐름이 git에서 어떻게 표현되는지 보자. 새로 fetch한 뒤 우리 저장소는 이렇다.
여기서 trunk를 fast-forward하고, 우리의 bugfix 브랜치를 그 위로 rebase한 뒤에는 이렇게 된다.
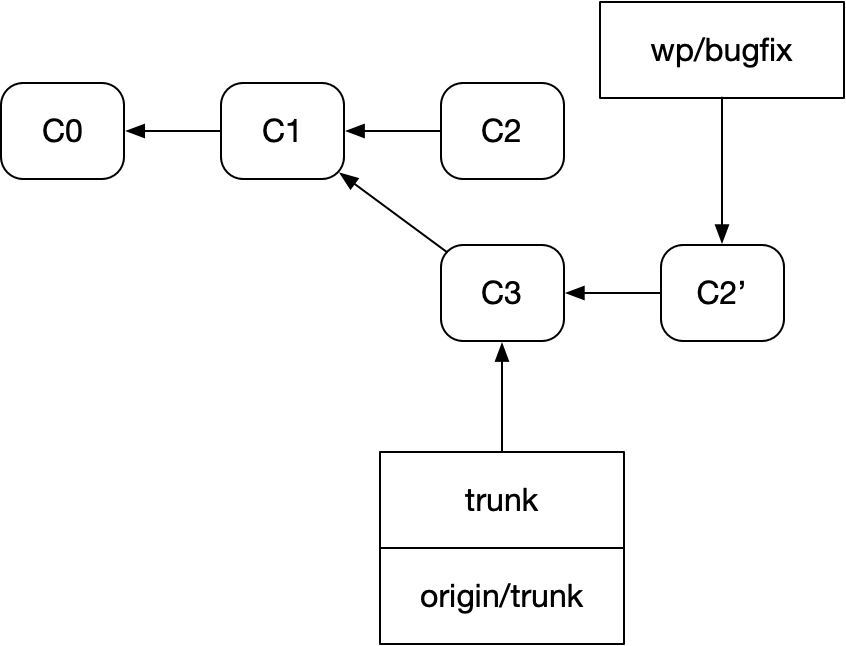
rebase는 C1에 대한 C2의 diff를 가져와, origin에서 받아온 새 커밋 C3에 적용하고, 그 결과 C2’를 만든다.
이 관계는 다이어그램에서 꽤 명확하다. 그래서 사람들이 그런 식으로 다이어그램을 그리는 것이다. Pro Git에도 정확히 그런 형태의 다이어그램이 들어 있다.
하지만 이런 커밋 이름은 실제 저장소에서는 보기 힘들다. 현실은 이쪽에 더 가깝다.
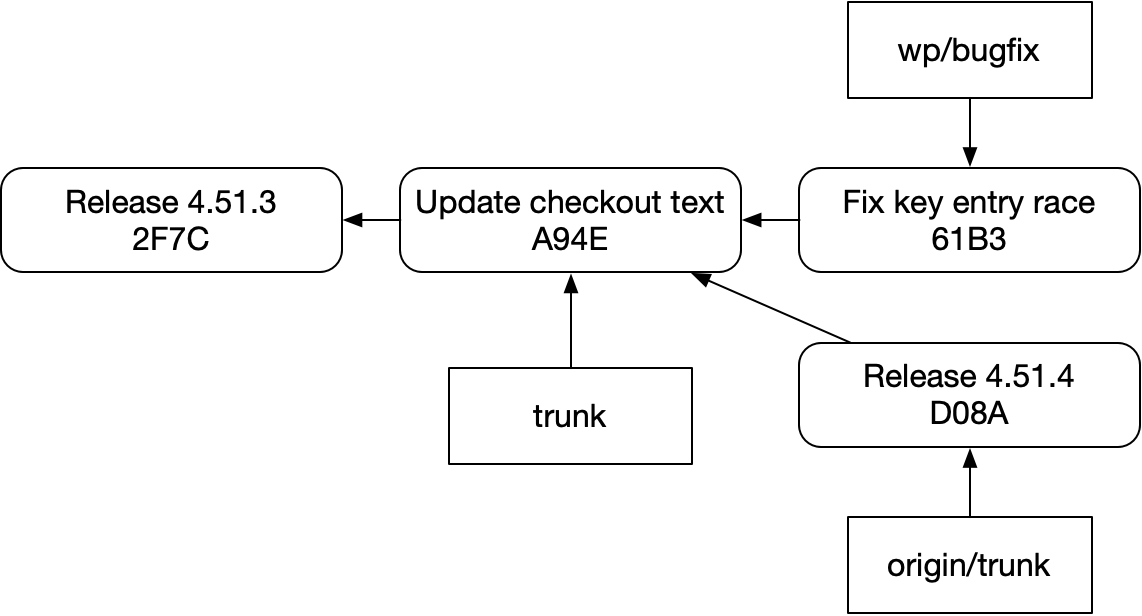
그리고 rebase를 마치고 나면 대략 이렇게 된다.
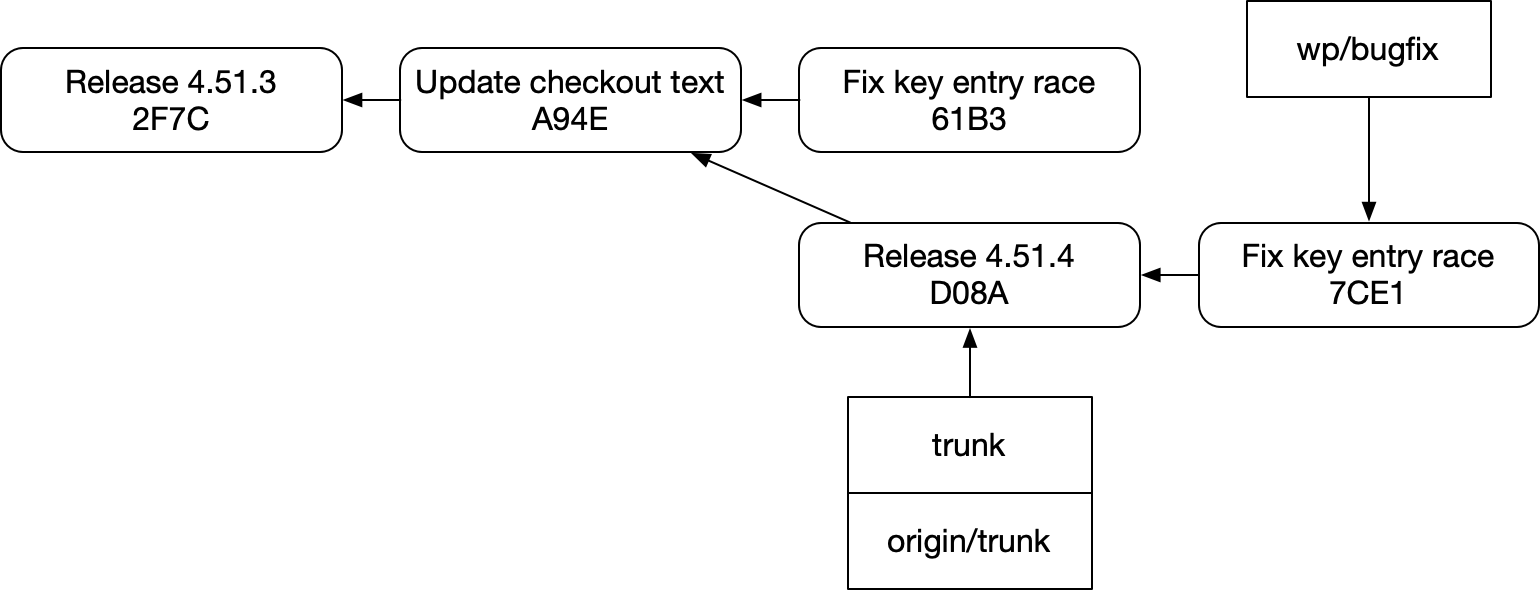
이 다이어그램들과 앞선 다이어그램들을 새로운 눈으로 잠시 읽어보자. 그것들이 기반 시스템에서 무엇을 가리키는지 생각해 보라.
그러면 새 다이어그램에서 중요한 정보 일부를 잃어버렸다는 점이 보일지도 모른다. 두 개의 “Fix key entry race” 커밋은 아포스트로피로 표시된 순서 관계를 갖고 있었다. 하지만 새 다이어그램에는 그것이 없다. git은 그 관계를 전혀 알지 못하며, 당신에게 그것을 알려줄 수도 없다.
예전 다이어그램에서 C라는 이름이 붙은 커밋들은 모두 하나의 브랜치 안에서 정렬된 연속열에 속한다는 인상도 준다. 새 다이어그램에서도 시각적으로는 여전히 그렇게 보이지만, 화살표는 다른 이야기를 한다. 실제 저장소에서 코드나 git 명령으로 “Release 4.51.4”의 후속 커밋을 찾는 일은 전혀 간단하지 않다. “Release 4.51.4”로 가는 경로에서 보이는 커밋들을 모든 브랜치에서 훑어봐야 한다.
그래서 우리가 고전적인 git 다이어그램을 읽을 때, 혹은 이렇게 좀 더 자세한 git 다이어그램을 읽을 때조차, 다이어그램 자체와 때로는 우리 눈이 도구의 능력에 대해 우리를 오도한다. 여러 변형을 찾아볼 수 있는 “C2” 같은 것은 없다. 이 커밋들을 하나로 묶는 “C”조차 없다. 그런 개념은 존재하지 않는다.
그 결과, git의 커밋은 다음을 알려줄 수 없고, 그것에 대해 전혀 알지도 못한다.
브랜치도 그것을 할 수 없다. 브랜치에는 역사라는 개념이 있긴 하지만:
trunk로부터 wp/bugfix를 신뢰성 있게 찾는 것은 불가능하다. 심지어 trunk에서 도달 가능하지도 않다. 앞방향 참조가 없기 때문이다.이해됐는가? 좋다. 왜냐하면 이것은 당연히 stacked PRs에 대한 이야기이기 때문이다. 기억나는가?
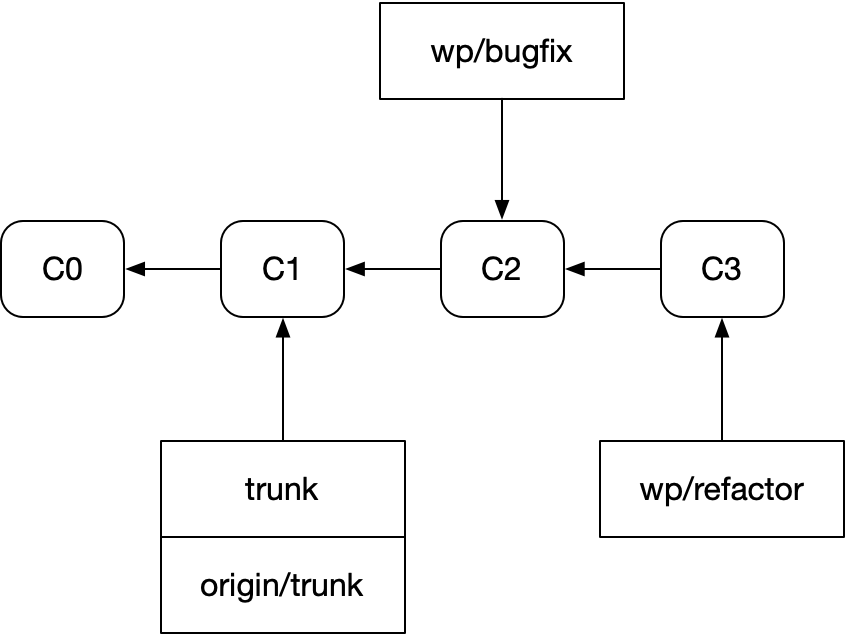
그 예제로 돌아가 보자. bugfix의 후속 PR을 하나 작성했다고 해보자.
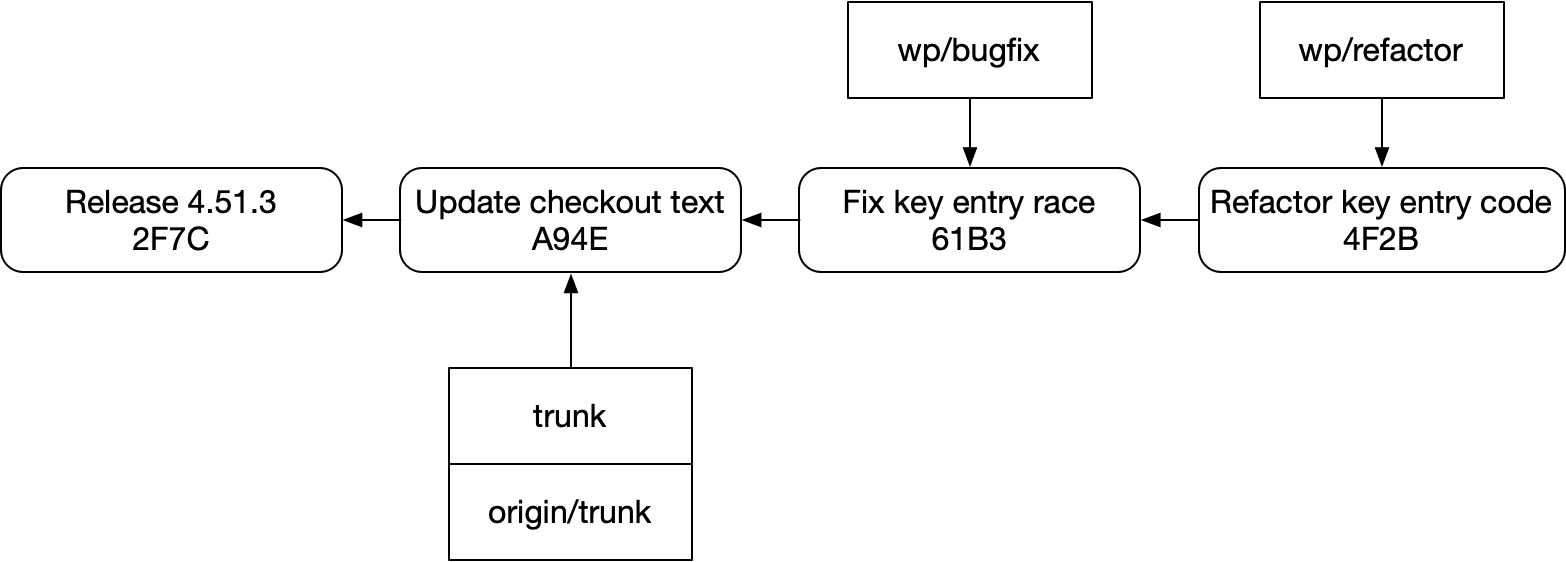
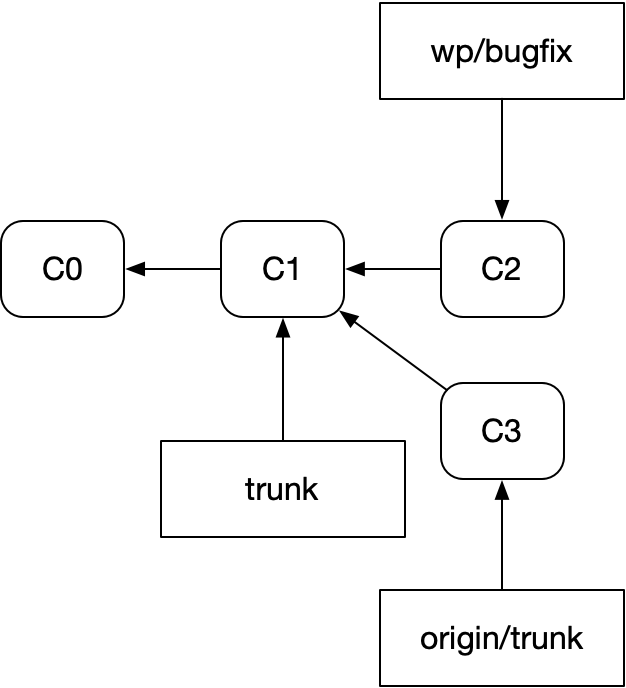
그리고 fetch해서 trunk를 업데이트했다.
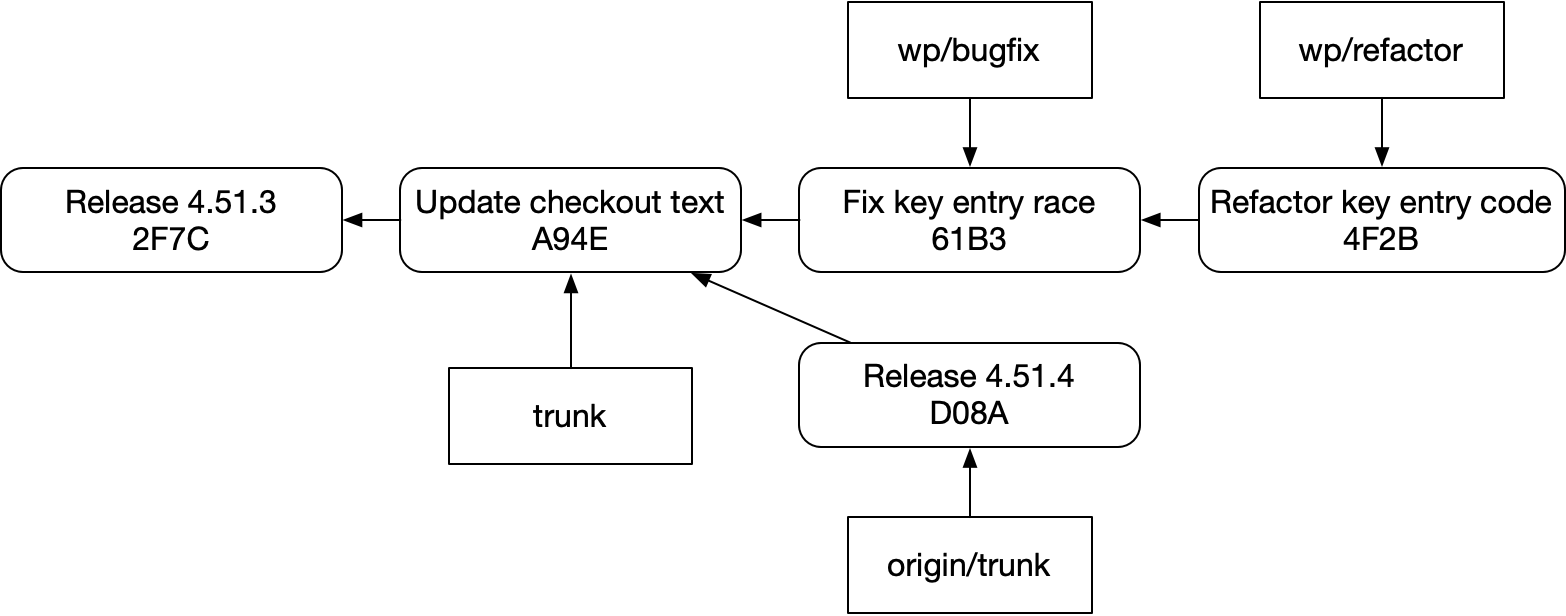
그러면 스택을 보존하면서 이것을 이렇게 간결하고 신뢰성 있게 rebase하려면 어떻게 해야 할까?
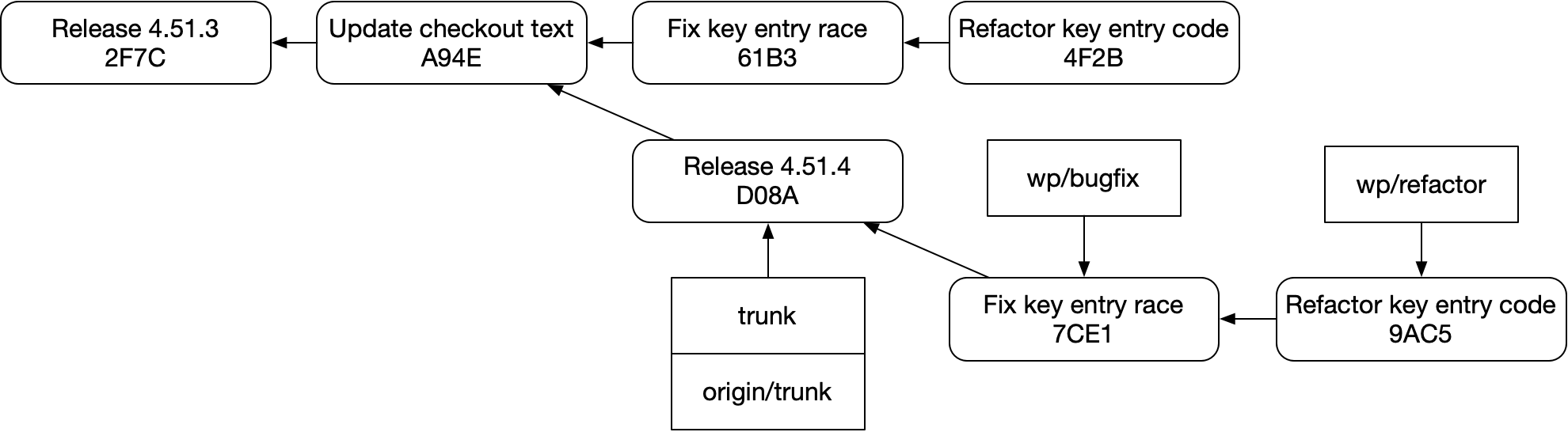
답은 “쉽지 않다”이다. 이 구조는 git에서 취약하다. 실수로 이렇게 하기도 쉽다.
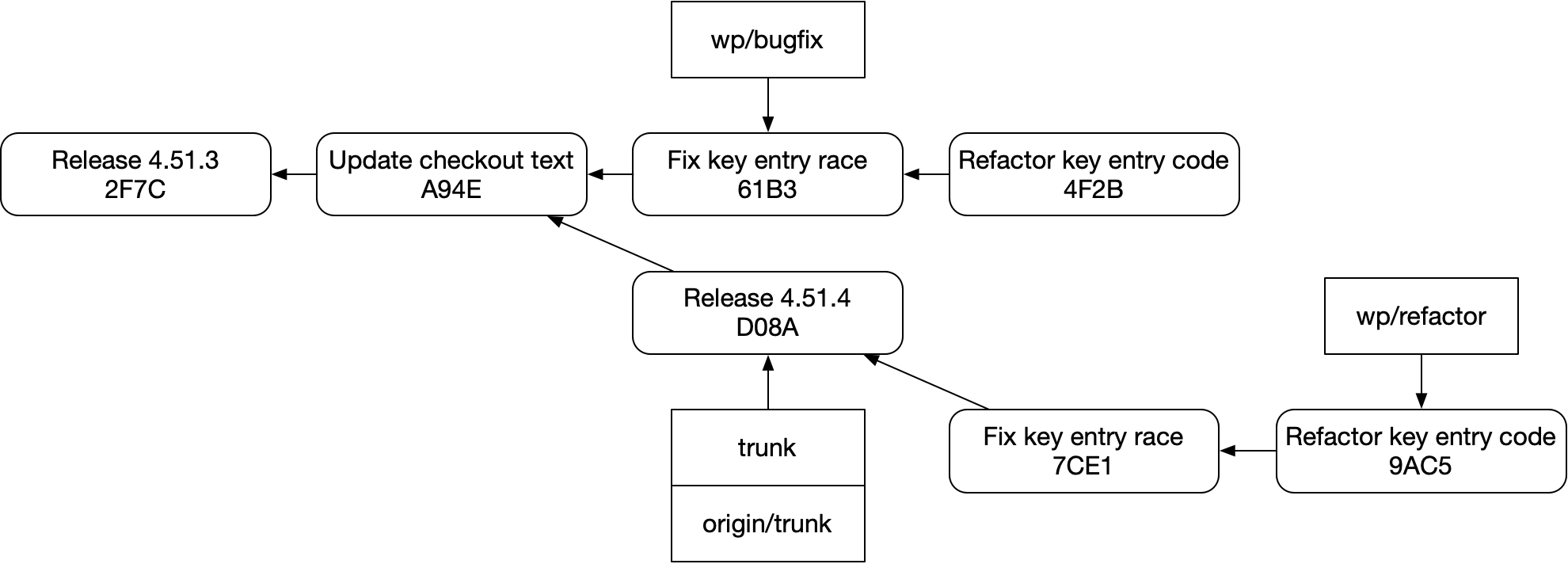
혹은 이렇게:
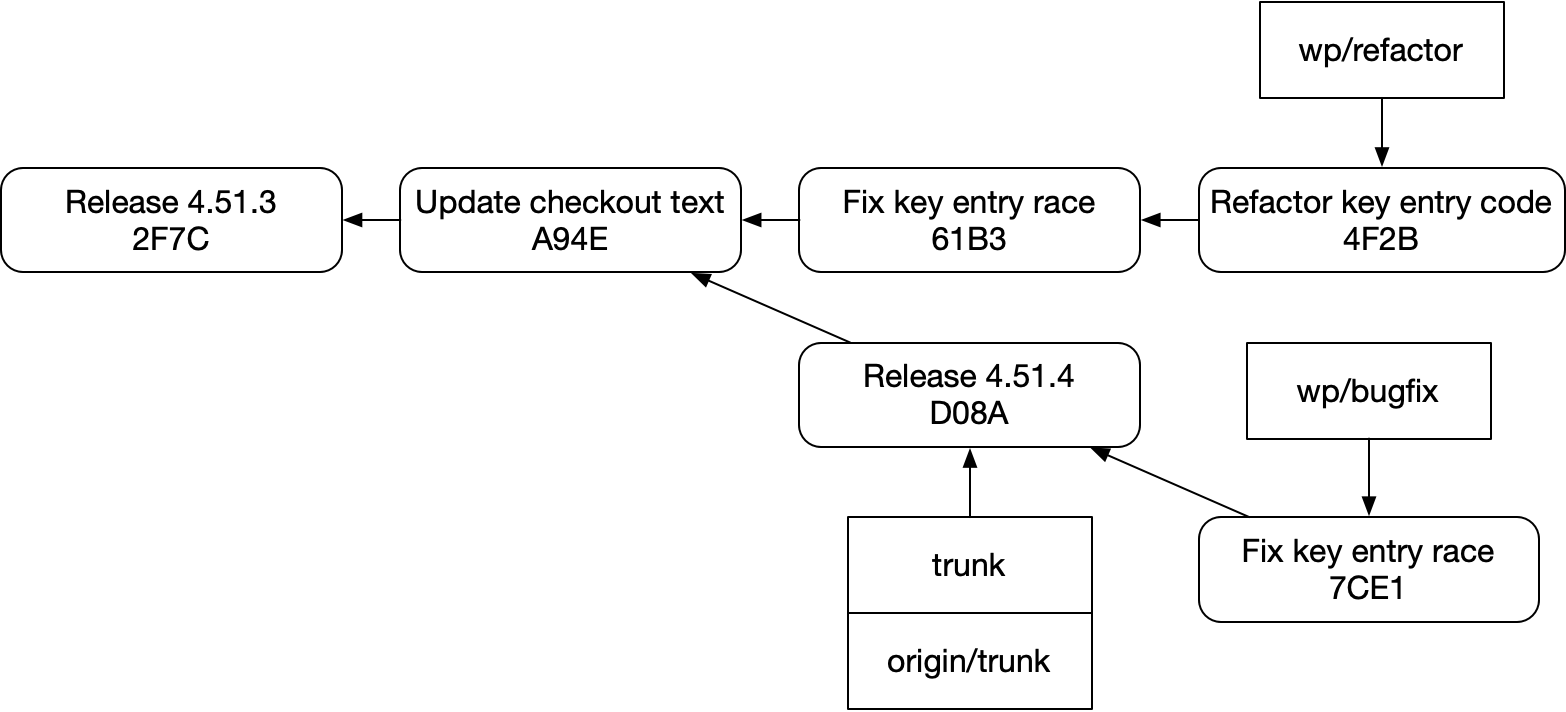
그 이유는 몇 가지가 있다.
Fix key entry race에서 Refactor key entry code를 쉽게 볼 수 없다.graphite 같은 스태킹 도구는 물론 git으로 이 일을 해낼 수 있다. 하지만 우아하지는 않다. 브랜치나 커밋 자체를 확장해서 이런 부족함을 고칠 수 없기 때문에, 별도의 브랜치 메타데이터 저장소를 만들고 그것을 git과 동기화해 유지해야 한다. 그리고 git 자체와 직접 상호작용하면 그 저장소는 쉽게 어긋날 수 있다.
이 모든 문제는 git이 가변성을 손대지 않는 방식으로 모델링한 데서 흘러나온다. 알고 보면 변경은 중요하다. 적어도 내가 돈을 받고 해온 일은 대체로 그거였다. 그러니 편집 워크플로에서 git이 그것을 어떻게 다루는지 보자.
우리가 작업을 시작하기 전 bugfix 브랜치는 이렇게 생겼을 것이다.
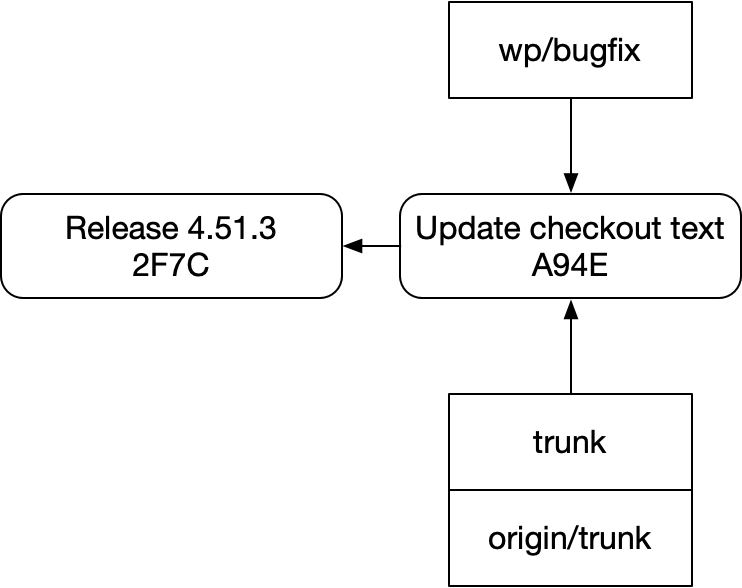
여기에 우리의 checkout을 다이어그램에 추가하면 상황은 더 복잡해진다. 이것이 git이 제시하는 정신 모델을 내가 표현한 그림이다.
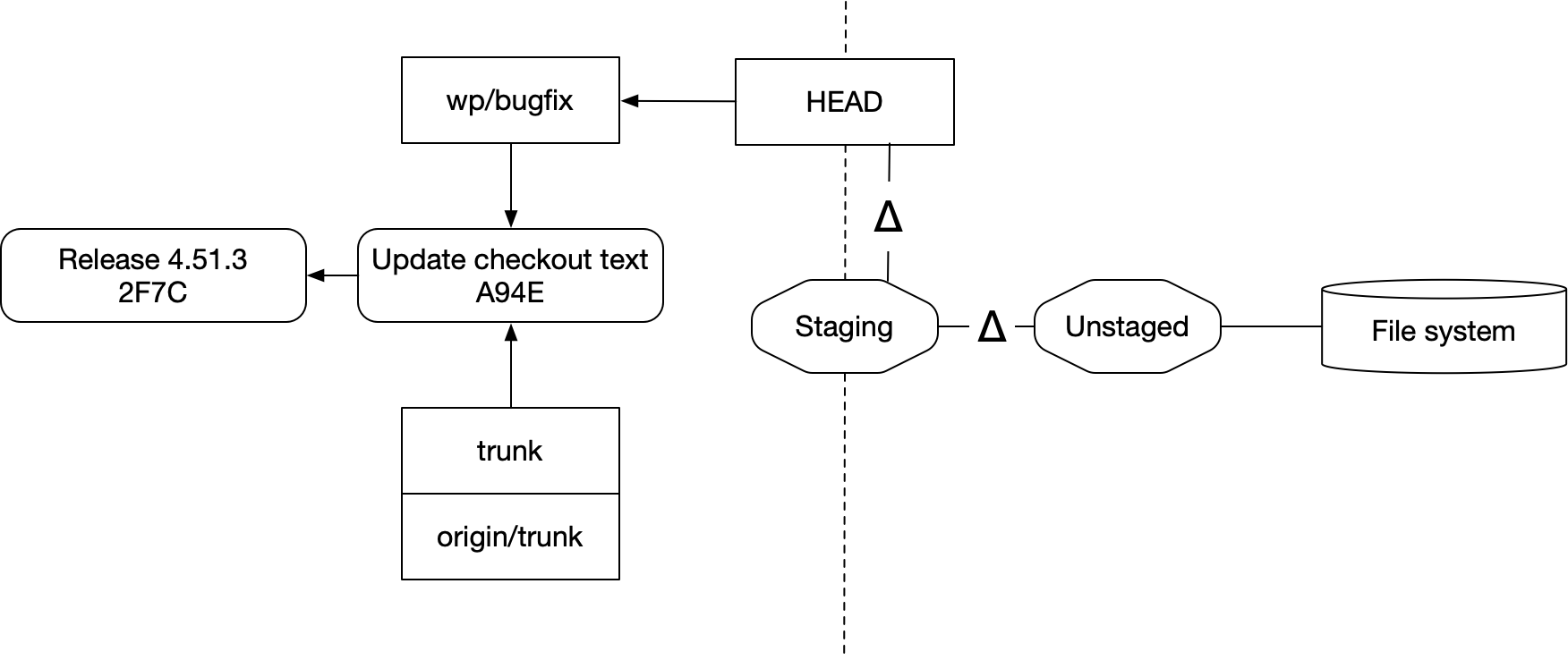
여기에 stash 시스템도 있지만, 그건 다루지 않겠다. 그것은 Staging과 Unstaged의 변경을 저장하고 복원하기 위한 별도 저장소처럼 동작한다.
이 모든 것은 저장소의 일종의 대기실처럼 존재한다. 당신의 checkout은 파일 시스템에 있고, 당신이 하는 편집은 Staged로 옮기기 전까지는 Unstaged에 머문다. 그다음에는 그것들을 커밋으로 체크인할 수도 있고, 버리고 파일 시스템을 HEAD 브랜치와 같은 내용으로 되돌릴 수도 있다.
다른 커밋이나 브랜치를 checkout해서 HEAD가 다른 위치를 가리키게 되면, git은 Staging이나 Unstaged에 있는 diff를 보존하면서 파일 시스템을 그에 맞게 업데이트하려고 시도한다.
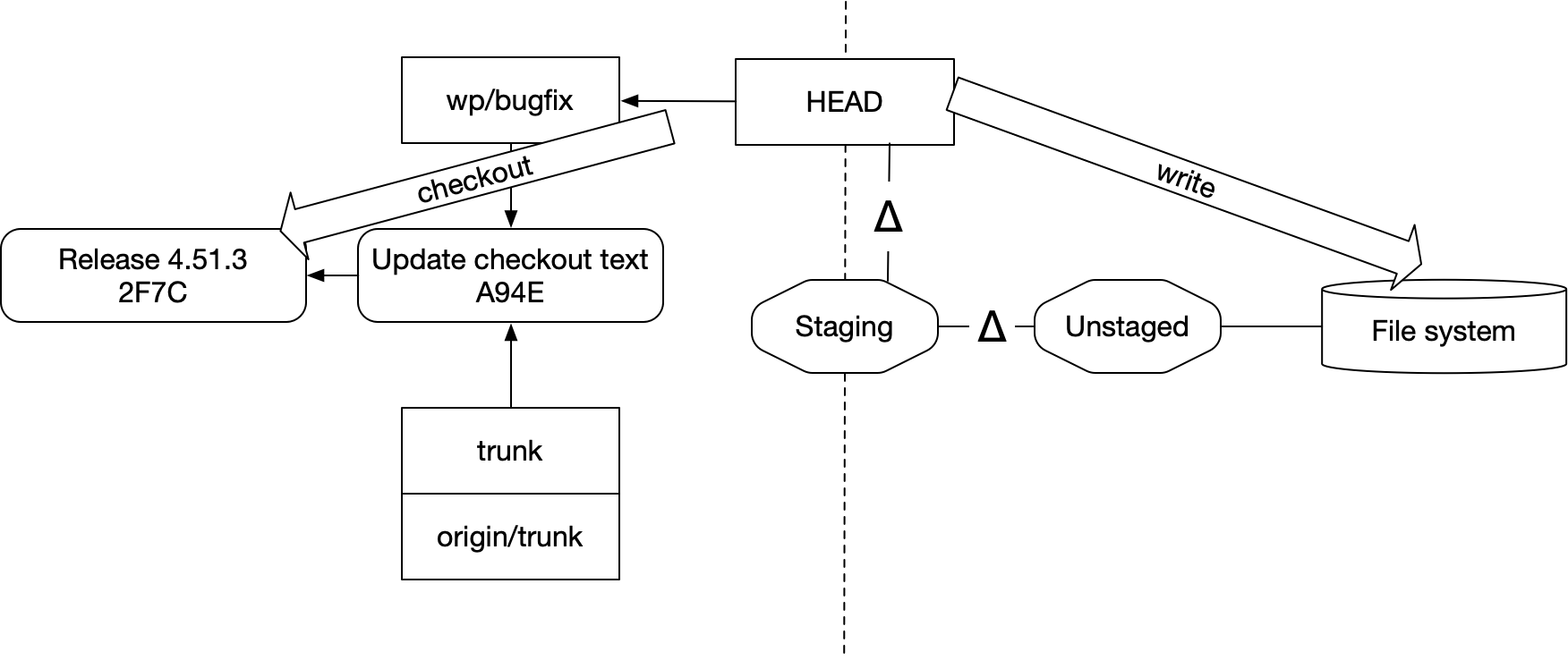
그리고 그것이 성공하면, 관계는 이렇게 갱신된다.
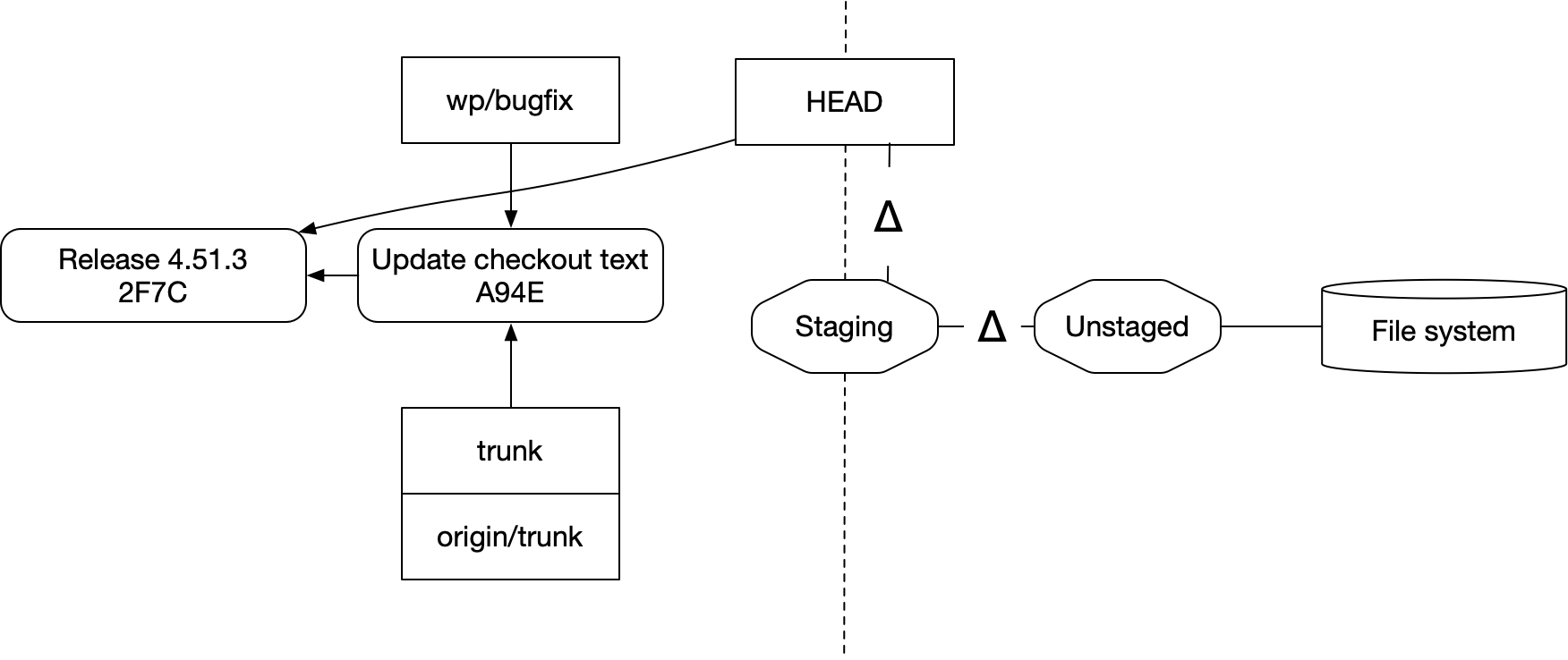
여기서 주목할 점이 몇 가지 있다.
첫째, 당신의 변경은 명시적 명령 없이는 절대로 왼쪽으로 이동하지 않는다. 아마 이 모든 것이 “저장소 안”에 있다고 볼 수도 있을 것이다. 어쨌든 전부 당신의 파일 시스템에 있으니까. 커밋을 만든다고 해서 그것이 백업되거나 안전하게 보관되도록 네트워크를 통해 전송되는 것은 아니다. 하지만 지시하지 않으면 정돈된 커밋과 브랜치의 영역으로 아무것도 들어가지 않는다.
둘째, 이것은 Release 4.51.3 위로 Staging을 rebase한 것처럼 보인다. 사용한 명령은 “왼쪽 영역”의 rebase와 다르고, rebase한 대상도 커밋과 상호운용되지 않지만, 화살표가 움직인 방식만 놓고 보면 — 이것은 rebase다.
정말 그렇게 생각할 수 있을까? 모든 것을 커밋으로 모델링한다면 어떨까?
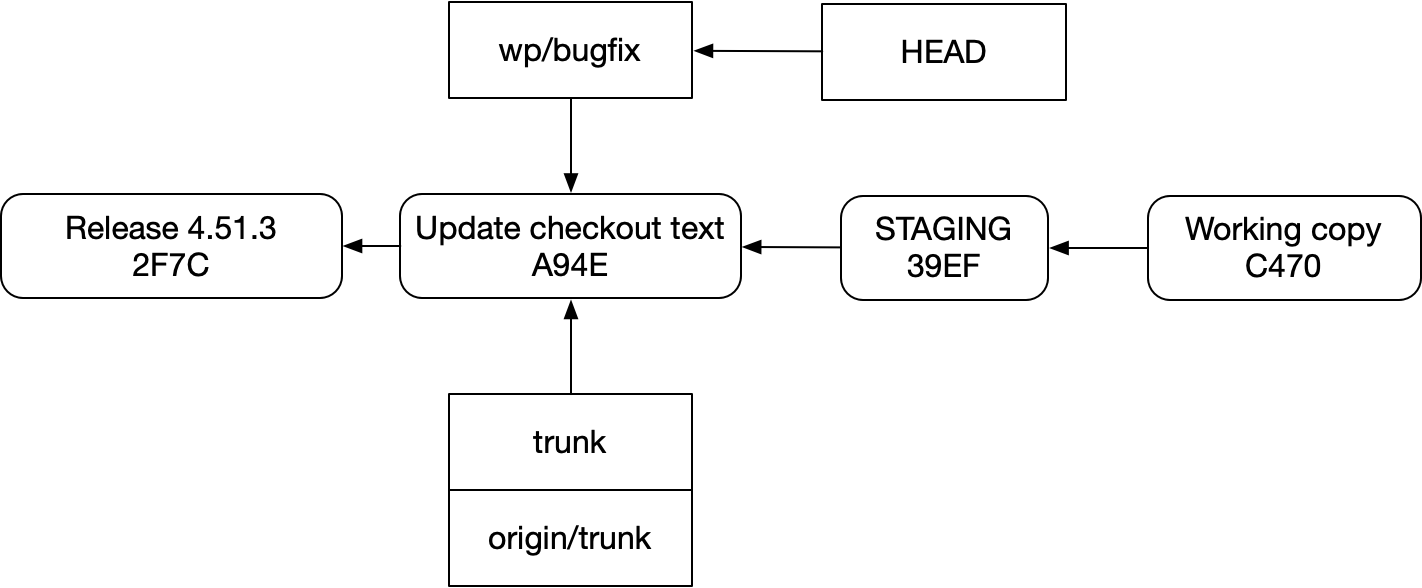
이 아이디어가 우리의 뇌 속 타이밍 벨트에 얼마나 많은 Swedish fish를 쑤셔 넣는지는 제쳐두고, 또 위 다이어그램에 기반한 시스템이 실제로 어떻게 작동할 수 있는지에 대한 수많은 “이제 나머지 올빼미도 그려보라” 문제를 잠시 무시하더라도, 안정 상태에서 이것은 표현상 그리 이상한 발상은 아니다. Staging과 working copy에는 우리가 가리킬 수 있는 분명한 조상이 있고, 그것들 역시 일반 커밋처럼 소스 코드를 담고 있다. 단지 작은 데이터베이스 대신 파일 시스템 안에 있을 뿐이다.
그런데도 Swedish fish는 여전히 있다. 그 물고기의 이름은 “가변성”이다. 커밋 id는 내용의 해시다. 그러니 그것들이 가변적이라면 그 id는 끊임없이 바뀐다. 그렇다면 Staging과 working copy가 “무엇인지”에 대해 어떻게 일관된 개념을 가질 수 있을까? 결국 그것들은 브랜치여야 하는데, 브랜치에는 또 다른 문제들이 있다. 그것도 이미 살펴봤다.
이 복잡성은 실제 문제를 일으킨다.
그리고 마지막 항목, 실제 워크플로를 표현할 수 없다는 이야기 말이다. 이제 숨을 돌리고 글을 마무리하기 전에, 그것을 조금 더 파고들어 보자.
새 기능을 만들기 시작했다고 해보자. 새 브랜치를 만들었지만, 아직 작업을 커밋하지는 않았다. 그러면 저장소 상태는 이렇다.
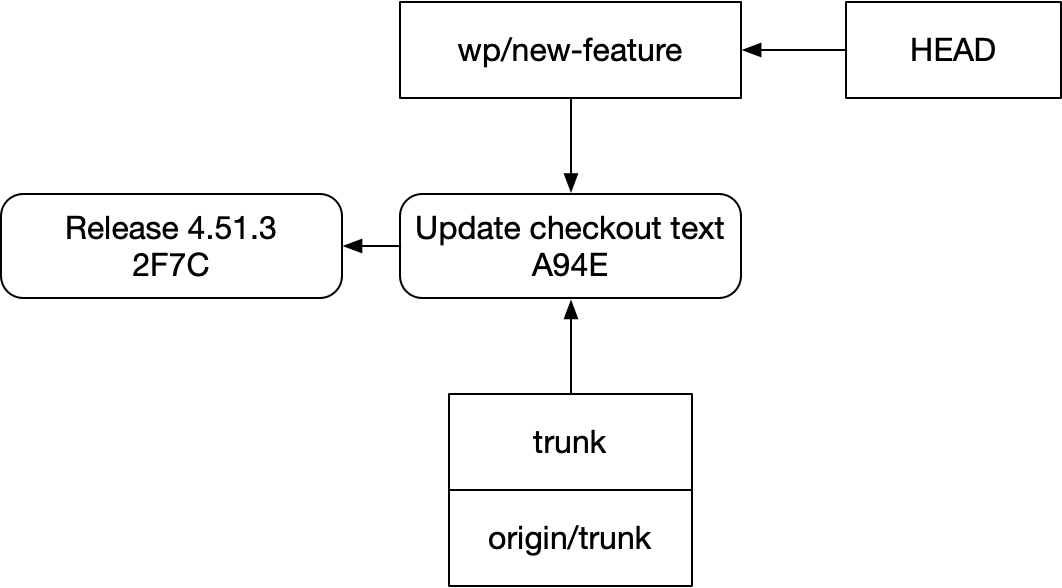
이 기능을 기기에서 마무리하던 중, 버그를 하나 발견한다. 변경을 막을 정도는 아니지만, 개발을 꽤 성가시게 만든다. 그래서 작업을 stash하고, 새 브랜치로 전환한 다음, 재현 테스트를 만들고, 문제를 고친다.
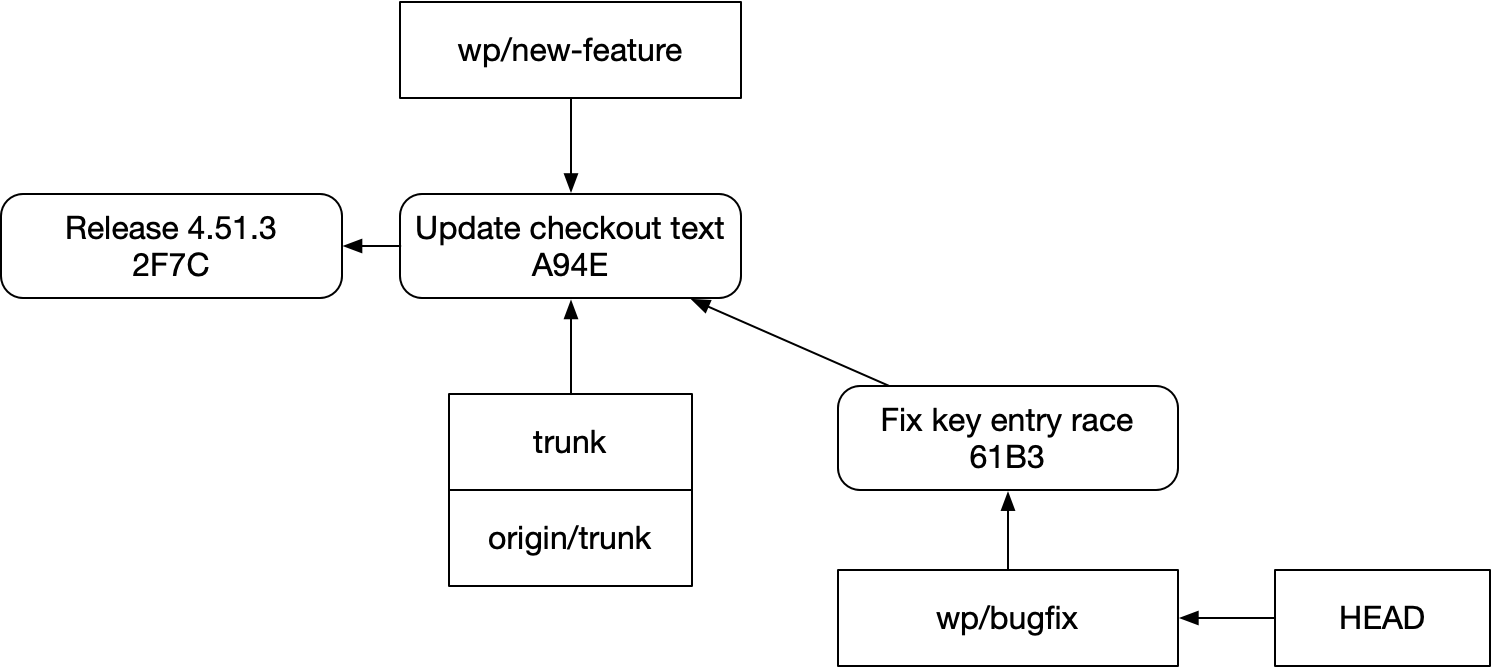
그 수정으로 팀의 저장소에 PR도 제출한다.
그 일을 마친 뒤, 다시 feature 브랜치로 돌아온다.
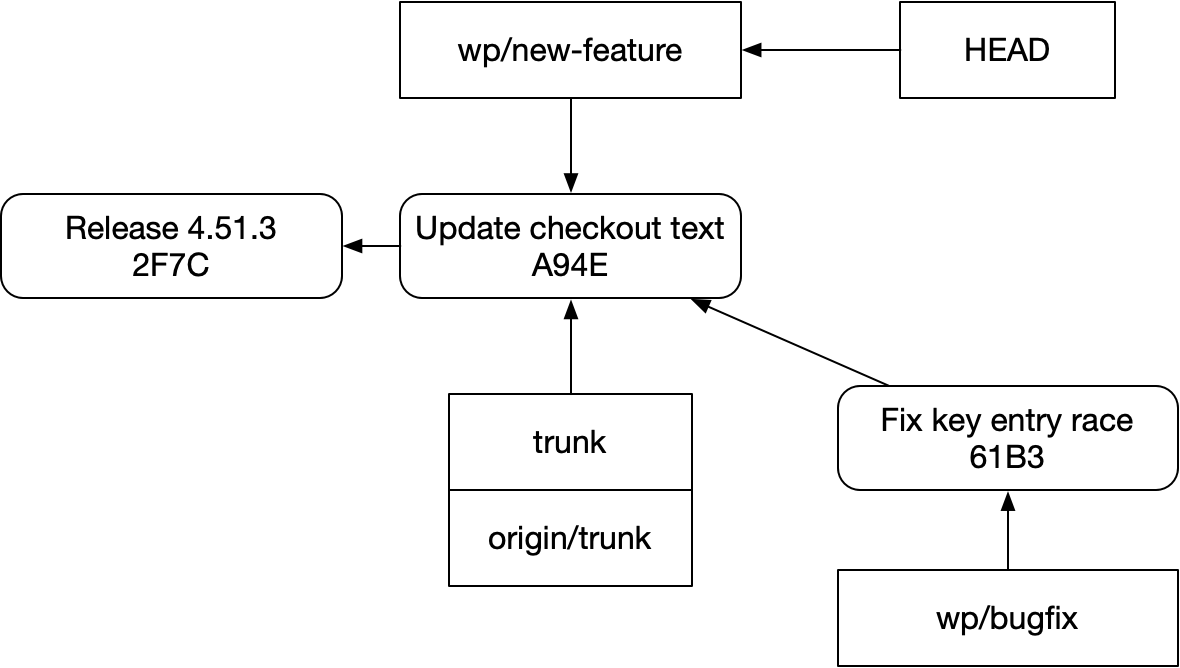
이제 무엇을 해야 할까? 짜증 나는 버그이니 개발하는 동안 파일 시스템에는 그 수정이 들어 있기를 원한다. 하지만 실제로는 작업을 막고 있지는 않다. bugfix의 리뷰가 지연되더라도 새 기능은 문제없이 병합될 수 있다.
git에서 당신의 선택지는 다음과 같다.
new-feature를 bugfix 위로 rebase하고, 그 상태로 리뷰를 밀고 나간다new-feature를 bugfix 위로 rebase해 두었다가, 브랜치를 제출하기 전에 그 rebase를 되돌린다하지만 할 수 없는 것은 이런 식으로 말하는 것이다. “내 편집 작업공간에는 bugfix의 모든 코드와, 내가 이미 커밋한 new feature의 코드가 함께 있어야 한다.”
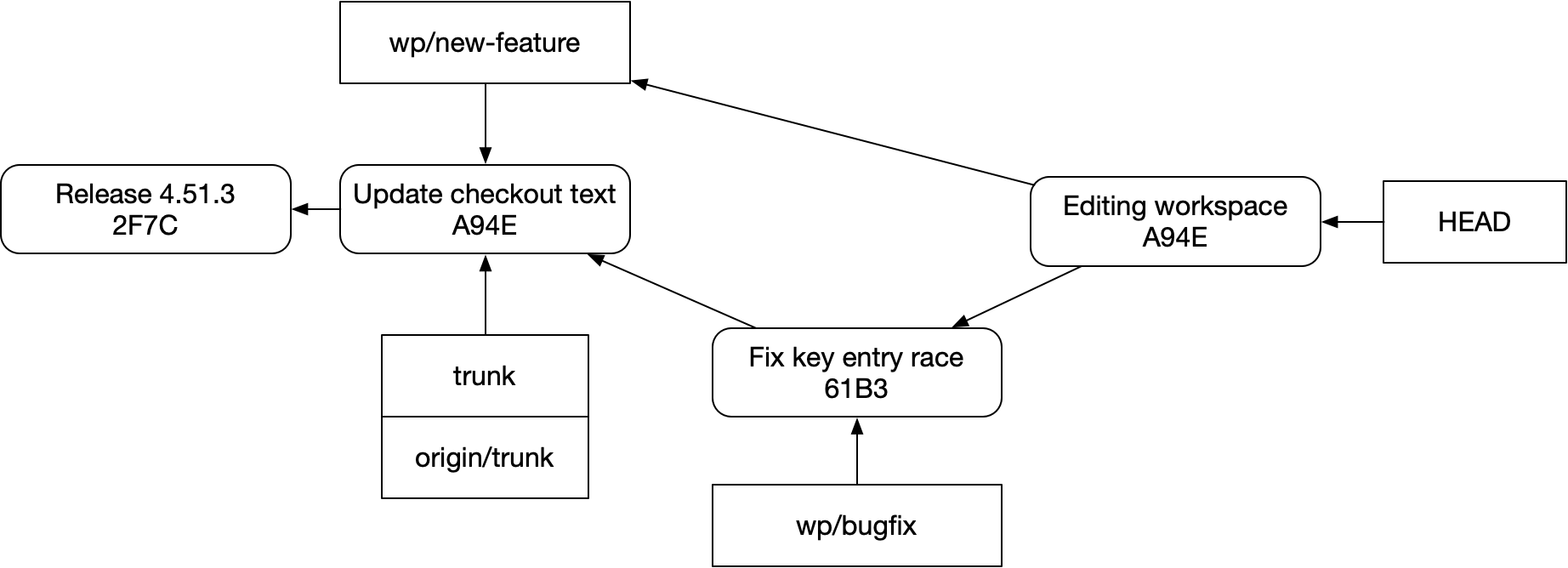
“그건 쓸데없어!”라고 말할 수도 있다. 하지만 이런 일은 실제로 일어나고, 이것보다 더 어려운 문제들도 같은 형태를 띤다. 예를 들면 병합되지 않은 PR들과의 호환성을 테스트하는 경우가 그렇다. “그건 너무 이상해!”라고 말할 수도 있다. 하지만 전혀 그렇지 않다. 적절한 도구만 있다면, 모든 PR이 병렬로 진행 상태를 유지하면서도 편집 공간에서는 함께 이용 가능하도록 개발 방식을 구성하는 것은 어렵지 않다. 그리고 그건 꽤 좋다.
오늘날의 상황은 2000년대 초반만큼 심각하지는 않다. git 이전 VCS 도구들의 실패는 꽤 분명했다. VCS 도구는 편차가 매우 컸고, 사용하기도 관리하기도 종종 고통스러웠다. 모두가 Subversion이 불편하다는 데 동의했다. 비용을 감당할 수 있는 사람들은 다른 도구를 썼고, 심지어 그 경우에도 불만은 있었다.
오늘날에는 자기 git 저장소를 관리하는 것에 대해 불평하는 사람이 거의 없다. 하지만 그 당시에는 저장소 전체를 로컬에 복사해 두고 싶다고 외치는 사람도 거의 없었다. 대부분의 사람들은 브랜치 관리가 더 쉬워질 수 있다고 생각했지만, 로컬 머신에서 브랜치를 만들고 싶다고까지는 분명 생각하지 않았다. 파일 잠금에 짜증 내는 사람은 많았지만, 동시에 많은 사람들은 그것이 필요하다고 여겼고 그 기능이 없는 VCS를 사용하는 것은 상상조차 못 했다.
물론 모두가 그랬던 것은 아니다. 특히 오픈 소스 쪽 일부 사람들에게는, DVCS를 처음 본 경험이 오랫동안 피를 흘리던 상처에 붙이는 붕대를 처음 본 것과 같았다.
내 생각에 지금 우리가 바로 그 지점에 있다. 워크플로가 실질적으로 분산되어 있는 사람들에게, git의 과거지향적이고 불변인 역사 모델은 반복적으로 문제의 원천이 된다. 그 결과, git은 놀라울 정도로 오랫동안 최첨단보다 뒤처져 있었다. Meta 같은 회사들은 거의 10년 동안 git을 훨씬 능가하는 사내 시스템을 누려 왔다.
그리고 나는 많은 사람이 “아, 나는 이제 git을 직접 만지지 않아. Claude가 대신 해주거든”이라고 말하는 것을 듣지만, 그렇다고 이런 해법들이 무의미해진다고는 생각하지 않는다. 오히려 반대로, 엔지니어들은 예전보다 LLM과 함께, 심지어 한 대의 머신 안에서도, 더 많은 비동기 개발을 하고 있는 듯하다.
여기서 내가 설명한 고통을 이미 느끼고 있는 사람이라면, 뭐 — 이 글을 재미있게 읽었고 유용하다고 느꼈기를 바란다. 좋아요와 구독, 그런 것들 말이다. 하지만 그렇지 않고, 지금 도구가 괜찮다고 생각하는 사람이라면, 내가 하고 싶은 말은 이것뿐이다. 어쩌면 당신은 지금 빗속에 서 있는지도 모른다는 것. 그리고 안은 꽤 좋다는 것. 이리 들어오라.
2026/05/14
-Up-^