J9 Java VM에서의 가비지 컬렉션 경험과 ‘A Unified Theory of Garbage Collection’의 통찰을 바탕으로, Ohm과 ProseMirror를 이용한 증분 파싱/변환 파이프라인에서 전체 문서를 순회하지 않고 재사용되지 않은 노드만 효율적으로 찾아내기 위해 참조 카운팅을 적용한 방법을 설명한다.
2025년 11월 14일
오래전에 나는 J9 Java VM에서 가비지 컬렉션 작업을 몇 년 동안 했다.1 그 뒤로는 주로 더 상위 수준의 일을 해 왔지만, GC에 대한 깊은 지식은 계속해서 유용했다.
어제는 내가 가장 좋아하는 GC 논문 가운데 하나인 A Unified Theory of Garbage Collection의 통찰이 까다로운 문제를 해결하는 데 도움이 되었다.
나는 Ohm을 사용해 텍스트 문서를 파싱하고, 그 결과를 ProseMirror에서 리치 텍스트 버전으로 렌더링하는 팀과 함께 일하고 있다. 목표는 양방향 업데이트다: ProseMirror에서의 변경이 텍스트 버전에 반영되고, 그 반대도 마찬가지여야 한다.
Ohm은 증분 파싱을 지원한다. 즉, 어떤 텍스트를 파싱한 뒤 작은 수정을 하면 이전 결과의 일부를 재사용해 빠르게 다시 파싱할 수 있다는 뜻이다.
또한 제한적인 형태의 증분 변환도 지원한다. 일종의 메모이제이션된 비지터 같은 속성(attribute) 을 정의할 수 있고, 특정 노드의 속성 값은 편집이 그 노드의 서브트리 중 하나에 영향을 미친 경우에만 재계산하면 된다. 따라서 각 새로운 값(예: AST)이 이전 값과 많은 구조를 공유하는 일종의 영속적(persistent) 데이터 구조를 손쉽게 구현할 수 있다.
이 메커니즘을 사용해, 주어진 입력에 대해 ProseMirror 문서를 만들어 내는 pmNodes 속성을 만들어 보았다. 텍스트 문서를 편집하면 이전 것과 많은 노드를 공유하는 새로운 트리를 만든다.
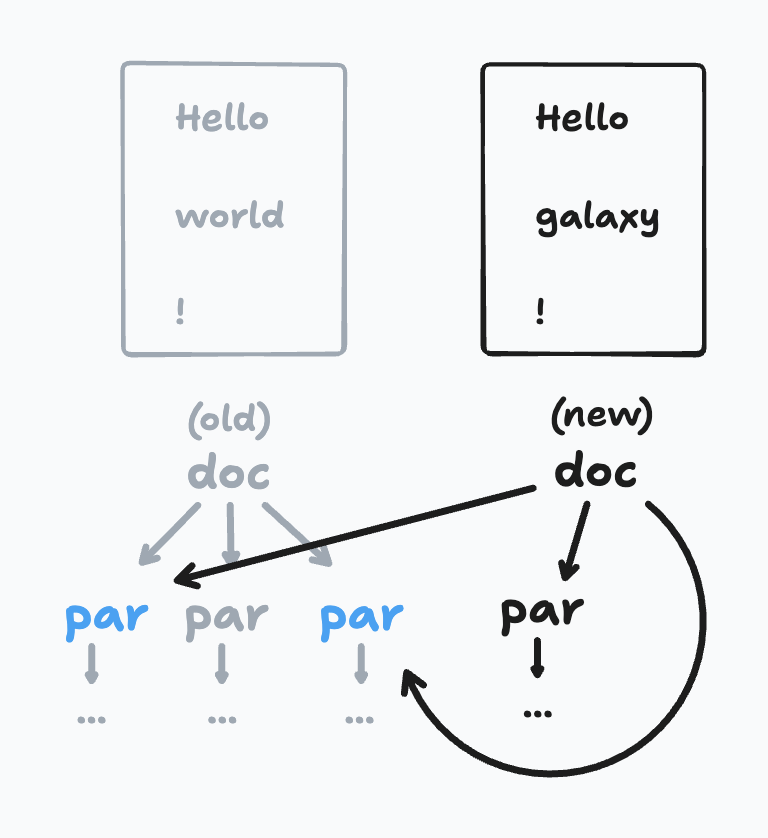
편집 전후의 pmNodes 트리.
그다음 계획은 ProseMirror 트랜잭션을 구성해 이전 트리를 새로운 트리로 바꾸는 것이었다. 그러려면 이전 문서에는 있었지만 새 문서에는 없는 노드가 무엇인지 아는 것이 도움이 된다.
이걸 위한 첫 구현은 추적(Tracing) 가비지 컬렉션과 사실상 같았다 — 각 편집 후 전체 문서를 순회하며 모든 노드를 Set에 기록했다. 두 Set의 차이가 어떤 노드가 ‘죽었는지’를 알려줬다.
하지만 이것은 증분성의 목적을 어느 정도 무색하게 만든다 — 문서가 길고 작은 수정을 했을 때, 문서의 모든 노드를 방문하지 않고도 처리할 수 있어야 한다.
그러다 A Unified Theory of Garbage Collection, 즉 내 예전 동료들이 쓴 2004년 OOPSLA 논문이 떠올랐다:
추적과 참조 카운팅은 기본적으로 서로 다른 가비지 컬렉션 접근법이며 매우 뚜렷한 성능 특성을 갖는 것으로 일관되게 여겨져 왔다. 우리는 두 유형 모두의 고성능 수집기를 구현했고, 그 과정에서 최적화를 많이 할수록 둘의 동작이 더 비슷해진다는 것을 관찰했다 — 즉, 그들은 어떤 깊은 구조를 공유하는 듯했다.
우리는 두 알고리즘이 사실 서로의 쌍대(dual)임을 보여주는 정식을 제시한다. 직관적으로, 차이는 트레이싱이 살아 있는 객체, 즉 ‘물질(matter)’에서 동작하는 반면, 참조 카운팅은 죽은 객체, 즉 ‘반물질(anti-matter)’에서 동작한다는 데 있다. 트레이싱 수집기가 수행하는 모든 연산에 대해, 참조 카운팅 수집기가 수행하는 정확히 대응되는 ‘반(anti-)연산’이 존재한다.
이게 바로 내가 필요로 하던 답이었다! 살아 있는 객체 전부를 방문하는 대신, 나는 죽은 것들만 방문하고 싶었고, 참조 카운팅이 그걸 가능하게 해 주었다.
그래서 문서의 모든 노드에 대해 참조 카운트를 유지하는 방법을 추가했다. 새 문서를 만들어 낼 때는 이전 루트 노드의 참조 카운트를 감소시키는데(그 뒤로는 항상 0이 된다), 그러면 자식들의 참조 카운트도 재귀적으로 감소시키고, 계속 그렇게 내려간다. 이렇게 하면 문서의 대부분 노드를 방문하지 않고도, 재사용되지 않은 노드를 정확히 찾아낼 수 있다 — 내가 원하던 바로 그것이다.