Haskell로 NES(닌텐도 엔터테인먼트 시스템) 에뮬레이터를 구현하며 겪은 설계 선택, 성능 최적화, 테스트 전략을 정리한다.
URL: https://arthichaud.xyz/posts/funes/
Title: Writing an NES emulator in Haskell
나는 5년 전 Haskell 코드의 첫 줄을 작성했다. 하지만 (박사 과정 연구의 일부로) 매일 Haskell을 사용하기 시작한 것은 1년 반 전부터다. 그래서 Haskell과 함께한 대부분의 시간은 학교 프로젝트(예: JSON 파서, Lisp 인터프리터)와 연구 실험(예: packed-data, type-machine)으로 요약된다. 더 큰 규모의 프로젝트를 Haskell로 진행해 볼 기회는 (아직) 없었다.
Haskell 커뮤니티에는 흥미로운 특징이 하나 있는데, 언뜻 보기엔 함수형 패러다임의 관련성이 분명하지 않은 분야에도 Haskell을 적용한다는 점이다. GitHub에서 조금만 찾아봐도 게임패드 에뮬레이터(monpad)나 CLI 음악 태거(htagcli) 같은 놀라운 프로젝트를 발견할 수 있다.
나도 ‘진짜 하스켈러(real Haskeller)’가 되고 싶었고, 자랑할 만한 멋진 프로젝트를 갖고 싶었다. 그래서 아이디어를 떠올렸다. Haskell로 비디오 게임 콘솔 에뮬레이터를 구현하는 것이 얼마나 현실적인지 보고 싶었다. 주요 ‘연구’ 질문은 다음과 같다:
안전하게 가기 위해, 가장 오래되고 ‘가장 단순한’ 게임 콘솔 중 하나인 Nintendo Entertainment System(aka NES)을 선택했다. 이 콘솔은 최초의 슈퍼 마리오 브라더스와 젤다의 전설이 등장한 플랫폼이다. 그렇게 _FuNes_가 탄생했다. Haskell로 작성한 실험적인 NES 에뮬레이터다. (소스 코드).

이 글에서는 이 작은 모험에서 얻은 경험을 공유한다. 먼저 콘솔의 아키텍처를 빠르게 소개한 뒤, (아주 높은 수준에서) 각 컴포넌트를 어떻게 설계하고 조립했는지 설명한다. 또한 에뮬레이터 성능을 최적화한 방법도 이야기할 것이다. 결론에서는 앞서 제시한 질문들에 답한다.
시작하기 전에 간단한 안내(PSA):
Writing an NES Emulator in Rust 전자책과 nesdev.org 사이트를 추천한다. 영상이 더 좋고 시스템의 복잡함을 맛보고 싶다면 100thCoin의 유튜브 채널을 추천한다.먼저 NES의 _컴포넌트_를 살펴보고, 각각이 무엇을 하며 서로 어떻게 상호작용하는지 이해해야 한다.
가장 이해하기 쉬운 컴포넌트는 중앙처리장치(CPU)다. CPU의 역할은 코드를 읽고 실행하는 것이다. CPU는 4개의 레지스터와, 다음 오퍼코드(즉, 실행할 명령 코드)를 추적하는 프로그램 카운터를 가진다.
메모리 및 콘솔의 다른 컴포넌트와 상호작용하기 위해 CPU는 버스(Bus)1에 연결되어 있다. 버스는 메모리와 상호작용할 때 드라이버처럼 동작하며, 전송된 데이터를 올바른 컴포넌트로 전달한다. 예를 들어 CPU가 주소 0x2000에서 데이터를 읽고 싶다면 버스는 PPU로부터 값을 가져온다. 하지만 CPU가 주소 0x8000에서 읽으면, 버스는 카트리지에서 값을 읽는다.
픽처 프로세싱 유닛(PPU)은 배경과 스프라이트를 그리는 작업, 그리고 스크롤 처리를 담당한다. CPU와 마찬가지로 자체 레지스터와 전용 RAM을 가진다.
콘솔의 마지막 처리 유닛은 오디오(APU) 전용이다. 기술적으로는 APU가 실제로 CPU의 일부이기 때문에 다소 특이한 컴포넌트다. 하지만 대부분의 에뮬레이터는 APU를 독립된 컴포넌트로 구현한다. CPU가 버스를 통해 APU와 상호작용하기 때문이다. APU도 자체 내부 상태를 가진다.
마지막으로 게임 컨트롤러(aka 조이패드(Joypad))와 **카트리지(Cartridge)**가 있다. 다른 것들과 마찬가지로 CPU는 전용 주소 공간에서 데이터를 읽는 방식으로 이들과 상호작용하며, 버스가 해당 주소를 적절한 컴포넌트로 매핑해 준다.
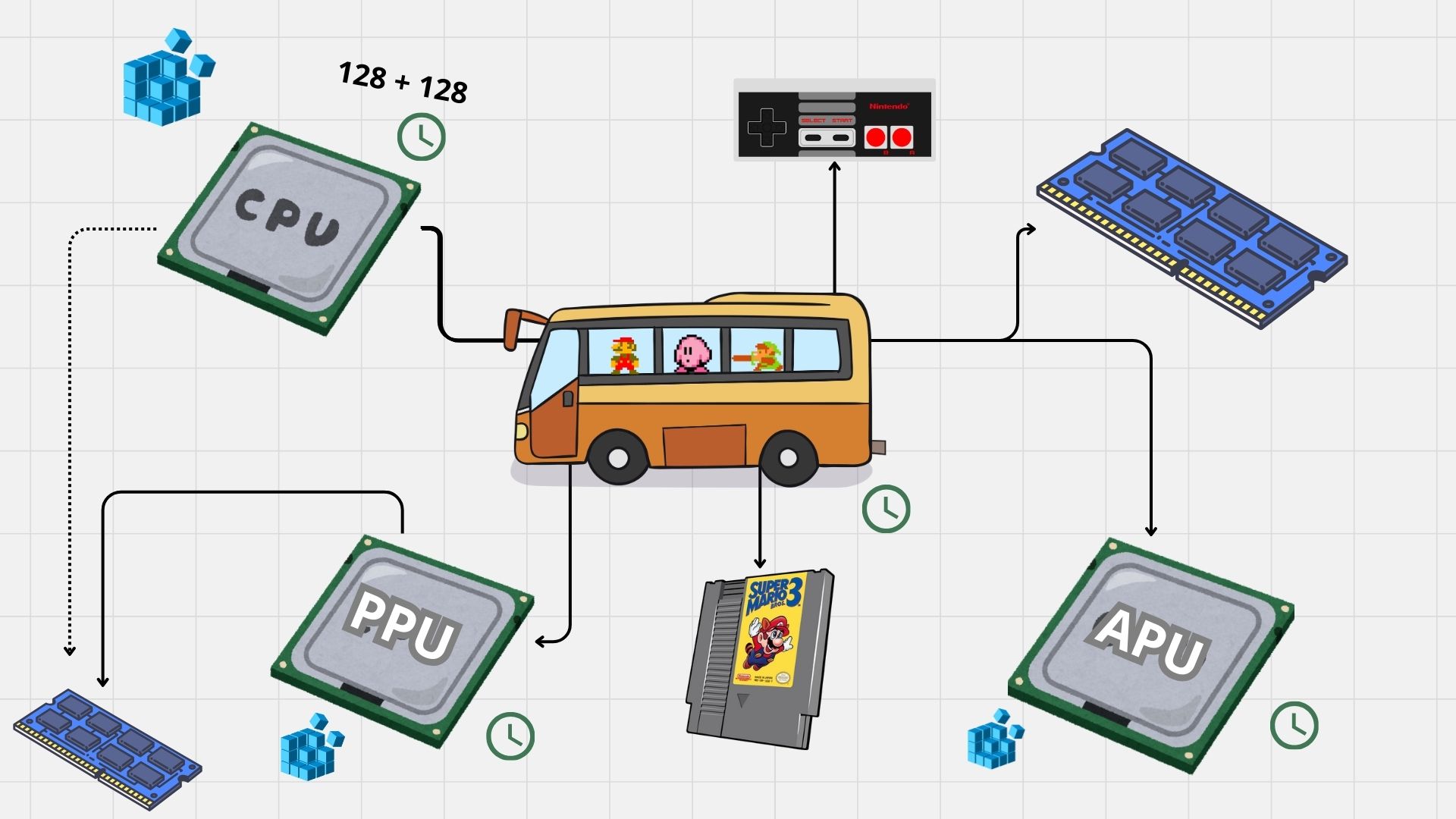 NES의 컴포넌트와 관계
NES의 컴포넌트와 관계
기술적 세부사항을 너무 깊게 파고들지는 않겠다. 다만 마지막으로 언급할 것은 컴포넌트들이 서로에게 _부수 효과(side effects)_를 일으킬 수 있다는 점이다. 예를 들어 PPU나 APU가 CPU의 VRAM(OAM)에서 큰 덩어리의 데이터를 로드하면, CPU는 몇 사이클 동안 멈춘다. 또는 어떤 연산은 CPU 인터럽트를 유발해 CPU가 현재 실행 흐름을 멈추고 특정 명령 시퀀스를 실행하게 만들기도 한다.
이 정도면 에뮬레이터에서의 설계 선택을 이해하는 데 충분할 것이다. 다시 말하지만, 더 궁금하다면 서론에서 링크한 자료를 참고하자.
이전 섹션에서 각 처리 유닛이 자체 내부 상태를 가진다고 했다. 이 상태는 각 틱(tick) (시간의 최소 단위) 이후 갱신된다. Haskell에서 상태를 갱신하는 계산을 모델링하는 가장 흔한 방법은 State 모나드를 사용하는 것이다. 더 간단히 말하면, 상태를 받아 새 상태를 반환하는 함수다.
에뮬레이터에서는 각 처리 유닛의 계산을 대략 다음과 같이 정의했다:
1
2
3
4
-- CPU의 내부 상태
data CPUState = ...
data CPU a = MkCPU (State -> (State, a))
그리고 PU별 계산은 이렇게 정의할 수 있다:
1
2
3
incrementRegisterA :: CPU ()
tick :: APU ()
readStatus :: PPU Byte
앞서 보았듯이 각 처리 유닛마다 상태 객체를 정의한다. CPU의 경우는 다음과 같을 것이다:
1
2
3
4
5
6
7
8
data CPUState = MkC {
registerA :: Byte -- 누산기(accumulator), 1바이트
, registerX :: Byte
, registerY :: Byte
, registerS :: Byte -- 스택 포인터
, status :: StatusRegister
, pc :: Addr -- 프로그램 카운터, 2바이트
}
CPU 계산 내부에서 필드를 읽거나 갱신하기 위해, 순진하게는 다음 함수들을 정의할 수 있다:
1
2
withState :: (CPUState -> a) -> CPU a
modifyState :: (CPUState -> CPUState) -> CPU ()
예를 들어 A 레지스터 값을 1 증가시키는 오퍼코드는 이렇게 구현할 수 있다.
1
2
3
4
inc :: CPU r ()
inc = do
regA <- withState registerA
modifyState $ \st -> st{registerA = regA + 1}
겉보기엔 괜찮다… 마지막 줄 전까지는. 람다가 꽤 장황하다. 복잡한 업데이트의 경우 가독성이 크게 떨어진다.
내 생각에 Haskell은 (기본 제공만으로는) 레코드 다루기에 썩 좋은 언어가 아니다. 다행히 렌즈(lenses)를 사용하면 이를 개선할 수 있다. 약간의 보일러플레이트를 추가하면 상태를 좀 더 명령형 스타일로 업데이트할 수 있는 다양한 연산자를 사용할 수 있다. 렌즈를 사용하면 inc 구현이 즉시 더 좋아진다:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
data CPUState = MkC {
_registerA :: Byte, _registerX :: Byte, -- etc.
}
-- 상태의 각 필드에 대한 렌즈를 생성하는 보일러플레이트
makeLenses ''CPUState
inc :: CPU r ()
inc = do
regA <- use registerA
modifying registerA (regA + 1)
-- 다양한 중위(infix) 연산자를 사용해 더 줄일 수도 있다
inc = do
regA <- use registerA
registerA .= (regA + 1)
-- 또는
inc = registerA %= (+ 1)
-- 또는
inc = registerA += 1
우리의 못생긴 with/modifyState 함수를 쓰는 것보다 훨씬 낫다.
처리 유닛 간 부수 효과를 처리하는 더럽고 빠른 방법은 전역 변수를 사용하는 것이다. 하지만 Haskell은 순수 언어이므로 전역은 금기다.
다만 에뮬레이터는 주로 단일 스레드이기 때문에, 각 처리 유닛에 ‘부수 효과’ 상태를 함께 전달해 특정 부수 효과가 발생해야 하는지 표시할 수 있다. 다행히 계산 모나드를 확장해 이 추가 상태를 함께 운반하도록 만들기 쉽다:
1
data CPU a = MkCPU (State -> SideEffect -> (State, SideEffect, a))
처리 유닛이 다시 제어권을 받았을 때, 모나딕 계산 안에서 이 상태에 쉽게 접근할 수 있다:
1
2
3
4
5
6
7
8
getSEState :: CPU SideEffect
setSEState :: SideEffect -> CPU ()
tick :: CPU ()
tick = do
interrupt <- shouldInterrupt <$> getSEState
when interrupt $ do
setSEState $ \st -> st{shouldInterrupt = False}
물론 렌즈를 사용하면 그 상태와의 상호작용도 더 편하게 만들 수 있다.
실제 NES 하드웨어에서는 당연히 처리 유닛들이 병렬로 실행된다. 하지만 입문용 에뮬레이터는 보통 단일 실행 스레드에 의존한다. 처리 유닛들을 동기화하기 위해 ‘마스터’ 처리 유닛을 정할 수 있다. 이 마스터 PU가 틱 할 때마다 다른 처리 유닛 각각에게 (한 틱 동안) 제어권을 준다. CPU를 마스터 PU로 삼으면, 버스와의 연결을 활용해 버스를 ‘틱 컨트롤러’로 만들 수 있다. 즉, 다른 PU들을 대신 틱하게 하는 역할이다. 구체적 예시는 다음과 같다:
CPU가 VRAM에서 1바이트를 읽고 싶다.
읽기 연산은 1틱이 걸린다. 따라서 CPU가 틱한다.
CPU가 틱할 때, 버스를 통해 다른 PU들이 틱하도록 만드는 함수를 호출한다.
PPU와 APU가 작업을 끝내면 제어권이 CPU로 돌아간다.
CPU는 요청했던 바이트를 받는다.
현실적으로 말하자면, 이런 계산을 함수형으로 모델링하는 것은 이상적이지 않다. 계산의 각 단계마다 사실상 새 상태 객체를 만들기 때문이다. 게임을 수용 가능한 프레임레이트로 실행할 만큼 에뮬레이터를 빠르게 만들기 위해, 나는 아키텍처의 몇 가지를 손봤다.
첫째, 모든 처리 유닛 계산을 continuation-passing style(CPS)로 재정의했다:
1
data CPU r a = MkCPU (State -> SideEffect -> (State -> SideEffect -> a -> r) r)
추가 타입 파라미터 r에 주목하자. 처음에는 각 CPU 함수마다 타입 파라미터를 추가하는 게 귀찮게 느껴질 수 있지만, 실제로는 비교적 거슬리지 않는다(그리고 다행히도 나는 꽤 초기에 CPS를 채택했다). 다만 가장 짜증나는 부분은 각 xPU 모나드에 대한 클래스 인스턴스를 모두 업데이트해야 한다는 점이다. 변수들을 continuation에 적용해야 해서 코드가 무거워진다.
1
2
3
4
5
instance Applicative (CPU r) where
pure a = MkCPU $ \se bus cont -> cont se bus a
(MkCPU f) <*> (MkCPU a) = MkCPU $ \se bus cont -> f se bus $
\se' prog' f' -> a se' prog' $
\se'' prog'' a' -> cont se'' prog'' $ f' a'
둘째, NES 계산은 Haskell의 지연 평가(laziness)의 이점을 활용하지 않으므로, 상태 객체의 모든 필드를 엄격(strict)하게 만들고 bang pattern을 곳곳에 사용해 스칼라 값이 완전히 평가되도록 할 수 있다. 또는 (말장난하자면) 게을러지게, 컴파일러 옵션 -XStrict를 사용해도 된다 :)
마지막으로, 일부 계산은 결과 값이 당장 필요 없기 때문에 백그라운드에서 실행할 수 있다. 픽셀 버퍼를 렌더링하고 오디오를 믹싱하는 함수가 그 예다. 이런 함수들에 대해서는 호출 연산이 실제로 IO 함수를 호출하도록 만든다. 이 함수는 보통 전용 스레드가 처리할 MVar에 값을 기록한다. 스레드에서 수행된 계산이 값을 반환한다면, 그 값은 출력 MVar에 기록된다. 스레드를 사용한 것이 에뮬레이터 성능 개선에 크게 도움이 됐다.
아래 비디오 데모는 얻어진 속도 향상을 보여준다. 성능이 완벽하진 않지만, 훨씬 수용 가능한 프레임레이트다.
이 비디오에는 오디오가 있다. 재생 전에 볼륨을 낮추자.
단일 스레드 사용
다중 스레드 사용
NES는 오래된 시스템이지만, 그럼에도 복잡한 시스템이다. 따라서 테스트는 필수다.
함수형 패러다임과 순수성의 장점 중 하나는 컴포넌트를 테스트하기 쉽다는 점이다. 따라서 CPU와 PPU를 특정 상태와 NES 명령 시퀀스에 붙여 동작을 테스트하기 쉽다. 단일 오퍼코드에 대한 유닛 테스트는 다음과 같다:
1
2
3
4
5
6
7
it "Push and Pull Register A" $ do
-- Reg A를 푸시하고, 0x10으로 설정한 뒤, 스택에서 복원한다
let program = [0x48, 0xa9, 0x10, 0x68, 0x00]
st = newCPUState{_registerA = 1}
withState program st $ \st' -> do
_registerA st' `shouldBe` 1
_registerS st' `shouldBe` stackReset
개별 오퍼코드를 테스트하는 것은 도움이 되지만, 오퍼코드가 얼마나 많은지(256개)를 생각하면 전부를 철저히 테스트하는 건 시간 낭비다2. 다행히도 NES 개발 및 에뮬레이션 커뮤니티는 에뮬레이터의 동작을 테스트하기 위한 테스트 ROM 모음을 만들어 두었다. 예를 들어 Nestest는 가능한 거의 모든 조합으로 모든 공식 오퍼코드를 실행해(즉, 가능한 부수 효과를 모두 테스트) 각 명령 후 CPU 상태(레지스터, 프로그램 카운터 등)를 추적한 로그를 제공하는 NES ROM이다. 에뮬레이터에 로거를 주입해 비슷한 로그 트레이스를 생성할 수 있다면, 기대 로그와 생성 로그의 차이를 찾는 자동화 테스트를 쉽게 작성할 수 있다.
1
2
3
4
5
6
7
C000 4C F5 C5 JMP $C5F5 A:00 X:00 Y:00 P:24 SP:FD PPU: 0, 21 CYC:7
C5F5 A2 00 LDX #$00 A:00 X:00 Y:00 P:24 SP:FD PPU: 0, 30 CYC:10
C5F7 86 00 STX $00 = 00 A:00 X:00 Y:00 P:26 SP:FD PPU: 0, 36 CYC:12
C5F9 86 10 STX $10 = 00 A:00 X:00 Y:00 P:26 SP:FD PPU: 0, 45 CYC:15
C5FB 86 11 STX $11 = 00 A:00 X:00 Y:00 P:26 SP:FD PPU: 0, 54 CYC:18
C5FD 20 2D C7 JSR $C72D A:00 X:00 Y:00 P:26 SP:FD PPU: 0, 63 CYC:21
C72D EA NOP A:00 X:00 Y:00 P:26 SP:FB PPU: 0, 81 CYC:27
로그 트레이스 일부
다른 ROM들은 처리 유닛의 동작을 테스트하고, 에러를 화면에 직접 표시한다. 예를 들어 100thCoin의 AccuracyCoin 테스트 스위트가 그렇다. 이런 테스트는 자동화하기는 어렵지만, 일부 엣지 케이스나 대안적 동작에 대해 유용한 통찰을 제공할 수 있다.
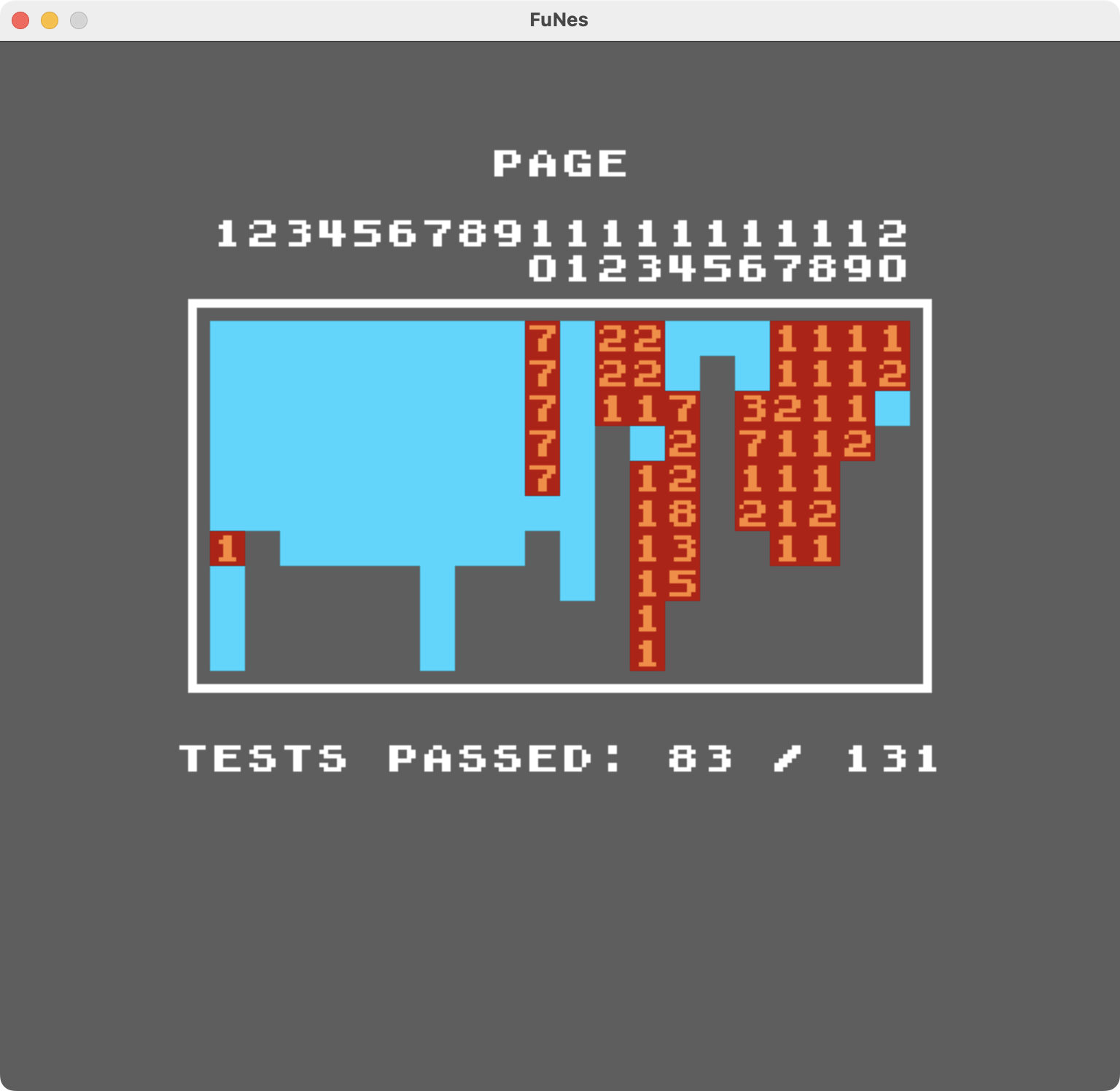 FuNes에 대한 AccuracyCoin ROM 테스트 결과
FuNes에 대한 AccuracyCoin ROM 테스트 결과
요약하자면, 이 프로젝트에서 배운 점은 다음과 같다. 우선 NES는 놀랄 만큼 복잡한 시스템이다. 하지만 온라인에 있는 방대한 문서와 커뮤니티 덕분에 이 프로젝트를 위한 리서치는 매우 즐거웠다.
놀랍게도, 에뮬레이터를 구현하는 데 있어 함수형 패러다임이 방해가 된 적은 없었다. 가장 큰 단점은 전역 상태를 사용할 수 없다는 점이었다. 다행히 추가적인 부수-효과 상태를 함께 전달하는 방식으로 이를 극복할 수 있다. 또한 Haskell이 상당히 고수준 언어인 점을 고려하면, 수용 가능한 프레임레이트를 얻기 위해 금방 코드 최적화를 해야 한다.
결론적으로, 이런 프로젝트에 Haskell이 완전히 나쁜 선택은 아니라고 말할 수 있겠다. 함수형 패러다임과 순수성 덕분에 모델링과 테스트는 쉬워지지만, 실제 코드는 결국 매우 명령형처럼 보이게 된다. 나는 Haskell의 강력한 기능을 제대로 활용하지도 못했다(예: 지연 평가 비활성화). 또한 상태(특히 상태 객체)에 대한 저수준 메모리 관리가 부족하다는 점 때문에, C나 Rust 같은 언어를 선택하지 않은 것을 가끔 후회하기도 했다.