2027년에 ETL 파이프라인은 역사상 어느 해보다도 많이 돌아가겠지만, 데이터 엔지니어링을 규정하던 중심 업무로서의 ETL은 더 이상 유효하지 않다는 주장과, 그 자리를 ‘컨텍스트 아키텍처’가 대체한다는 관점을 탐구한다.
More ETL 파이프라인이 2027년에 역사상 어느 해보다도 더 많이 실행될 것이다. AI는 어떤 데이터 엔지니어 팀이 손으로 작성할 수 있는 양을 뛰어넘어 더 많은 추출 작업, 더 많은 변환 로직, 더 많은 로딩 루틴을 생성할 것이다. ETL의 총량은 폭발적으로 늘어날 것이다.
그리고 ETL은 여전히 죽었다.
라틴어가 죽은 방식—아무도 쓰지 않는—으로 죽은 게 아니다. 유선전화가 죽은 방식—여전히 작동하고 수백만 대가 존재하지만, 누구도 그것을 중심으로 커뮤니케이션 전략을 짜지 않는—으로 죽었다. ETL은 데이터 엔지니어링을 규정하는 핵심 작업으로서 죽었다. 우리가 채용을 하고, 커리어를 쌓고, 팀을 조직하는 대상인 그 ‘일’로서 죽었다. 파이프라인은 계속 돈다. 그러나 그 위에 세워진 직업적 정체성은 살아남지 못한다.
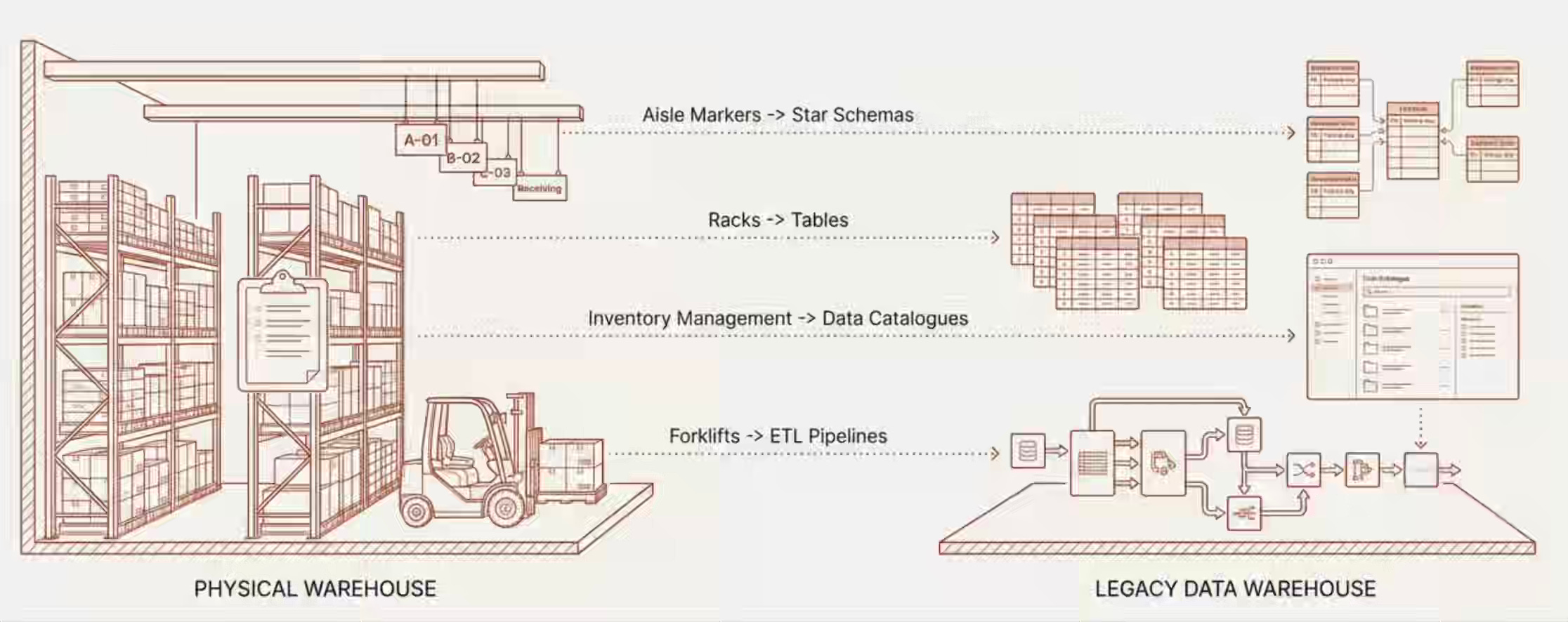
우리는 그것을 문자 그대로 데이터 _warehouse_라고 불렀다. 그리고 그건 단지 이름만 그런 게 아니었다—우리는 물리적 창고의 운영 모델 전체를 디지털 세계로 복제했다. 랙은 테이블이 되었고, 재고 관리는 카탈로그가 되었고, 지게차는 ETL 파이프라인이 되었고, 현장 작업자는 데이터 엔지니어가 되었고, 교대 감독은 애널리틱스 리드가 되었다.
우리가 만든 모든 기법—스타 스키마, 서서히 변화하는 차원(slowly changing dimensions), 메달리온 아키텍처, 컨폼드 차원(conformed dimensions)—은 물리적 창고의 통로 표지와 선반 라벨이 하는 것과 같은 목적을 수행했다. 즉 _인간_이 들어와서 필요한 것을 찾고, 꺼내서 가져갈 수 있도록 돕는 것이다.
데이터 모델링은 인간이 발견할 수 있도록 정보를 조직한다. 데이터 카탈로그는 인간이 탐색할 수 있도록 길찾기(wayfinding)를 제공했다. 메달리온 아키텍처는 인간이 각 스테이션에서 데이터를 검사하고 검증하는 피크-팩-십(pick-pack-ship) 조립 라인을 만들었다. 네이밍 컨벤션—fact_orders, dim_customers—은 인간이 한눈에 선반을 읽을 수 있게 하는 표지판 역할을 했다.
모든 설계 결정은 인간의 인지에 최적화되어 있다. 그리고 나서 운영자가 바뀌었다.
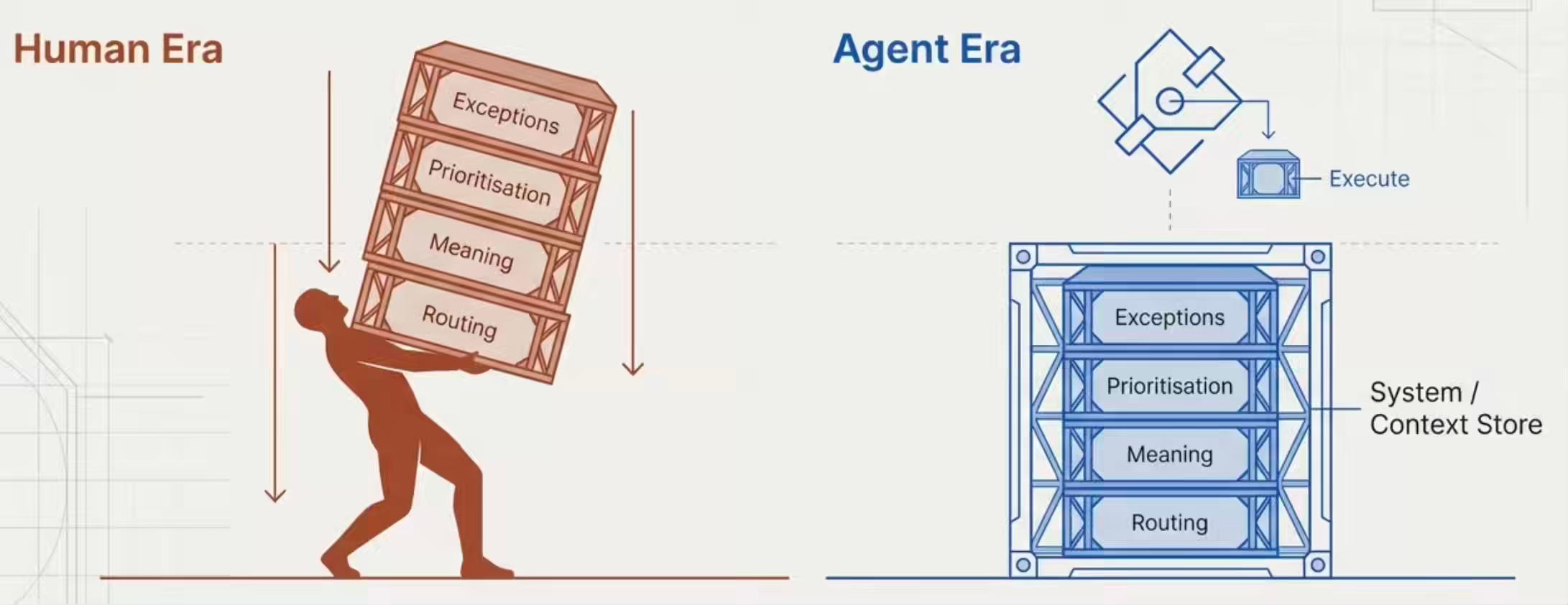
Amazon이 **Kiva 로봇**을 배치했을 때, 그들은 인간의 작업을 일대일로 대체하지 않았다. 그들은 다른 운영자를 중심으로 **창고 전체를 재설계**했다.
인간을 위해 지어진 물리적 창고는 인간이 걸을 공간이 필요했기 때문에 통로가 넓었다. 인간이 물건이 어디 있는지 기억해야 했기 때문에 품목을 논리적으로 묶었다. 인간에게는 인체공학적 제약이 있으므로 수요가 높은 제품을 눈높이에 배치했다. 인간에게는 길찾기가 필요하므로 곳곳에 표지판을 붙였다.
로봇 창고는 그 모든 것을 버렸다. 로봇은 어깨 너비가 필요 없기 때문에 통로는 좁아졌다. 로봇에는 인체공학적 한계가 없기 때문에 선반은 바닥부터 천장까지 올라갔다. 로봇은 기억이 아니라 좌표로 탐색하므로 논리적 그룹화는 불필요해졌다. 로봇은 표지판을 읽지 않고 지시를 읽기 때문에 표지판은 사라졌다.
하지만 가장 큰 이득은 물리적이 아니었다. _인지적_이었다. 인간 창고 작업자는 위치를 기억하고, 동선을 결정하고, 피킹 우선순위를 매기고, 예외를 머릿속으로 처리하는 등 막대한 인지 부하를 짊어졌다. 로봇은 그 인지 부담을 완전히 제거했다. 창고는 더 빨리 움직였을 뿐만 아니라, 어떤 인간 현장 운영도 감당할 수 없는 복잡성을 처리할 수 있는 근본적으로 다른 시스템이 되었다.
이 관점으로 우리의 데이터 웨어하우스를 보자.
**스타 스키마와 차원 모델링**은 인간 분석가가 테이블 간 관계를 시각화할 수 있게 존재한다. 인간은 별 모양을 봐야 한다—중앙의 팩트 테이블과 바깥으로 방사되는 차원들. 에이전트는 별이 필요 없다. 각 엔터티가 무엇을 의미하고 엔터티들이 어떻게 연결되는지에 대한 검증된 시맨틱 정의가 필요하다.
데이터 카탈로그는 디지털 표지판이다. 우리는 인간이 웨어하우스에 무엇이 있는지 둘러보고 발견해야 했기 때문에 그것을 만들었다. 에이전트는 인간이 통로를 걷듯 카탈로그를 브라우징하지 않는다. 에이전트는 검증된 의미를 질의한다.
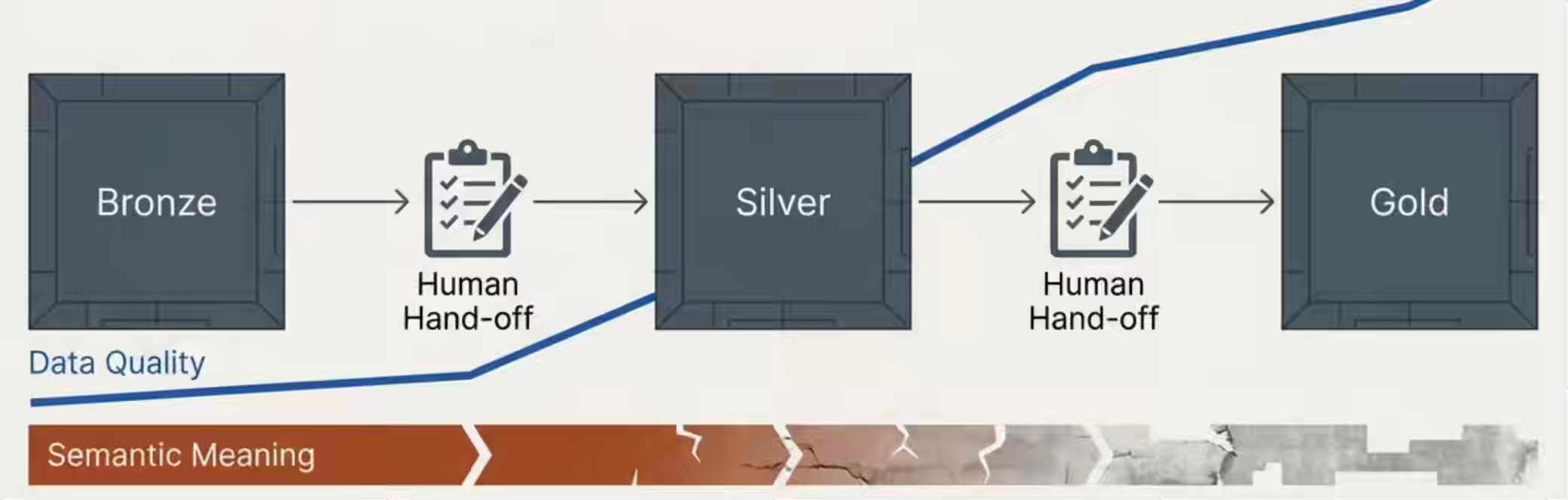
메달리온 아키텍처—Bronze에서 Silver, Gold로—는 각 스테이션마다 인간의 검사를 전제로 설계된 조립 라인이다. 원시 데이터가 도착하고, 점진적으로 정제되며, 소비 가능한 형태로 도달한다. 각 스테이션은 인간이 데이터를 검사하고, 검증하고, 다음으로 넘길 것을 가정한다. 그리고 각 인수인계 지점에서 맥락은 닳아 없어지며—파이프라인 안에서 조용히 진행되는 전화 게임처럼—원래의 의미는 조금씩 더 붕괴한다.
우리는 데이터 웨어하우스의 모든 계층을 인간의 인지적 제약에 맞춰 최적화해 왔다. 그리고 물리적 창고와 마찬가지로, 바로 그 최적화가 운영자가 바뀌면 제약이 된다.
이 점은 정확하게 말하고 싶다. 부정확한 비유는 우리 업계가 반쪽짜리 진실 위에 10년짜리 과대광고 사이클을 쌓게 되는 방식이기 때문이다.
이 비유는 _탐색과 발견_에 대해서는 강력하게 성립한다. 물리적 창고는 인간이 길찾기할 수 있도록 선반을 조직했다. 데이터 웨어하우스는 인간이 질의할 수 있도록 테이블을 조직한다. 로봇은 통로 표지판이 필요 없다. 에이전트는 데이터를 찾기 위해 스타 스키마가 필요 없다. 이 부분은 깔끔하게 대응된다.
하지만 여기서 깨지는 지점이 있다. 물리적 상품은 어떻게 보관하든 의미가 바뀌지 않는다. 신발 상자는 A3 선반에 있든 Z9 선반에 있든 신발 상자다. 데이터는 다르다. 데이터를 어떻게 구조화하느냐가 어떤 질문을 할 수 있는지를 형성한다. 정규화 스키마는 비정규화 스키마와는 다른 분석 패턴을 가능하게 한다. 서서히 변화하는 차원은 스냅샷 테이블이 파괴해 버리는 시간적 맥락을 보존한다.
에이전트가 운영하는 데이터에서도 구조는 여전히 중요하다. 다만 다른 목적을 위해 봉사한다. 인간의 탐색—“데이터를 어떻게 찾지?”—을 위해 조직하는 대신, 에이전트의 운영—“이 작업을 위해 이 에이전트가 어떤 데이터와 맥락을 필요로 하지?”—을 위해 조직한다. AI 도구가 범위가 정해진 작업 폴더(scoped working folder)에서 동작하는 방식을 떠올려 보라. 파일시스템을 에이전트 친화적 레이아웃으로 재구성하지 않는다. 에이전트에게 잘 정의된 경계를 주고, 그 안에서 동작하게 한다. 구조는 탐색적에서 운영적으로—선반 라벨에서 접근 경계로—이동한다.
나는 Ralph Kimball이 은퇴하기 전에 마지막으로 가르친 수업을 들었다. 당시 인기 있던 HBase와, 서서히 변화하는 차원을 처리하기 위한 버저닝(versioning) 개념을 둘러싼 생생한 대화를 기억한다. 나는 차원 모델링을 충분히 내면화해서 무엇이 영속적인 부분이고 무엇이 시대의 산물인지 구분할 수 있게 되었다.
Kimball은 스타 스키마와 서서히 변화하는 차원부터 교육을 시작하지 않았다. Kimball의 차원 모델링 프로세스는 두 단계로 시작한다: _비즈니스 프로세스를 식별하고 그레인(grain)을 선택하라_. 이 단계들은 데이터 엔지니어링에서 가장 근본적인 질문을 던진다—비즈니스는 실제로 무엇을 하며, 어느 수준의 상세도가 중요한가? 이것에 답한 뒤에야 차원, 팩트, 스타 스키마를 설계한다.
1단계와 2단계는 맥락 아키텍처다. 원래부터 그랬다. 비즈니스 프로세스를 식별한다는 것은 조직이 하는 일의 시맨틱 현실을 이해한다는 뜻이다. 그레인을 선택한다는 것은 중요한 의미의 수준을 고르는 일이다. 이런 사고는 **1996**년보다 지금 더 중요해졌다.
3단계와 4단계—스타 스키마, 차원 테이블, 팩트 테이블—는 렌더링 선택이었다. 그것들은 그 시대의 소비자에게 최선의 출력 포맷이었다. 관계형 데이터베이스에 SQL을 작성하는 인간 분석가 말이다. 스타 스키마는 비즈니스 이해를, 당시 사용 가능한 도구로 인간이 질의할 수 있는 구조로 직렬화했다.
소비자는 바뀌었거나 바뀌고 있다. 렌더링도 바뀌어야 한다. 소비자가 AI 에이전트라면, 비즈니스 프로세스와 그레인에 대한 동일한 분석적 사고는 팩트 테이블이 아니라 Context Store 엔트리—검증되고, 버전 관리되며, 질의 가능한 시맨틱 정의—를 만들어 낸다. 사고는 살아남는다. 포맷은 아닐 수 있다.
차원 모델링을 완전히 폄하하는 것은 무지한 일이다. 소비자가 근본적으로 바뀌었는데도 그 출력 포맷에 집착하는 것 역시 마찬가지로 무지한 일이다.
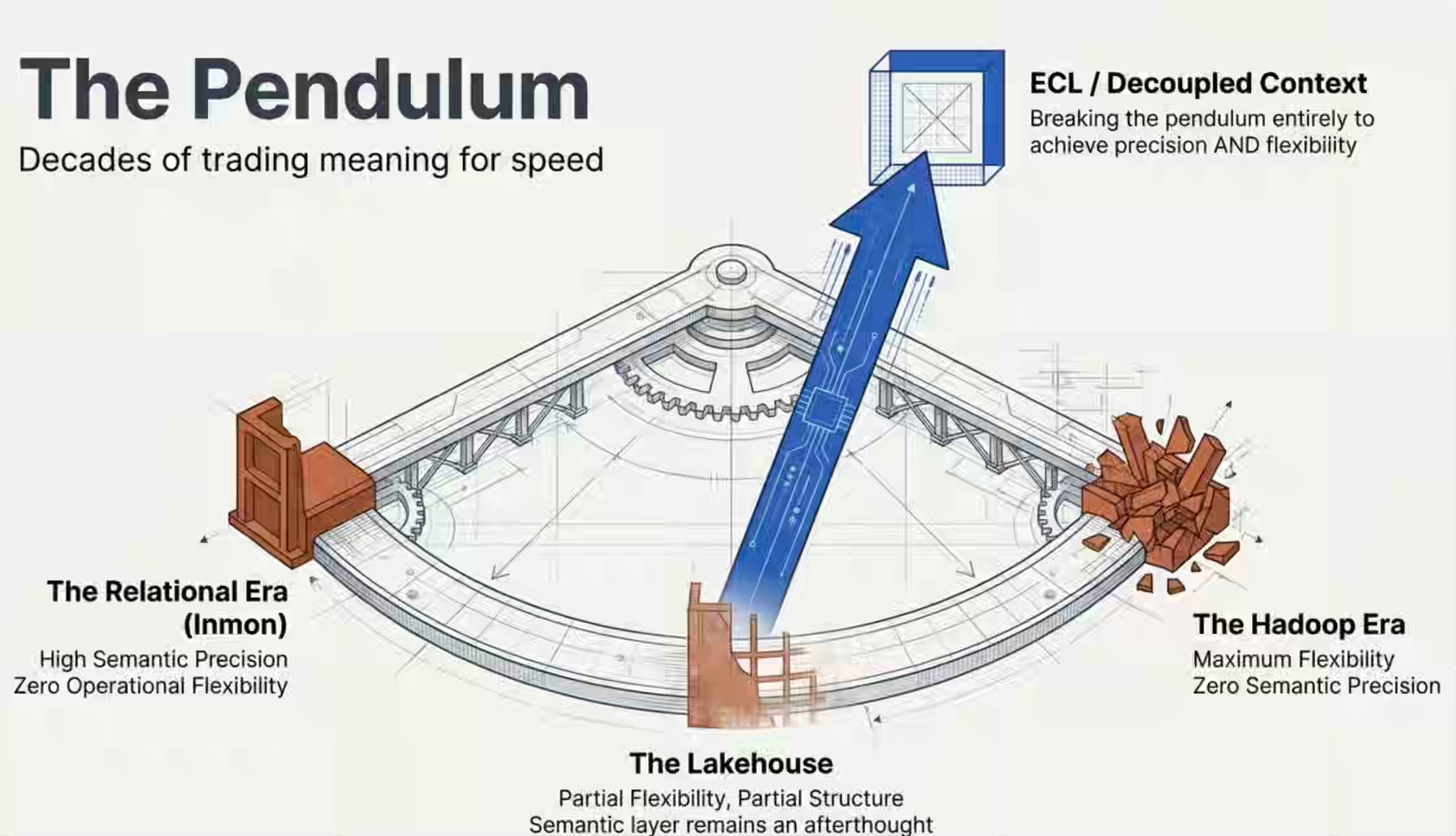
데이터 아키텍처의 각 시대는 같은 긴장을 풀려고 했다: 시맨틱 정밀성 대 운영 유연성.
관계형 시대는 정밀성을 택했다. ERD, 기본 키, 외래 키, 참조 무결성, 제약조건—스키마 자체가 시맨틱 계약이었다. **Bill Inmon의 Corporate Information Factory**는 이를 엔터프라이즈 아키텍처로 공식화했다. 작동했다. 비즈니스 의미를 물리적 구조에 직접 인코딩했다. 하지만 경직되어 있었다. 나는 Hadoop 이전 시대에 어떤 회사 면접에서 현재의 우선순위가 무엇인지 물었던 기억이 있다. 면접관은 스키마 변경을 한 달이 아니라 하루에 구현하는 것을 목표로 하고 있다고 말했다. 그게 최첨단이었다—컬럼 하나 추가하는 데 한 달. 시맨틱 계약이 물리적 구조에 너무 단단히 용접되어 있어서, 하나를 건드리면 모든 것을 건드려야 했기 때문이다.
**Hadoop**의 답은 무식한 힘이었다. 막대한 머신 파워, schema-on-read, 범용 하드웨어—일단 다 집어넣고 나중에 해결하자. 운영의 경직성은 하룻밤 사이에 깨졌다. 그리고 관계형 시대가 구축한 모든 시맨틱 계약도 함께 깨졌다. 우리는 의미를 속도와 맞바꾸었고, 너무 멀리 갔다. 데이터 레이크는 누구도 무엇이 무엇을 뜻하는지 기억하지 못했기 때문에 **데이터 늪(data swamp)**이 되었다—그 의미를 인코딩하던 제약조건이 사라졌기 때문이다.
레이크하우스는 중간 지대를 찾으려 했다. Iceberg, Delta, Hudi—레이크의 유연성에 웨어하우스의 일부 구조를 결합했다. 더 나아졌다. 하지만 시맨틱 레이어는 여전히 뒷전이었다.
누구도 유지보수하지 않는 카탈로그, 문서, 거버넌스 오버레이—왜냐하면 그것이 정확해야만 하는 데 커리어가 달려 있지 않았기 때문이다.
Snowflake의 Open Semantic Interchange 이니셔티브 같은 최근의 시도들조차 이 격차를 인정한다—업계는 이제서야 시맨틱 의미가 도구들 사이를 어떻게 이동하는지 표준화하려 하고 있다.
추는 흔들릴 때마다 한 문제를 다른 문제로 바꿨다. 경직성을 의미없음으로. 의미없음을 부분적 구조로. 그 어떤 것도 달성하지 못한 것은 _디커플링(decoupling)_이었다—물리적 경직성을 요구하지 않는 시맨틱 정밀성. 테이블 구조에 용접되지 않으면서도 데이터와 함께 이동하는 맥락. 몇 초 만에 스키마를 바꾸고, Contextualize 파이프라인을 통해 맥락이 업데이트되며, 경직성 없이 의미는 최신 상태로 유지된다.
그 디커플링을 ECL이 제공한다. 이것은 데이터가 무엇을 의미하는지 아는 것과 그것을 바꿀 수 있는 것 사이에서 선택을 강요하지 않는 최초의 아키텍처다.

회의론자들이 무슨 생각을 하는지 안다. 나도 그렇게 생각해 본 적이 있기 때문이다. 우리는 이 이야기를 예전에도 들었다.
Bill Inmon은 2007년에 문자 그대로 이 주제로 책을 썼다—Business Metadata: Capturing Enterprise Knowledge—시맨틱, 온톨로지, 비즈니스 규칙, 암묵지의 포착을 다룬다. 그는 그것을 포착하기 위한 완전한 방법론을 제시했다. 방법론은 타당했다. 하지만 그때는 경제성이 아직 없었다.
2000년대의 비즈니스 글로서리는 조직 지식을 포착하겠다고 약속했다. 그러나 아무도 업데이트하지 않는 정적 문서가 되었다. 2010년대의 시맨틱 레이어는 통합된 의미의 레이어를 약속했다. 그러나 유지보수해야 할 또 하나의 미들웨어가 되었다. 데이터 카탈로그는 발견 가능성과 거버넌스를 약속했지만, 곧 **쓸모없다는 것이 입증**되었다. 많은 경우 비싼 장식품(shelfware)이 되었다. 엔터프라이즈 지식 그래프는 **연결된 의미**를 약속했다. 대부분은 PoC 단계를 넘지 못했다.
데이터 실무자들의 모든 세대는 같은 북극성을 가리켜 왔다: 비즈니스 의미를 1급 산출물로 포착하라. 그리고 모든 세대는 팀을 “일단 데이터를 가져다 놓고, 의미는 나중에 알아내자”로 끌고 가는 조직적 중력을 과소평가했다.
그럼 이번에는 구조적으로 무엇이 다른가? 한 가지다: 소비자가 관대함에서 무자비함으로 바뀌었다.
소비자가 인간 분석가였을 때, 맥락의 누락은 불편한 일이었다. 분석가는 동료에게 Slack을 보내고, dbt 코드를 읽고, 스탠드업에서 물어보고, 위키를 확인했다. 인간은 사회적 채널을 통해 시맨틱 공백을 메우는 데 놀라울 정도로 능하다. 나쁜 메타데이터는 시스템 실패가 아니라 짜증 난 분석가를 만들었다.
소비자가 AI 에이전트일 때, 맥락의 누락은 대규모로 체계적인 오류를 만든다. 에이전트는 누구에게도 Slack을 보내지 않는다. 부족지식(tribal knowledge)을 읽지 않는다. rev_adj라는 컬럼을 보고 최선의 추론을 한 다음, 행동한다—자신감 있게, 일관되게, 그리고 잠재적으로는 모든 다운스트림 의사결정에 걸쳐 틀리게. 나쁜 맥락은 좌절을 만들지 않는다. 엔터프라이즈 규모의 환각을 만든다.
처음으로, 맥락이 없는 비용이 그것을 유지하는 비용을 초과한다. 그 경제적 역전이 이전의 어떤 시도에도 없던 것이다. 비즈니스 글로서리가 실패한 이유는 인간이 유지 비용을 떠안았고, 이익은 분산되어 있었기 때문이다. Context Store는 에이전트가 신뢰할 수 있는 결과를 내는지 여부에 따라 성공과 실패가 갈린다—그리고 그 피드백 루프는 즉각적이고, 측정 가능하며, 무시할 수 없다.
무덤은 واقعی로 존재한다. 하지만 경제성은 바뀌었다.
ETL이 묻는 것은 “데이터가 도착했나?”였다. ECL이 묻는 것은 “데이터를 신뢰할 수 있나?”다. 나는 AI 이후의 데이터 엔지니어링에 대한 이전 글에서 **ECL 프레임워크**를 소개했다.
Extract는 남는다. 데이터는 여전히 소스 시스템에서 분석 환경으로 이동한다. 그 작업에는 여전히 신뢰성, 지연, 실패 모드에 대한 엔지니어링 판단이 필요하다. AI는 기계적인 구축을 더 많이 처리한다. 인간은 아키텍처 결정을 내린다.
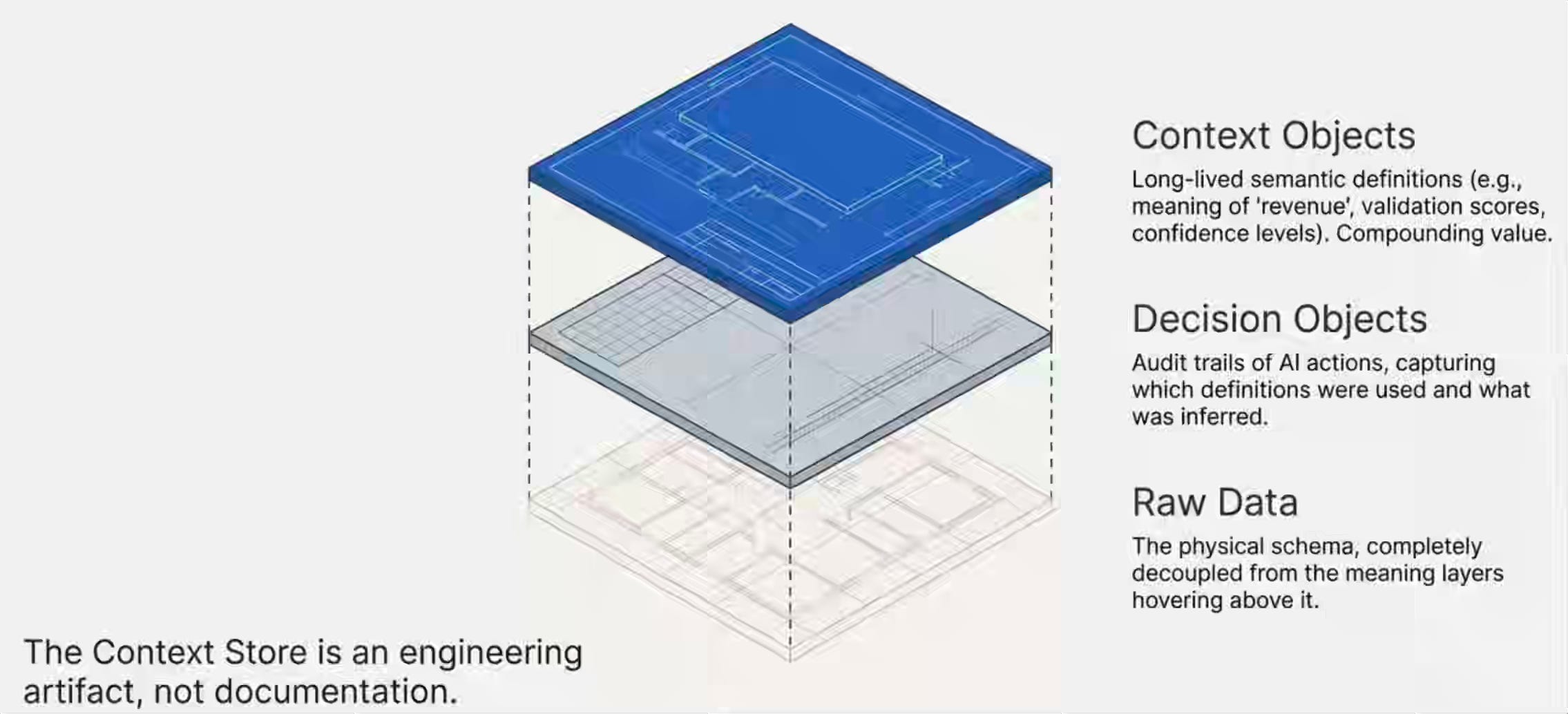
Contextualize가 새로운 무게중심이다. 살아 있는 시맨틱 맥락의 저장소를 구축하고 유지하는, 전용의 에이전틱(agentic) 파이프라인. 그것은 문서가 아니다. 카탈로그도 아니다. 트리거 모델, 검증 레이어, 스토리지를 자체로 가지는 엔지니어링 산출물—Context Store다.
Context Store에는 두 가지 유형의 객체가 들어간다. 컨텍스트 객체(context objects)는 오래 지속되는 시맨틱 정의—“revenue”가 무엇을 의미하는지, 누가 그 정의를 언제 어떤 신뢰 수준으로 검증했는지—를 포착한다. 이런 복합물은 시간이 갈수록 가치가 증가한다. 의사결정 객체(decision objects)는 에이전트가 맥락을 바탕으로 행동할 때 만들어 내는 것—어떤 정의를 사용했는지, 무엇을 추론했는지, 무엇을 추천했는지—을 포착한다. 이것은 감사 추적(audit trail)을 만든다.
Link는 데이터 환경 전반에서 엔터티를 연결한다—그리고 Model Context Protocol (MCP) 같은 새로운 표준이, 데이터를 옮기지 않고도 에이전트가 데이터에 접근하는 방식을 표준화하기 시작했다. 단순한 테이블 조인만이 아니라—시스템 전반의 비즈니스 엔터티 간 시맨틱 관계다. CRM의 고객은 제품의 사용자에 연결되고, 지원 도구의 세션에 연결된다. 이를 그래프로 구현하든, 매핑 테이블로 구현하든, 마크다운 파일로 구현하든 덜 중요하다. 중요한 것은 그 연결이 검증되어 있고 시맨틱 관계가 명시적이라는 점이다.
그리고 데이터는 본질적으로 사회적 성격을 띠므로, 이것을 한 번에 다 만들지 않는다. 하나의 비즈니스 플로우부터 시작한다. 하나의 핵심 테이블부터. 데이터에 대한 통제력이 있고, 프로듀서에게 의미에 대한 책임을 물을 수 있는 곳에서는 early bind를 한다. 책임 경계 밖에서 들어오는 데이터—서드파티 피드, 문서화되지 않은 내부 시스템, 필드의 의미를 알던 사람이 5년 전에 떠난 레거시 데이터—에는 late bind를 한다. 단 하나의 테이블이라도 잘 contextualize되면, 다음 테이블과 연결되고, 그 다음과 연결되면서 복리처럼 가치가 쌓이기 시작한다.
로보틱스에 저항한 물리적 창고 작업자들은 일자리를 지키지 못했다. 그들은 자신의 전환을 늦췄을 뿐이다. 로봇 코디네이션, 시스템 설계, 예외 아키텍처로 이동한 사람들은 지게차를 몰던 때보다 더 가치 있고, 더 전략적이며, 운영의 더 중심적인 위치에 있게 되었다.
데이터를 한 버킷에서 다른 버킷으로 옮기는 일에 정체성을 구축했던 데이터 엔지니어들은, 그 정체성이 한동안 압박을 받아 왔음을 느꼈을 것이다. 그 압박은 사라지지 않는다. AI가 당신의 Spark 잡을 쓸 것이다. AI가 당신의 dbt 모델을 생성할 것이다. AI는 더 많은 파이프라인을 구축할 것이다—당신 팀이 10년 동안 만들 수 있는 양보다 1년 만에.
하지만 AI는 당신 조직에서 “revenue”가 무엇을 의미하는지 결정할 수 없다. 프로듀싱 팀과 컨슘िंग 팀 사이의 데이터 계약을 협상할 수 없다. 특정 비즈니스 문제를 다루는 에이전트에 적절한 수준의 맥락을 설계할 수 없다. 시맨틱 정의가 조직에 붙도록 만드는 조직적 합의를 구축할 수 없다. 그 일에는 조직의 지식, 크로스펑셔널 조율, 아키텍처적 판단이 필요하다. 그 일이 바로 컨텍스트 아키텍처다.
데이터 엔지니어의 가치는 파이프라인 신뢰성에서 시맨틱 신뢰성으로 이동한다. “잡이 돌았다”에서 “의미가 맞다”로. 창고 바닥을 운영하는 일에서 로봇 운영을 신뢰할 수 있게 만드는 시스템을 설계하는 일로.
프런티어는 진짜로 열려 있다. 아직 아무도 이걸 다 풀어내지 못했다. 의미의 아키텍처—단지 이동의 메커니즘이 아니라—에 투자하는 실무자들이 앞으로 10년 동안 이 분야를 정의할 것이다.
ETL은 죽었다. 컨텍스트 아키텍트 만세.
모든 권리 보유, Dewpeche Private Limited. 정보 제공 목적의 링크를 제공했으며, 어떤 보증 또는 지지를 시사하지 않는다. 이 뉴스레터에 표현된 모든 견해는 나의 개인 견해이며, 현재/과거/미래 고용주의 의견을 대변하지 않는다.