엘릭서에서 흔히 말하는 “let it crash”라는 문구가 오해를 낳고 나쁜 습관을 부를 수 있다는 점을 짚으며, 언제 크래시를 허용하고 언제는 사용자 경험을 위해 오류 상태를 표현해야 하는지, 그리고 BEAM의 진짜 강점이 ‘죽을 수 있음’이 아니라 ‘언제든 다시 시작할 수 있음’임을 설명한다.
이 글은 엘릭서에 대한 오해를 다루는 연재의 첫 번째 글입니다. 여기 적힌 것은 제 개인적인 의견입니다. 이 글이 논의를 촉발하고, 그 결과 우리 모두가 무언가를 배우게 되길 바랍니다.
“let it crash”라고 흔히 말하는 엘릭서 프로그래머들에게: 이 표현은 외부인과 초보자에게 잘못된 인상을 주고, 이를 오해한 사람들에게는 나쁜 습관을 조장합니다. 제게 결정권이 있다면, 우리는 이 말을 그만 썼으면 합니다.
Let it crash.
Elixir는 BEAM VM 위에서 동작합니다. 이미 익숙하다면 다음 문단으로 넘어가도 좋습니다. 아니라면 필요한 맥락을 조금 덧붙이자면, BEAM에서는 모든 코드가 “프로세스” 안에서 실행됩니다. 이는 일종의 그린 스레드처럼 생각할 수 있습니다. 각 프로세스는 가볍고, 공유 상태가 없는 동시성의 단위입니다. 프로세스들은 메시지 전달로 통신합니다. 프로세스가 처리되지 않은 오류를 만나면 그 프로세스는 종료됩니다. 우리는 슈퍼바이저(보통 그들 자신도 슈퍼바이저에 의해 감시됨)를 사용해, 크래시한 프로세스를 다시 시작합니다.
사람들이 “let it crash”라고 말할 때, 그들은 사실상 애플리케이션 안의 거의 모든 종료된 프로세스가 곧이어 재시작된다는 사실을 가리킵니다. 그렇기 때문에, 예상치 못한 오류에 대해 덜 방어적으로 코드를 작성할 수 있습니다. 엘릭서 코드에서는 try/rescue나 에러 상태에 대한 매칭을 훨씬 덜 보게 됩니다.
엘릭서 프로그래머에게 “let it crash”에서의 “it”은 바로 프로세스입니다. 애플리케이션이 아닙니다.
실제로 엘릭서 애플리케이션은, 다른 시스템이라면 하드 퀏(hard-quit)될 상황에서도, 거의 절대 크래시하지 않습니다.
엘릭서 애플리케이션을 만들지 않은 사람들에게 “let it crash”라는 말은 ‘엉성함’, 사용자 경험이나 가능한 실패 상태를 고려하지 않은 비우아한 코드의 인상을 줍니다. 대부분의 언어에서 패닉이나 크래시는 치명적 사건이며, 어떤 수를 써서라도 피해야 합니다.
경험 있는 엘릭서 개발자에게조차, 관행으로서의 “let it crash”는 뉘앙스를 충분히 반영하지 못해 단순화되며, 실제로 제 책상 위로 올라오는 코드의 품질에 나쁜 영향을 미치는 것을 종종 봅니다.
먼저, 왜 “let it crash”를 해서는 안 되는지 이야기하고, 그다음에 대신 무엇을 해야 하는지 이야기하겠습니다.
소켓 연결 열기, HTTP 요청 수신 또는 송신, 파일 열기, 데이터베이스 연결: 이런 모든 것들은 대개 프로세스에 의해 뒷받침됩니다. 99%의 경우, 그 프로세스는 그러한 작업을 요청한 프로세스에 링크되어 있습니다. 가장 직관적인 예는 웹 서버가 웹소켓으로 통신하는 맥락이며, Phoenix LiveView에 익숙하다면 더욱 그렇습니다.
이제 “let it crash” 철학을 철두철미하게 받아들여, 웹소켓 메시지를 처리하는 코드를 다음과 같이 쓴다고 상상해 봅시다:
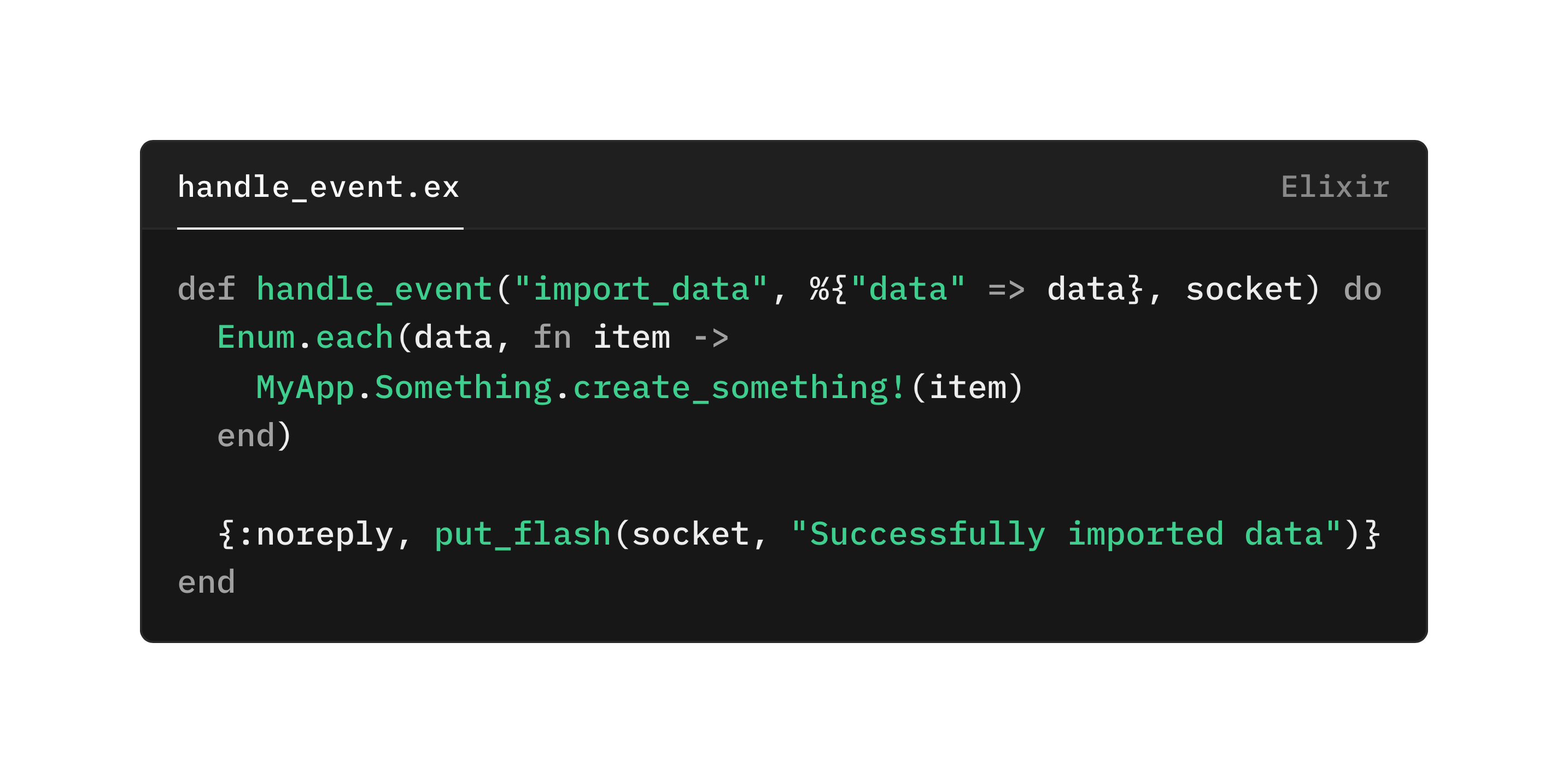
이 코드는 다음과 같은 시나리오에서 프로세스를 크래시시킬 것입니다:
"import_data"가 실패할 때data가 리스트가 아닐 때(정확히는 어떤 형태로든 enumerable이 아닐 때)특히 “애초에 만들어질 수 없어야 하는 잘못된 메시지” 같은 경우에는, 크래시가 오히려 좋은 일일 수 있습니다. 위 목록의 첫 번째, 두 번째, 어쩌면 세 번째 항목들에 해당하는 경우를 맞닥뜨렸다는 것은, 프런트엔드 쪽에 버그가 있음을 시사합니다. 애초에 처리하도록 설계되지 않은 메시지를 누군가가 여러분의 프로세스에 보내고 있는 겁니다. 이때는 크래시가 바람직한 동작일 수도 있습니다.
하지만: 이 끝에는 사용자가 있습니다. LiveView의 경우, 웹소켓은 적어도 사용자 경험의 일부를 주도합니다. 웹소켓을 수립하는 데에는 시간이 듭니다. 사용자 경험은 어떻게 될까요? 무언가 잘못되었다는 플래시 메시지가 보일까요? 일부 UI 상태가 리셋될까요? 이런 것들은 그다지 용납하기 어렵습니다. 이 패턴은 LiveView에만 국한되지 않습니다. 무언가 잘못될 때마다 파일/데이터베이스 연결을 닫고 싶나요? 혹은 다른 값비싼 리소스를 해제하고 싶나요? 순식간에 수천 건의 오류를 마주친다면요? 재시작 비용은 크지 않을까요?
가능한 모든 오류에서 의도적으로 크래시하게 두면, 사용자에게 오류 상태를 표현할 수 없게 되기도 합니다. 위의 예에서는, 다음과 같은 방식이 더 말이 될 수 있습니다:
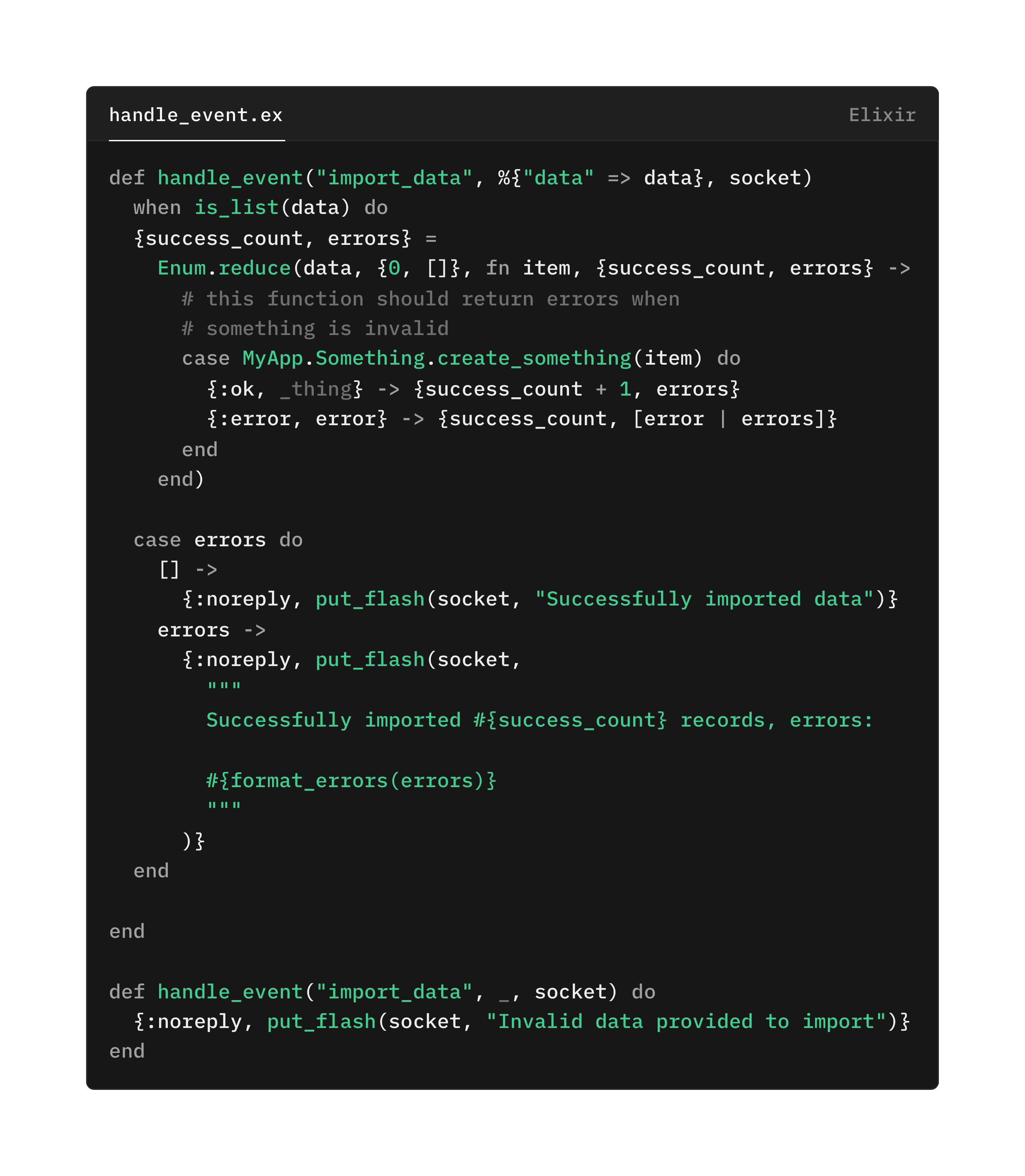
이 예시에서는, 그냥 크래시하고 일반적인 오류만 보이는 대신, 무엇이 잘못되었는지에 대해 사용자가 취할 수 있는 정보를 제공합니다. 우리는 실패한 상태를 표현했습니다.
그렇다고 해도, 실제로는 중용의 길을 택합니다. 구제 불가능한, 전혀 예상하지 못한 상황(예: 잘못된 형식의 "import_data" 명령을 받은 경우)에서는 크래시가 오히려 더 바람직합니다. 프로세스가 복구 불가능한 나쁜 상태에 들어갔고, 그 경위를 알 수 없는 경우에는 크래시를 통해 컴포넌트를 정상 상태로 다시 마운트하고 싶기 때문입니다. 물론 이 시나리오의 UX도 고려해야 하며, 페이지가 우아하게 리마운트되도록 설계해야 합니다.
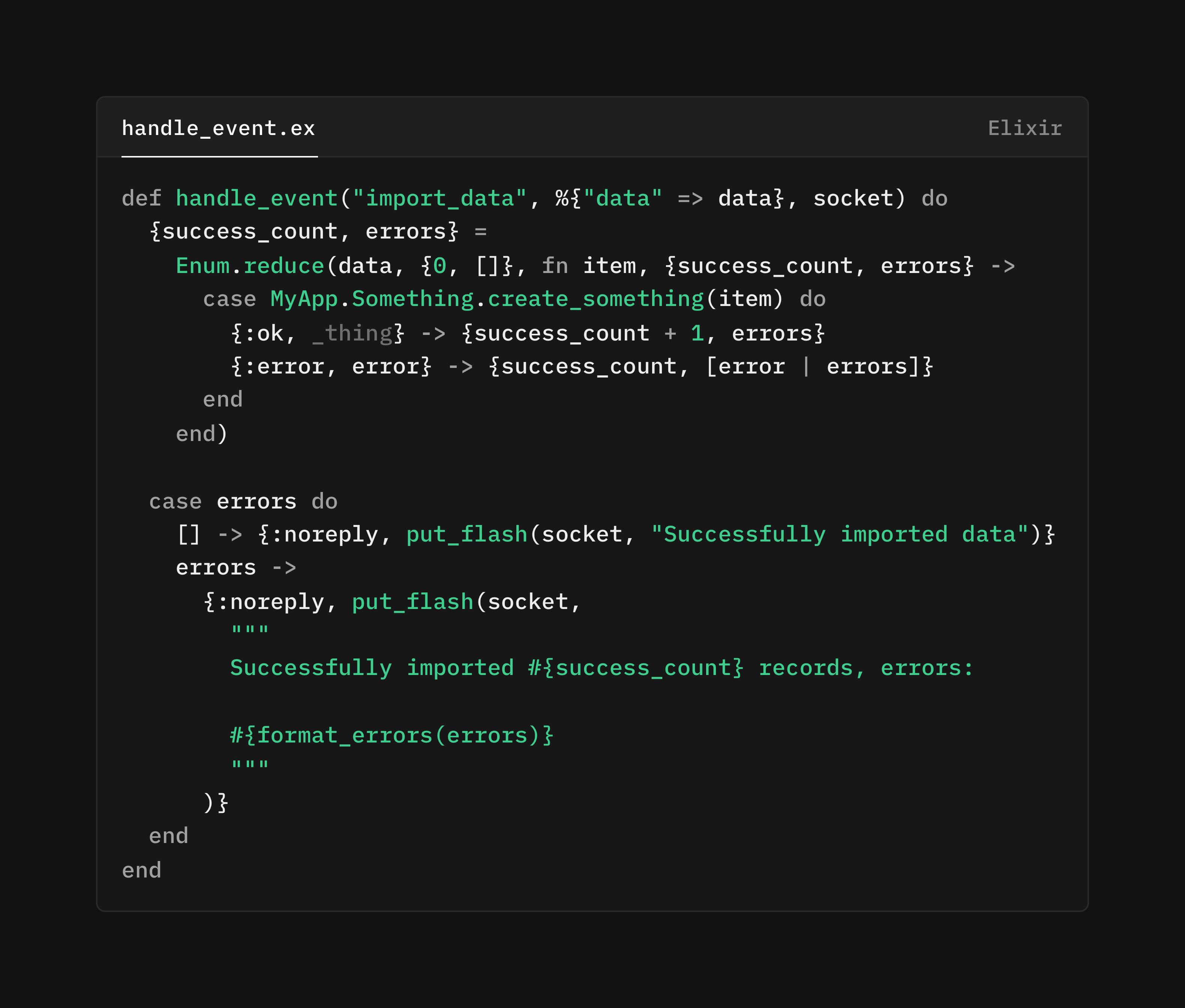
여기서는 알 수 없거나 훼손된 메시지/입력에 대해서는 크래시하고, 그 외에는 사용자에게 검증 오류를 보여줍니다.
그러면, 크래시에는 대가가 있으며, 여기에서 지나치게 단순화된 “let it crash” 마인드를 기본값으로 삼아서는 안 된다는 점을 확인했습니다. 그렇다면 “let it crash”를 말하는 사람들이 완전히 틀렸을까요? 완전히는 아닙니다.
슈퍼바이저와 재시작에 대해 이야기했던 것을 기억하시나요? 여기서 핵심은 프로세스가 크래시하도록 설계되었다는 점이 아니라, 프로세스가 시작하도록 설계되었다는 점입니다. start. 즉, 애플리케이션이 처음 부팅될 때 프로세스 트리를 시작해야 하며, 슈퍼바이저는 그 시점에 크래시한 프로세스를 다시 시작하는 데 필요한 정보를 내장하고 있습니다.
엘릭서 프로그래머에게 이것이 의미하는 바는, 상황이 복구 불가능할 때는 크래시하게 둘 수 있다는 것입니다. 하지만 이것이 의미하지 않는 바는, 프로세스 내부의 모든 오류가 크래시를 유발해야 한다는 뜻은 아니라는 점입니다.
BEAM의 진정한 마법은, 엘릭서에서 실행 중인 어떤 코드 조각에 대해서도, 그 코드가 지역적으로 처리할 수 없는 오류를 처리할 줄 아는 또 다른 상위 수준의 코드가 존재한다는 데 있습니다.
여러분은 ‘무언가 치명적으로 잘못될 수 있다’는 사실을 전혀 인지하지 못하는 코드를 쓸 수 없습니다. 모든 코드는 암묵적으로 “어떻게 초기화할 것인가”라는 단계를 갖고 있고, 그 단계에서 필요한 것들을 수집하고 스스로를 위한 무대를 세울 수 있어야 하기 때문입니다.
이러한 구조들을 설계하는 데 종종 여전히 노력이 필요하지만, 우리는 다른 언어에서는 전문가 팀이나 특수화된 프레임워크가 있어야 겨우 달성하는 것을 거의 공짜에 가깝게 얻고 있습니다.
“let it heal”이 그리 중독성 있는 표현은 아닐지 몰라도, BEAM의 진정한 초능력을 더 잘 포착한다고 생각합니다. 우리의 프로세스가 죽을 수 있다는 점이 아니라, 언제나 다시 살아날 수 있다는 점 말입니다.