DuckLake는 모든 메타데이터를 복잡한 파일 시스템 대신 표준 SQL 데이터베이스에 저장하여, 오픈 포맷(Parquet 등)은 그대로 유지하면서 더 쉽고 빠르고 안정적인 레이크하우스를 제공합니다.
Mark Raasveldt, Hannes Mühleisen
2025-05-27 공개
읽는 데 20분
TL;DR: DuckLake는 복잡한 파일 기반 메타데이터 시스템 대신 표준 SQL 데이터베이스 하나로 모든 메타데이터를 관리하면서도, 데이터는 Parquet 등 오픈 포맷으로 저장합니다. 더 신뢰할 수 있고, 더 빠르고, 더 쉽게 운영할 수 있습니다.
블로그 포스트의 첫 부분은 DuckLake 선언문에서 가져왔습니다. 이어지는 부분은 DuckLake 확장 섹션에서 확인할 수 있습니다.
BigQuery, Snowflake와 같은 혁신적인 데이터 시스템들은 “스토리지-컴퓨트 분리”가 스토리지가 가상화되어 저렴해진 시대에 얼마나 훌륭한 아이디어인지 보여주었습니다. 이 방식에서는 스토리지와 컴퓨트가 독립적으로 확장되어, 거의 읽지 않는 테이블 때문에 비싼 DB 서버를 살 필요가 없습니다.
또한 업계는 데이터 시스템이 하나의 벤더에 종속되지 않도록 Parquet 같은 오픈 포맷 을 사용해야 한다고 요구합니다. 이 새로운 세계에서 수많은 데이터 시스템들이 Parquet와 S3 위에서 노니는 “데이터 레이크”를 만들어왔고, 모두가 행복해졌습니다. 고전적인 데이터베이스가 뭐가 필요하겠어!
하지만 곧, 사람들이 데이터셋을 "변경"하고 싶어한다는 사실이 드러났습니다. 값 추가는 파일을 폴더에 떨어뜨리면 그럭저럭 됐지만, 그 외의 작업은 너무 복잡하고 오류가 나기 쉬운 스크립트로밖에 표현할 수 없었습니다. 정확성이나, 심지어 트랜잭션 보장(Codd 경계선에 있음!)은 아예 고려도 되지 못했습니다.

실제 레이크하우스. 오두막에 더 가까울지도요.
이러한 데이터 변경 요구를 해결하기 위해 Apache Iceberg와 Delta Lake 등 새로운 오픈 표준이 등장했습니다. 이 포맷들은 본질적으로 블롭 스토리지(예: S3)에 오픈 포맷을 잘 쓰면서도 테이블에 변경을 안전히 가할 수 있게끔 고안됐습니다. 예를 들어 Iceberg는 JSON, Avro 파일의 미로 속에 스키마·스냅샷·Parquet 구성 파일 정보를 정의합니다. 결과적으로 "레이크하우스"란 개념이 탄생했고, 데이터 레이크에 데이터베이스 특성을 추가해 다양한 데이터 관리 시나리오(엔진간 데이터 공유 등)가 가능해졌습니다.
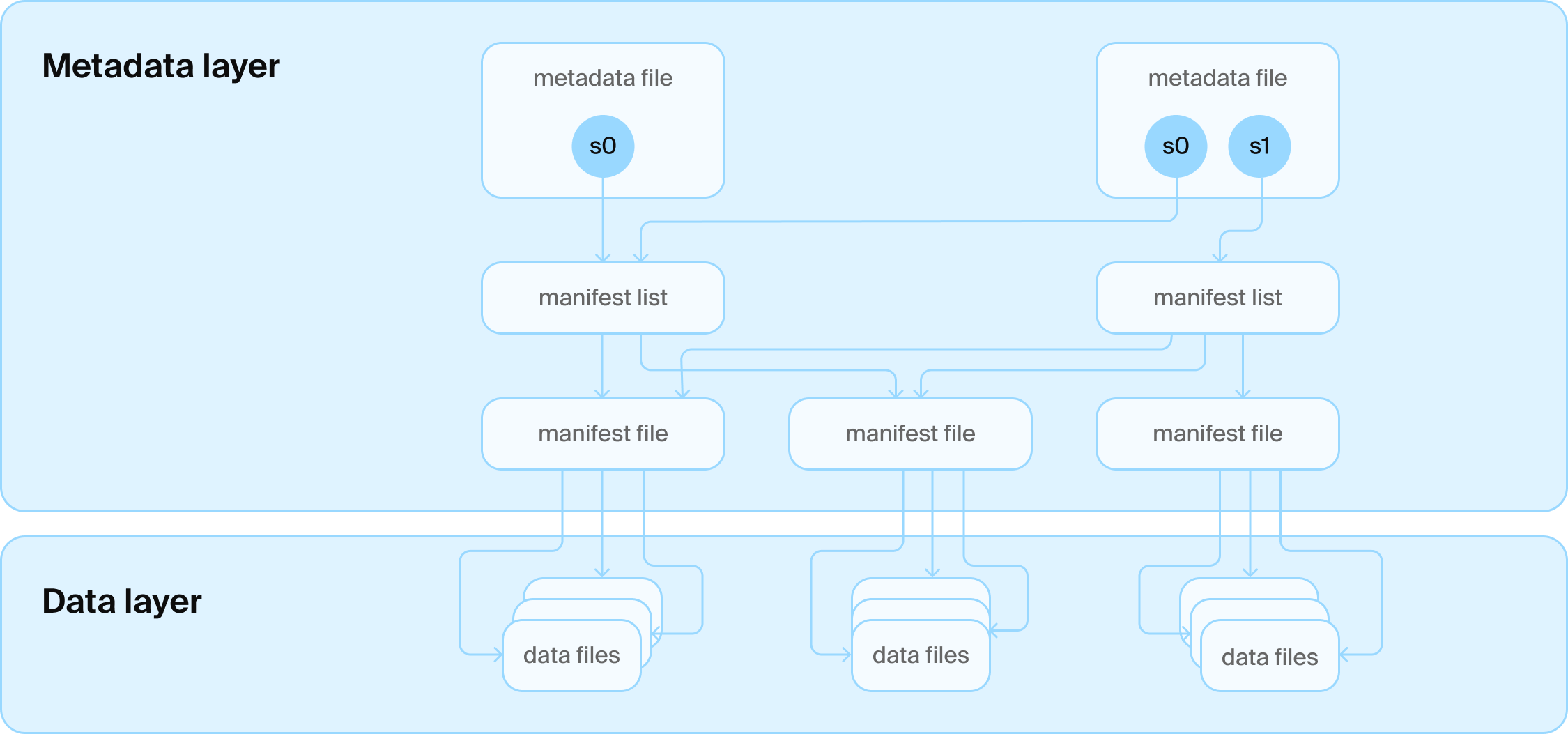 Iceberg 테이블 아키텍처
Iceberg 테이블 아키텍처
하지만 두 포맷 모두 현실의 벽에 부딪혔습니다: blob 스토리지 특유의 일관성 때문에 테이블 최신 버전을 찾는 게 쉽지 않습니다. 원자적으로(ACID의 A) 최신 버전 포인터를 교체하는 것도 어렵습니다. Iceberg, Delta Lake도 본질적으로 하나의 테이블만 다룰 수 있지만, 현실에서는 사람들은 여러 테이블을 관리하고 싶어합니다.
이 문제를 해결하기 위해 또 하나의 기술 계층이 추가됩니다: 다양한 파일 위에 카탈로그 서비스(데이터베이스)를 올렸습니다. 이 서비스는 모든 테이블 폴더 이름을 관리하고, 각 테이블의 현재 버전을 담은 "세상에서 가장 슬픈 테이블"(행이 하나 뿐!)도 관리합니다. 이제 업데이트시에 DB의 트랜잭션 보증을 빌려올 수 있게 되었고 모두가 행복해졌습니다.
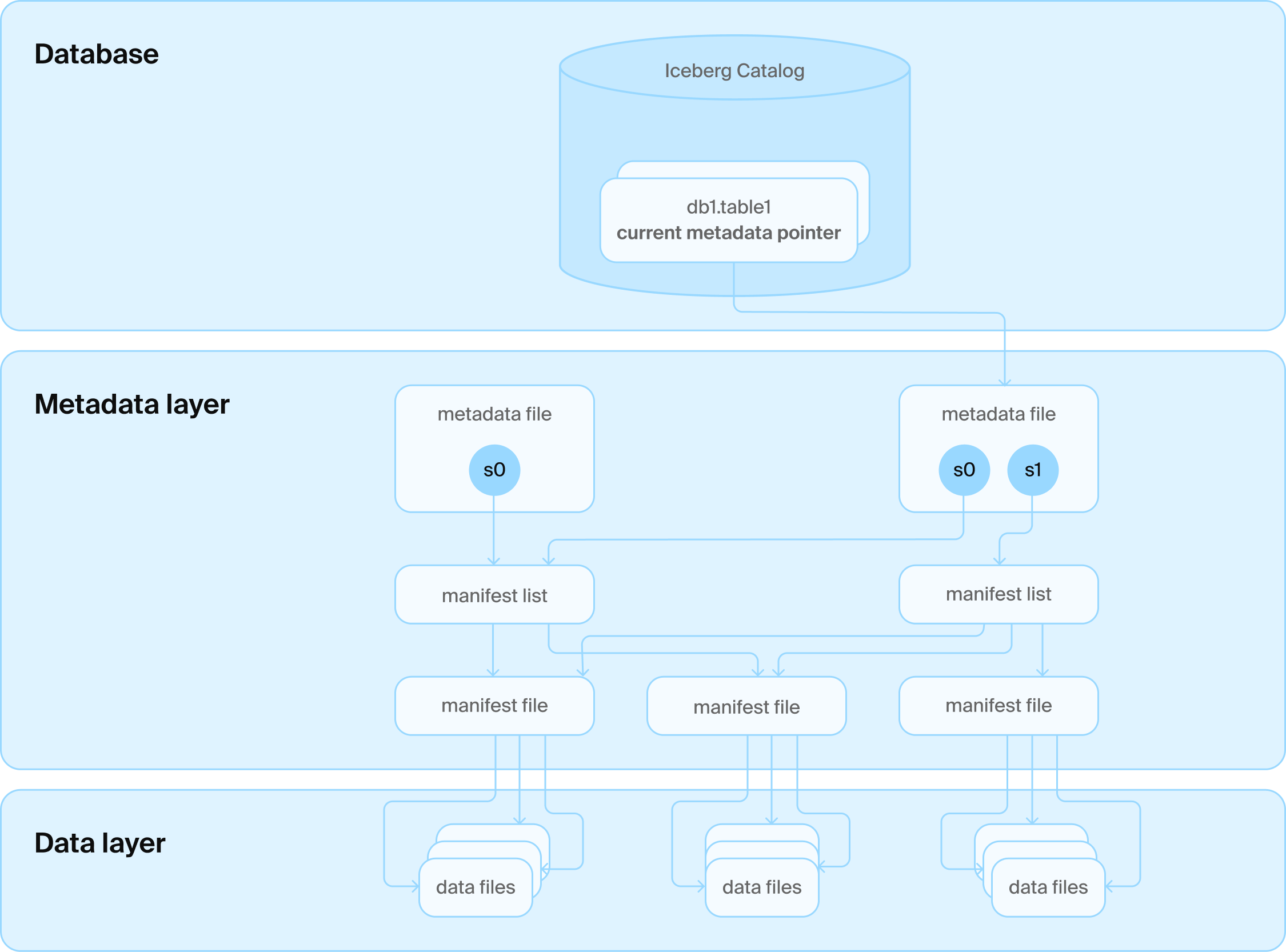 Iceberg 카탈로그 아키텍처
Iceberg 카탈로그 아키텍처
하지만 문제는, Iceberg와 Delta Lake는 본래 “데이터베이스가 필요 없다”고 설계됐다는 점입니다. 설계자들은 모든 정보를 파일 속에 넣으려고 어마어마한 고생을 했죠. 예를 들어 Iceberg의 모든 루트 파일은 전체 스냅샷·스키마 정보를 모두 담습니다. 변동이 있을 때마다 전체 이력을 담은 새 파일이 써집니다. 다른 메타데이터들도 작은 파일 단점 극복을 위해 몰아서, (예: 2단계 매니페스트), 따로 써야 하죠. 데이터에 작은 변경을 가하는 일은 여전히 복잡하고 오픈소스에 실제 구현도 딱히 잘 되어 있지 않습니다. 이 ‘빠르게 변하는 데이터 관리’ 문제만으로도 회사를 차릴 수 있죠. 사실 전문적인 데이터 관리 시스템이 필요하다는 뜻이기도 합니다.
하지만 위에서 보았듯, Iceberg와 Delta Lake도 이미 카탈로그에 일관성을 위해 결국 DB를 도입했습니다. 하지만 다른 설계 제약·기술 스택 전체를 이 근본적인 변화에 맞춰 재점검하진 않았습니다.
DuckDB팀은 데이터베이스를 좋아합니다. DB는 대규모 데이터를 신뢰성 있게 효율적으로 관리하는 놀라운 도구입니다. 어차피 레이크하우스 스택 안에 DB가 들어왔으니, 테이블 메타데이터 관리도 DB를 쓰는 것이 훨씬 합리적입니다! 실제 데이터는 블롭 스토리지에 Parquet 등 오픈 포맷으로 저장하고, 변동 이력을 위한 메타데이터는 DB에서 훨씬 효율적으로 안전하게 관리하면 됩니다! 우연히도, Google BigQuery(Spanner), Snowflake(FoundationDB)도 같은 선택을 했습니다(단, 하단 데이터 포맷은 폐쇄적임).
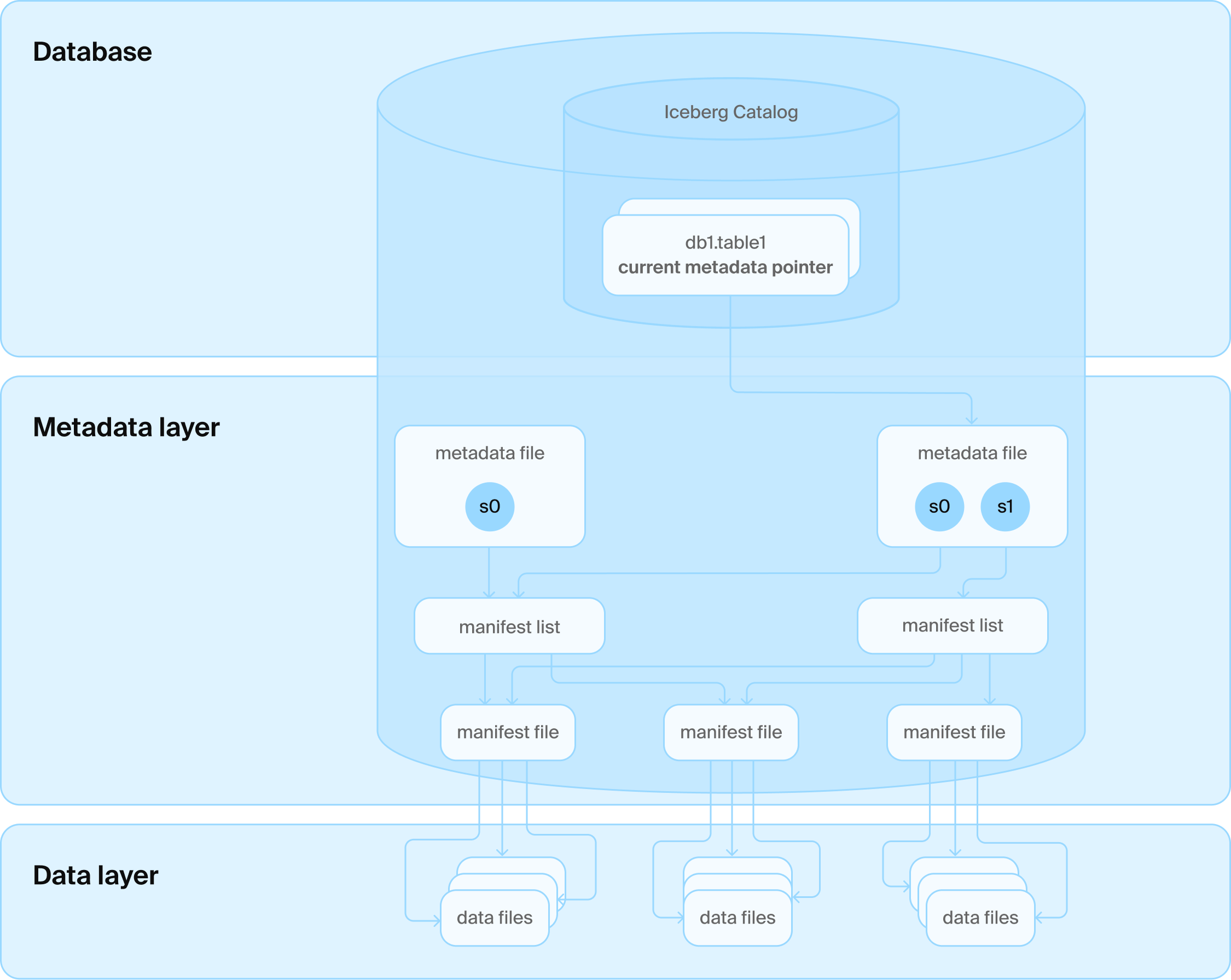 DuckLake 아키텍처: 데이터베이스와 Parquet 파일 몇 개만!
DuckLake 아키텍처: 데이터베이스와 Parquet 파일 몇 개만!
이러한 기존 레이크하우스 아키텍처의 본질적 한계를 해결하기 위해, 저희는 새로운 오픈 테이블 포맷 DuckLake를 만들었습니다. DuckLake는 레이크하우스란 포맷을 아래 두 단순한 진실로 재설계합니다.
DuckLake의 기본 설계는 _모든 메타데이터 구조(카탈로그 및 테이블 메타 포함)를 SQL DB에 저장_하는 것입니다. DuckLake 포맷은 여러 관계형 테이블과 테이블들에 이루어지는 순수 SQL 트랜잭션(스키마 생성·변경·삽입·삭제 등)으로 정의됩니다. DuckLake 포맷은 임의 개수의 테이블 및 교차테이블 트랜잭션을 지원합니다. 또한 뷰, 중첩 타입, 트랜잭션 스키마 변경 등 고급 DB 개념도 지원합니다. 큰 장점 중 하나는 SQL DB의 참조적 일관성(ACID의 C)을 바탕으로 중복 snapshot ID 등 모순이 생길 일이 없다는 점입니다.
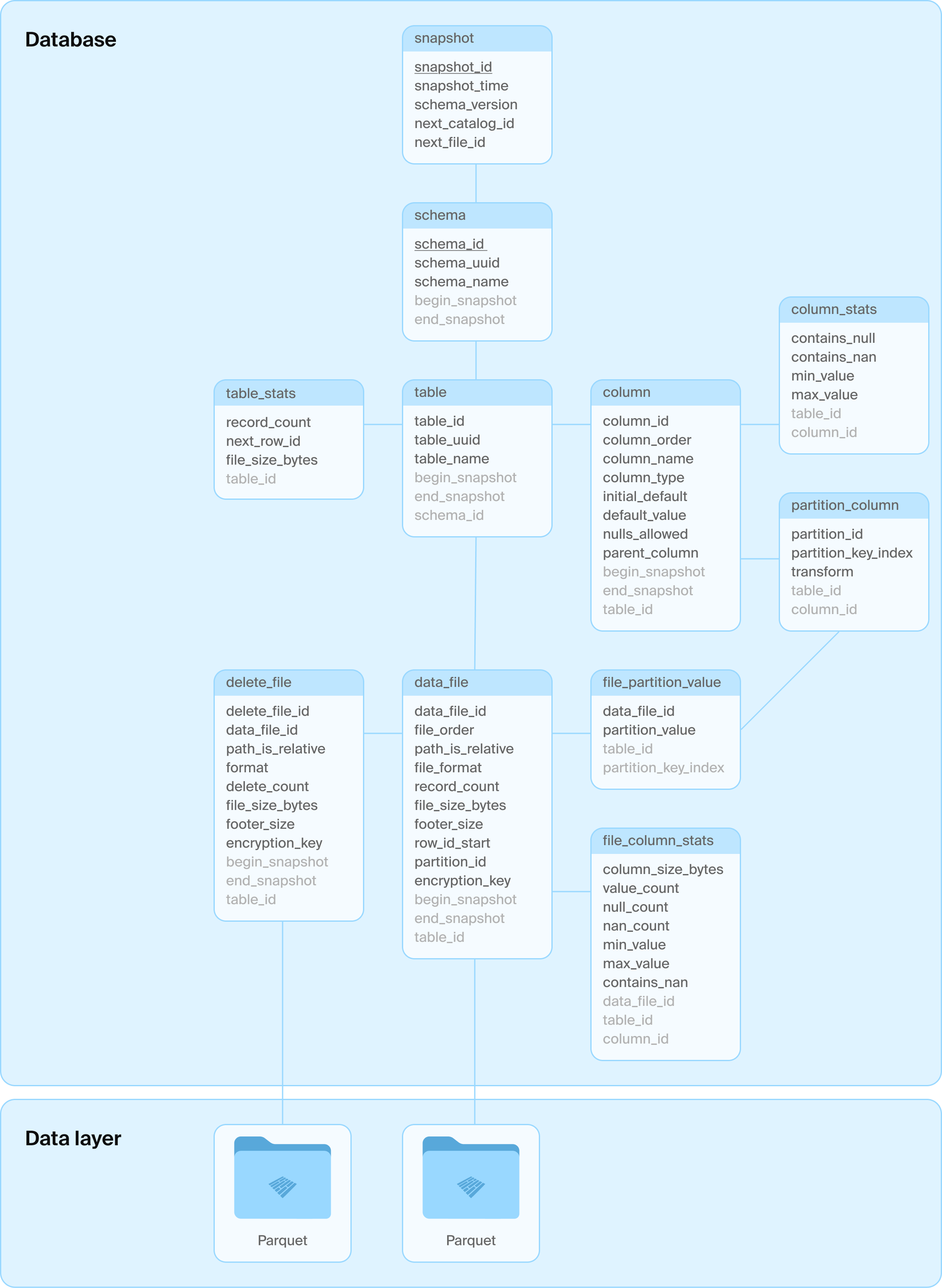 DuckLake 스키마
DuckLake 스키마
어떤 SQL DB를 쓸지는 사용자가 선택할 수 있으나, ACID 보장, primary key, 표준 SQL 지원은 필수입니다. DuckLake 내부 테이블 스키마는 최대한 단순하게 설계되어 호환성을 극대화합니다. 아래에는 기본 스키마 예시가 나옵니다.
새로운 빈 테이블에 아래 쿼리를 실행할 때 DuckLake에서 어떤 쿼리들이 순차적으로 실행되는지 살펴보겠습니다:
INSERT INTO demo VALUES (42), (43);
BEGIN TRANSACTION;
-- (일부 메타데이터 조회 생략)
INSERT INTO ducklake_data_file VALUES (0, 1, 2, NULL, NULL, 'data_files/ducklake-8196...13a.parquet', 'parquet', 2, 279, 164, 0, NULL, NULL);
INSERT INTO ducklake_table_stats VALUES (1, 2, 2, 279);
INSERT INTO ducklake_table_column_stats VALUES (1, 1, false, NULL, '42', '43');
INSERT INTO ducklake_file_column_statistics VALUES (0, 1, 1, NULL, 2, 0, 56, '42', '43', NULL)
INSERT INTO ducklake_snapshot VALUES (2, now(), 1, 2, 1);
INSERT INTO ducklake_snapshot_changes VALUES (2, 'inserted_into_table:1');
COMMIT;
여기서
실제 Parquet 파일 쓰기는 이 쿼리 흐름 직전에 발생합니다. 그러나 추가 데이터 개수와 무관하게 이 쿼리 시퀀스의 비용은 거의 일정합니다.
이제 DuckLake의 세 가지 원칙 단순성, 확장성, 속도를 살펴보겠습니다.
DuckLake는 DuckDB의 설계 철학과 같이 단순하고 점진적 으로 설계됐습니다. 노트북에서 DuckLake를 실행하려면 ducklake 확장을 DuckDB에 설치하면 충분합니다. 개발·테스트·프로토타이핑에 매우 유용하지요. 이때 카탈로그 저장소는 단순히 로컬 DuckDB 파일입니다.
다음 단계는 외부 스토리지 시스템 활용입니다. DuckLake 데이터 파일은 불변(immutable)이어서, 파일을 수정하거나 파일 이름을 재사용할 필요가 없습니다. 즉 거의 모든 저장소 시스템에서 사용 가능합니다. DuckLake는 로컬 디스크, NAS, S3, Azure Blob, GCS 등을 모두 지원하며, 데이터 파일 경로의 prefix(s3://mybucket/mylake/ 등)는 메타데이터 테이블 생성 시 지정합니다.
카탈로그 서버 로 쓰는 SQL 데이터베이스도 표준 ACID·primary key를 지원한다면 어떤 DB든 가능합니다. 기존 조직은 이런 DB 운영 노하우를 이미 갖고 있을 것입니다. 따라서 별도 미들웨어나 소프트웨어 스택은 불필요하며, SQL 데이터베이스만 있으면 충분합니다. 또 최근엔 Postgres, DuckDB 등 호스팅 상품도 매우 많아졌죠. 락인 문제도 거의 없고, 마이그레이션시 테이블 데이터 이전이 필요 없고, 스키마도 간단·표준적입니다.
Avro나 JSON 파일도 없고, 별도 카탈로그 서버/ API도 없습니다. 모두 SQL만 있으면 됩니다. 우리 모두 아는 그 SQL 맞습니다.
DuckLake는 실제로 데이터 아키텍처의 역할 분리를 _3단계_로 더 명확히 합니다. 저장소, 컴퓨트, 그리고 메타데이터 관리입니다. 저장소는 blob 스토리지 등 데이터 파일 전용 시스템에 남기 때문에 DuckLake는 무한히 저장소를 확장할 수 있습니다.
마음대로 많은 컴퓨트 노드가 카탈로그 DB를 읽고 수정하면서 동시에 파일 저장소에 독립적으로 접근할 수 있습니다. 컴퓨트 측도 무한 확장 가능합니다.
마지막으로 카탈로그 DB는 오직 컴퓨트 노드들이 요청한 메타데이터 트랜잭션만 처리하면 되며, 이 트래픽은 실제 데이터 변경 건수의 몇 차례 적습니다. 그리고 DuckLake는 카탈로그 DB를 바꿀 수 있으므로(예: Postgres, SQLite 등), 수요가 늘어나면 마이그레이션도 쉽습니다. 단순 테이블과 표준 SQL만 쓰기에 걱정할 게 없습니다. 참고로 Postgres 기반 DuckLake도 테라바이트 규모, 수천 컴퓨트 노드까지 충분히 대응할 수 있습니다.
실제로 이 구조는 BigQuery와 Snowflake가 채택해서 이미 거대한 데이터를 다루고 있습니다. 필요한 경우 Spanner를 DuckLake 카탈로그 DB로 써도 무방합니다.
DuckLake 역시 DuckDB처럼 속도에 많은 신경을 씁니다. Iceberg·Delta Lake의 큰 문제 중 하나는 작은 쿼리에도 어마어마하게 많은 파일 IO가 일어난다는 것입니다. 메타데이터(카탈로그, 파일 경로 등) 추적을 위해 다수의 HTTP 요청이 이어집니다. 결과적으로 읽기/트랜잭션 처리 시간에 하한이 생기며, 트랜잭션 커밋 경로에서 많은 시간이 소요되어 충돌과 복잡한 충돌 해결이 잦아집니다. 캐시도 도움이 될 수 있지만, 추가 복잡성을 유발하고 "자주 쓰는 핫 데이터"에만 실질 효과가 있습니다.
메타데이터를 SQL DB에 몰아넣음으로써 매우 짧은 대기 시간에 쿼리 플래닝도 가능합니다. DuckLake 테이블에서 읽으려면, 카탈로그 DB에 단일 쿼리로 스키마·파티션·통계 기반 pruning을 요청해 읽어야 할 파일 리스트만 받아 곧바로 blob 스토리지에 접근합니다. 메타 정보 복원을 위해 여러 번 저장소에 요청하거나 재조립하는 일도 없습니다. S3 지연, 실패, retry, 시점 불일치 등 수많은 골칫거리가 없습니다.
DuckLake는 데이터 레이크의 가장 큰 성능 병목인 작은 변경, 다중 동시 변경 문제도 근본적으로 해결할 수 있습니다.
작은 변경시는 DuckLake가 저장소에 써야 하는 작은 파일 개수를 파격적으로 줄여 줍니다. 미미한 변경에도 새 스냅샷/매니페스트 파일을 늘려 쓰지 않고, 심지어 메타스토어에 소규모 변경 내용을 인라인 삽입 시킬 수도 있습니다! DB도 데이터를 관리할 수 있으니까요. 이로써 밀리초 단위의 빠른 쓰기, 데이터를 읽어야 하는 파일 감소 등 성능 향상을 얻습니다. 파일 수가 확 줄면, 클린업·컴팩션도 훨씬 간단해집니다.
DuckLake에서는 테이블 변경 작업이 2단계: (1) 데이터 파일 저장소 업로드, (2) 카탈로그 DB에서 단일 SQL 트랜잭션 실행. 즉, 커밋 경로의 시간이 현저히 짧아지고, SQL DB는 트랜잭션 충돌 해결도 능숙합니다. 때문에 충돌 발생 가능 시간이 짧아지고 많은 동시 커밋을 동시에 수용할 수 있게 됩니다. 카탈로그 DB가 처리할 수 있는 만큼 컨커런트 테이블 변경이 가능합니다. 심지어 Postgres만으로도 초당 수천건의 트랜잭션을 돌릴 수 있죠. 천 개의 컴퓨트 노드가 1초에 한번씩 append를 날려도 잘 돌아갑니다.
또한 DuckLake의 스냅샷은 메타스토어의 몇 개 행 추가만으로 이루어집니다. 얼마나 많은 스냅샷이 있어도 별도 pruning도 필요 없으며, 스냅샷이 Parquet 파일의 부분도 가리킬 수 있어 파일 수보다 훨씬 많은 스냅샷 관리도 가능합니다. _수백만 스냅샷_도 거뜬합니다!
DuckLake는 여러분이 기대하는 모든 레이크하우스 기능을 가지고 있습니다:
ducklake DuckDB 확장포맷 스펙만 정의하는 건 쉽지만, 실제로 동작시키는 게 어렵습니다. 그래서 오늘 DuckLake를 위한 컴퓨트 노드 구현체로 ducklake DuckDB 확장도 함께 공개합니다. 이 확장은 위에서 설명한 DuckLake 포맷을 구현하며 소개한 모든 기능을 지원합니다. MIT 라이선스 기반 오픈소스이며, 모든 지적재산권은 DuckDB Foundation 비영리단체가 보유합니다.
ducklake 확장은 개념적으로 DuckDB를 단일 노드 도구에서 벗어나 중앙 집중식 클라이언트-서버형 데이터 웨어하우스 용도로도 쓸 수 있게 대폭 격상시킵니다. 조직 내 중앙 카탈로그 DB와 파일 스토리지(AWS RDS+S3 또는 자체 구축 등)를 마련하고, 많은 참여 디바이스(PC, 모바일, 앱서버 등)에서 DuckLake 확장 포함 DuckDB를 동시에 돌릴 수 있습니다.
확장은 로컬 DuckDB 파일을 카탈로그 DB로 완전히 독립 실행도 가능하며, DuckDB가 접근 가능한 모든 외부 DB(PostgreSQL, SQLite, MySQL, MotherDuck 등)를 중앙 카탈로그로 쓸 수도 있습니다. DuckDB가 지원하는 모든 파일 시스템(로컬, S3, Azure Blob, GCS 등)도 쓸 수 있습니다.
물론 DuckLake 확장은 DuckDB의 기존 Iceberg, Delta 등 카탈로그 기능 지원을 대체하는 것이 아닌 보강입니다. DuckLake는 Iceberg/Delta의 로컬 캐시, 가속 엔진으로도 쓸 수 있습니다.
DuckLake는 DuckDB v1.3.0 (코드명 “Ossivalis”) 부터 이용할 수 있습니다.
INSTALL ducklake; 입력끝.
DuckLake는 DuckDB의 ATTACH 명령으로 초기화할 수 있습니다. 예시:
ATTACH 'ducklake:metadata.ducklake' AS my_ducklake;
이렇게 하면 my_ducklake라는 이름의 새로운 데이터베이스가 DuckDB에 붙습니다. 이 경우 메타데이터 테이블은 metadata.ducklake 파일에 저장되고, 데이터는 Parquet 파일로 현재 디렉토리의 data_files 폴더에 저장됩니다. 물론 절대 경로도 사용할 수 있습니다.
테이블을 만들고 데이터도 넣어봅시다:
CREATE TABLE my_ducklake.demo (i INTEGER);
INSERT INTO my_ducklake.demo VALUES (42), (43);
기본 DB는
USE my_ducklake로 변경할 수 있습니다.
테이블을 조회해보면:
FROM my_ducklake.demo;
┌───────┐
│ i │
│ int32 │
├───────┤
│ 42 │
│ 43 │
└───────┘
좋아요.
FROM glob('metadata.ducklake.files/*');
┌───────────────────────────────────────────────────────────────────────────────┐
│ file │
│ varchar │
├───────────────────────────────────────────────────────────────────────────────┤
│ metadata.ducklake.files/ducklake-019711dd-6f55-7f41-ab99-6ac7d9de6ef3.parquet │
└───────────────────────────────────────────────────────────────────────────────┘
하나의 Parquet 파일이 만들어진 것을 볼 수 있습니다. 이제 한 줄을 삭제해 볼까요:
DELETE FROM my_ducklake.demo WHERE i = 43;
FROM my_ducklake.demo;
┌───────┐
│ i │
│ int32 │
├───────┤
│ 42 │
└───────┘
행이 사라졌네요. 다시 폴더를 확인해보면:
FROM glob('metadata.ducklake.files/*');
┌──────────────────────────────────────────────────────────────────────────────────────┐
│ file │
│ varchar │
├──────────────────────────────────────────────────────────────────────────────────────┤
│ metadata.ducklake.files/ducklake-019711dd-6f55-7f41-ab99-6ac7d9de6ef3.parquet │
│ metadata.ducklake.files/ducklake-019711e0-16f7-7261-9d08-563a48529955-delete.parquet │
└──────────────────────────────────────────────────────────────────────────────────────┘
-delete가 붙은 Parquet 파일이 새로 생겼음을 볼 수 있습니다. 이 파일에 삭제된 행 식별자가 들어 있습니다.
물론 DuckLake는 타임 트래블 을 지원합니다. ducklake_snapshots() 함수로 사용 가능한 스냅샷을 볼 수 있습니다.
FROM ducklake_snapshots('my_ducklake');
┌─────────────┬────────────────────────────┬────────────────┬──────────────────────────────┐
│ snapshot_id │ snapshot_time │ schema_version │ changes │
│ int64 │ timestamp with time zone │ int64 │ map(varchar, varchar[]) │
├─────────────┼────────────────────────────┼────────────────┼──────────────────────────────┤
│ 0 │ 2025-05-27 15:10:04.953+02 │ 0 │ {schemas_created=[main]} │
│ 1 │ 2025-05-27 15:10:14.079+02 │ 1 │ {tables_created=[main.demo]} │
│ 2 │ 2025-05-27 15:10:14.092+02 │ 1 │ {tables_inserted_into=[1]} │
│ 3 │ 2025-05-27 15:13:08.08+02 │ 1 │ {tables_deleted_from=[1]} │
└─────────────┴────────────────────────────┴────────────────┴──────────────────────────────┘
삭제 전으로 돌아가 보겠습니다(신규 AT 문법 참고):
FROM my_ducklake.demo AT (VERSION => 2);
┌───────┐
│ i │
│ int32 │
├───────┤
│ 42 │
│ 43 │
└───────┘
버전 2에서는 두 행을 모두 볼 수 있습니다. 스냅샷 번호 대신 타임스탬프로도 가능합니다. 그냥 VERSION 대신 TIMESTAMP를 쓰면 됩니다.
버전간 어떤 변화가 있었는지 ducklake_table_changes() 함수로도 확인할 수 있습니다. 예:
FROM ducklake_table_changes('my_ducklake', 'main', 'demo', 2, 3);
┌─────────────┬───────┬─────────────┬───────┐
│ snapshot_id │ rowid │ change_type │ i │
│ int64 │ int64 │ varchar │ int32 │
├─────────────┼───────┼─────────────┼───────┤
│ 2 │ 0 │ insert │ 42 │
│ 2 │ 1 │ insert │ 43 │
│ 3 │ 1 │ delete │ 43 │
└─────────────┴───────┴─────────────┴───────┘
2번 스냅샷에서 42, 43이 들어가고, 3번에서 43이 삭제된 것을 알 수 있습니다.
DuckLake의 변경은 항상 트랜잭션 기반입니다. 위 예시들은 "autocommit" 모드(명령마다 자동 트랜잭션)였으나, BEGIN TRANSACTION, COMMIT/ROLLBACK으로 직접 트랜잭션 제어도 가능합니다.
BEGIN TRANSACTION;
DELETE FROM my_ducklake.demo;
FROM my_ducklake.demo;
┌────────┐
│ i │
│ int32 │
├────────┤
│ 0 rows │
└────────┘
ROLLBACK;
FROM my_ducklake.demo;
┌───────┐
│ i │
│ int32 │
├───────┤
│ 42 │
└───────┘
트랜잭션을 시작, 전부 삭제했다가, ROLLBACK으로 되돌리면 삭제가 안 된 걸 확인할 수 있습니다.
요약: 본 포스팅에서는 순수 SQL기반 새 레이크하우스 포맷의 설계와 배경을 설명했습니다. 간편하고, 확장가능하며 빠른 레이크하우스가 필요하다면, DuckLake를 꼭 시도해보세요! 여러분의 다양한 활용 사례가 기대됩니다.
ducklake확장은 아직 실험적입니다. 버그나 문제가 있다면ducklake확장 이슈트래커에 제보해주세요.
언론 문의는 Gabor Szarnyas에게 연락주세요.