Memray를 사용해 Django 프로젝트의 메모리 할당을 추적하고, 플레임 그래프로 병목을 찾아 개선하는 방법을 살펴봅니다.
URL: https://adamj.eu/tech/2026/01/29/django-profile-memray/
2026-01-29
파이썬 프로젝트에서 메모리 사용량을 통제하기는 어려울 수 있습니다. 이 언어는 어디에서 메모리가 할당되는지 명시적으로 드러내지 않고, 모듈 임포트는 상당한 비용이 들 수 있으며, 실수로 무한히 커지는 전역 데이터 구조를 만들어 메모리가 새게(누수되게) 하기 너무 쉽습니다. Django 프로젝트는 특히 메모리 비대화에 취약할 수 있는데, 몇 군데에서만 쓰이더라도 numpy 같은 큰 의존성을 많이 임포트할 수 있기 때문입니다.
프로그램의 메모리 사용량을 이해하는 데 도움을 주는 도구 중 하나가 Memray입니다. 블룸버그(Bloomberg) 개발자들이 만든 파이썬용 메모리 프로파일러입니다. Memray는 프로그램 실행 중 메모리가 어디에서 할당되고 해제되는지 추적합니다. 그리고 그 데이터를 여러 방식으로 보여줄 수 있는데, 특히 많은 스택 트레이스를 하나의 차트로 접어(bar 폭이 메모리 할당 크기를 의미) 보여주는 인상적인 플레임 그래프를 제공합니다.
Memray는 memray run 명령으로 어떤 파이썬 커맨드든 프로파일링할 수 있습니다. Django 프로젝트에서는 check 관리 명령부터 프로파일링해 보길 권합니다. 이 명령은 프로젝트를 로드한 다음 시스템 체크를 실행합니다. 이는 Django 앱을 시작하는 데 필요한 최소 작업량을 꽤 잘 근사하며, 서버가 로드될 때마다 및 관리 명령이 실행될 때마다 강제되는 비용이기도 합니다.
check를 프로파일링하려면 다음을 실행하세요:
$ memray run manage.py check
Writing profile results into memray-manage.py.4579.bin
System check identified no issues (0 silenced).
[memray] Successfully generated profile results.
You can now generate reports from the stored allocation records.
Some example commands to generate reports:
/.../.venv/bin/python3 -m memray flamegraph memray-manage.py.4579.bin명령은 정상적으로 완료되며 System check identified no issues (0 silenced).를 출력합니다. 그 주변으로 Memray가 프로파일링 정보(프로세스 ID가 포함된 .bin 파일에 저장됨)와, 다음 단계로 플레임 그래프를 생성하라는 제안을 출력합니다.
플레임 그래프가 정말 유용하니, 바로 만들어 봅시다:
$ memray flamegraph memray-manage.py.4579.bin
Wrote memray-flamegraph-manage.py.4579.html결과는 브라우저로 열 수 있는 .html 파일이며, 대략 다음처럼 보일 것입니다:
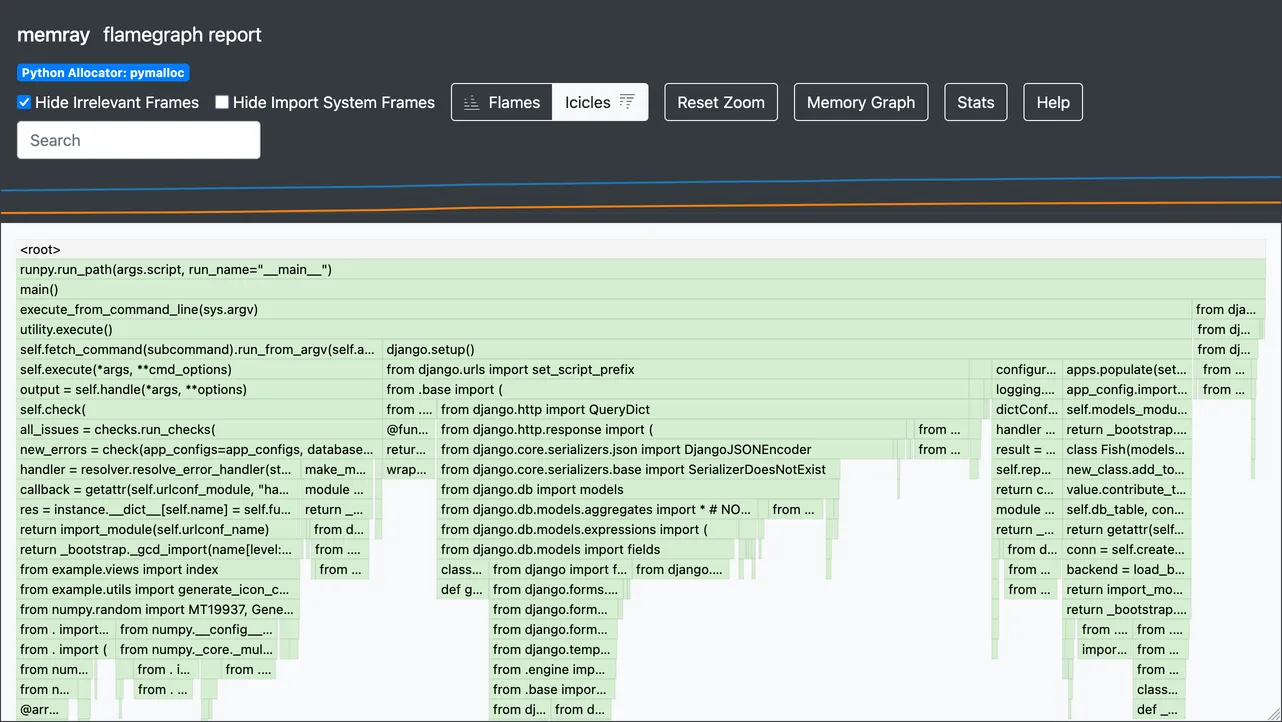
페이지 헤더에는 몇 가지 컨트롤과 함께, 시간에 따른 resident 및 heap 메모리를 추적하는 작은 그래프가 있습니다. 그 아래에는 시간에 따른 메모리 할당을 보여주는 메인 플레임 그래프가 있습니다.
기본적으로 그래프는 실제로 “icicle(고드름)” 그래프인데, 프레임이 불꽃처럼 위로 쌓이는 대신 고드름처럼 아래로 쌓입니다. 이는 파이썬의 스택 트레이스 표현(가장 최근 호출이 아래쪽)에 맞춥니다. 헤더의 버튼으로 flame(불꽃)과 icicle(고드름) 뷰를 전환할 수 있습니다.
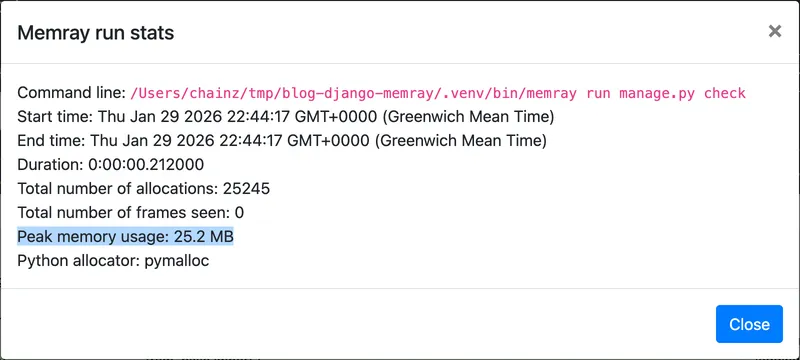
상단의 Stats 버튼을 누르면 몇 가지 상세 정보가 있는 대화상자가 열리며, 여기에는 피크 메모리 사용량도 포함됩니다:
그래프의 프레임은 해당 시점에 실행 중인 코드 라인을 보여주며, 폭은 그 지점에서 할당된 메모리 양에 비례합니다. 프레임에 마우스를 올리면 파일명, 줄 번호, 할당된 메모리, 할당 횟수 등 상세 정보가 표시됩니다:

위 예시에서 저는 이미 잠재적 문제를 좁혀 놓았습니다. from numpy.random import ... 라인이 5.7MB의 메모리를 할당하는데, 이는 피크 사용량 25.2MB의 약 23%입니다. 이 임포트는 example/utils.py 3번째 줄에서 발생합니다. 이제 그 코드를 살펴봅시다:
from colorsys import hls_to_rgb
from numpy.random import MT19937, Generator
def generate_icon_colours(number: int) -> list[str]:
"""
주어진 아이콘 개수에 대해 서로 구분되는 색상 목록을 생성합니다.
"""
colours = []
for i in range(number):
hue = i / number
lightness = 0.5
saturation = 0.7
rgb = hls_to_rgb(hue, lightness, saturation)
hex_colour = "#" + "".join(f"{int(c * 255):02x}" for c in rgb)
colours.append(hex_colour)
Generator(MT19937(42)).shuffle(colours)
return colours이 코드는 생성된 색상 리스트를 섞기 위해 numpy.random의 Generator.shuffle() 메서드를 사용합니다. numpy 임포트는 비용이 크고, 이 색상 생성은 몇몇 코드 경로에서만 사용된다고(가정해) 보면, 몇 가지 선택지가 있습니다:
코드를 삭제한다 — 함수가 사용되지 않거나, 미리 생성된 색상 목록 같은 더 단순한 것으로 대체 가능하다면 항상 가능한 선택지입니다.
필요할 때까지 임포트를 미룬다 — 임포트를 함수 내부로 옮깁니다:
def generate_icon_colours(number: int) -> list[str]:
"""
주어진 아이콘 개수에 대해 서로 구분되는 색상 목록을 생성합니다.
"""
from numpy.random import MT19937, Generator
...이렇게 하면 함수가 처음 호출될 때까지(혹은 다른 무언가가 numpy.random을 임포트할 때까지) 임포트 비용을 피할 수 있습니다.
lazy from numpy.random import MT19937, Generator
def generate_icon_colours(number: int) -> list[str]:
...이 문법은 PEP 810 구현에 따라 파이썬 3.15(2026년 10월 예상)부터 사용 가능해질 것으로 보입니다. 지정한 모듈이나 이름이 “처음 사용될 때” 실제로 임포트되도록 합니다.
출시 전까지는 wrapt.lazy_import()로 대안을 쓸 수 있습니다. 이는 사용 시점에 임포트되는 모듈 프록시를 만듭니다:
from wrapt import lazy_import
npr = lazy_import("numpy.random")
def generate_icon_colours(number: int) -> list[str]:
...
npr.Generator(npr.MT19937(42)).shuffle(colours)
...random.shuffle() 함수:import random
...
def generate_icon_colours(number: int) -> list[str]:
...
random.shuffle(colours)
...이 경우 저는 4번을 선택하겠습니다. 무거운 numpy 의존성을 아예 피할 수 있고, 결과는 거의 동등하며, 기능 변경에 대한 논의도 필요 없습니다. 다른 시작 경로에서 numpy.random을 임포트하지 않는 한, 시작 시 메모리 사용량이 개선될 것입니다.
수정 후에는 다시 프로파일링하고 변화가 있는지 확인합니다:
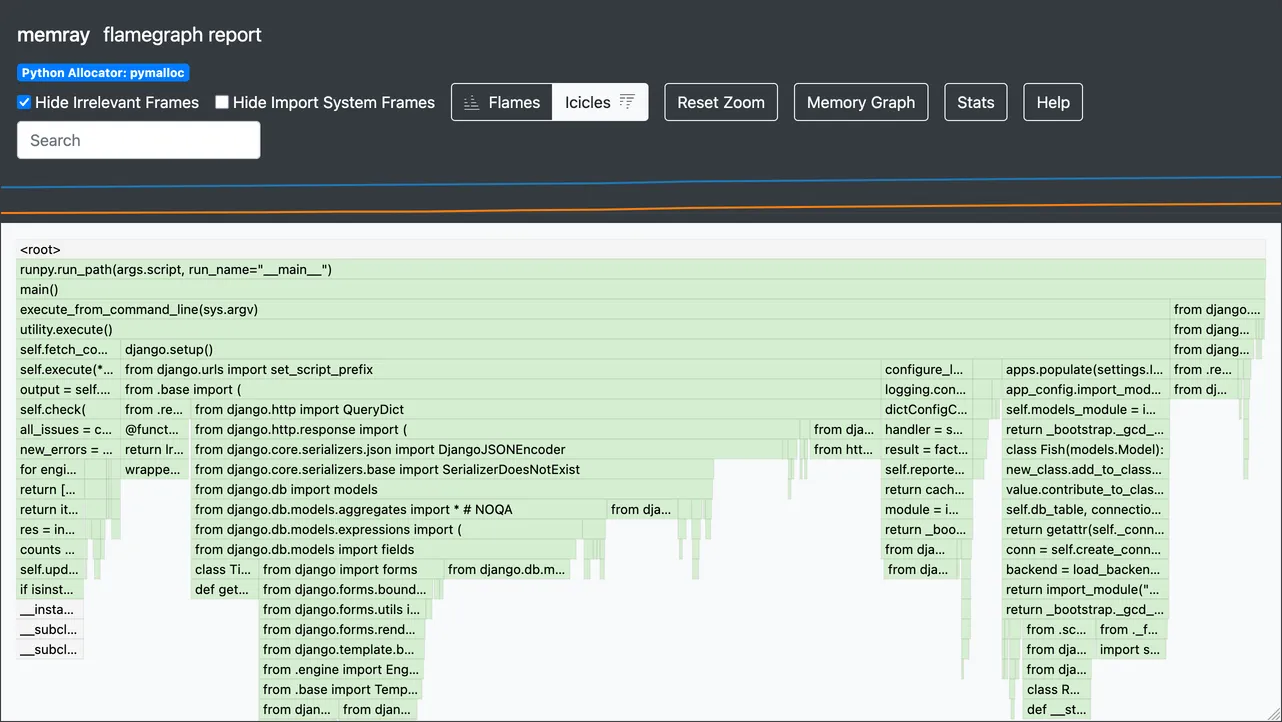
이 경우 변경이 성공해 메모리 사용량이 줄어든 것으로 보입니다. 플레임 그래프는 이전 그래프의 오른쪽 약 75%에 해당하는 모습인데, django.db.models 임포트나 configure_logging() 실행처럼 Django 시작 과정의 일반적인 부분에 대한 “icicle”이 남아 있습니다. 그리고 Stats 대화상자에는 더 낮은 피크 값이 표시됩니다.
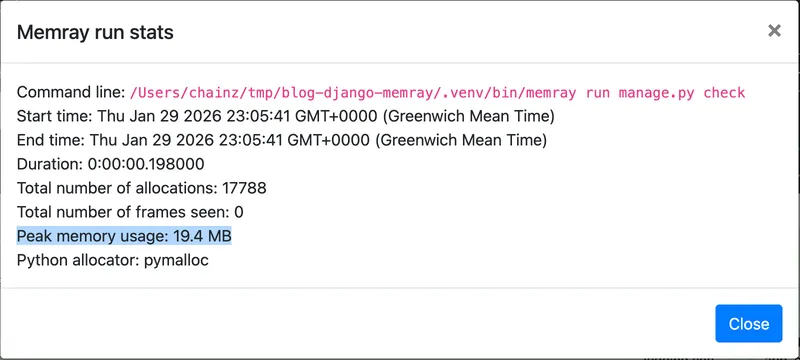
25.2MB에서 19.4MB로 감소, 전체적으로 22% 절감입니다!
(만약 변경이 효과가 없었다면, 시작 시 로드되며 numpy.random을 임포트하는 다른 모듈이 드러났을 가능성이 큽니다. 그 임포트를 제거하거나 지연시키면 절감 효과를 얻을 수 있겠죠.)
Zsh를 사용한다면, memray run, memray flamegraph, 그리고 HTML 결과 파일을 여는 작업을 다음처럼 체이닝할 수 있습니다:
$ memray run manage.py check && memray flamegraph memray-*.bin(om[1]) && open -a Firefox memray-flamegraph-*.html(om[1])이렇게 하면 잠재적인 개선안을 여러 번 반복 측정할 때 속도가 크게 향상됩니다. (om[1]) 글로빙 문법은 이전의 Zsh 전용 글에서 다뤘습니다.
Memray 길을 따라 즐거운 산책을 하시길,
—Adam
😸😸😸 GitHub를 효과적으로 사용하는 방법에 대한 제 새 책 **Boost Your GitHub DX**도 확인해 보세요! 😸😸😸
주 1회 요약 이메일, 스팸 없음. 새끼손가락 걸고 약속합니다.
관련 글:
태그: django