CQRS(명령-쿼리 책임 분리) 패턴의 개념과 동작 방식, 관련 아키텍처 패턴과의 시너지, 적용이 유리한 상황과 주의해야 할 위험 요소를 다룬다.
CQRS는 Command Query Responsibility Segregation, 즉 ‘명령-쿼리 책임 분리’를 의미한다. 이 용어는 내가 처음 Greg Young에게서 들었다. 핵심 아이디어는 정보를 갱신할 때 사용하는 모델과 정보를 읽을 때 사용하는 모델을 서로 다르게 둘 수 있다는 것이다. 어떤 상황에서는 이 분리가 유용할 수 있지만, 대부분의 시스템에서는 CQRS가 위험한 복잡성을 더할 수 있음을 경계해야 한다.
정보 시스템과 상호작용하는 주류 접근법은 이를 CRUD 데이터 저장소로 취급하는 것이다. 즉, 어떤 레코드 구조에 대한 심적 모델을 가지고, 새로운 레코드를 create(생성)하고, 레코드를 read(읽고), 기존 레코드를 update(갱신)하고, 필요 없을 때 delete(삭제)하는 것이다. 가장 단순한 경우, 우리의 상호작용은 이러한 레코드의 저장과 조회에 관한 일이다.
요구가 정교해질수록 우리는 점점 그 모델에서 멀어진다. 레코드 저장소와는 다른 방식으로 정보를 보고 싶을 수 있는데, 예컨대 여러 레코드를 하나로 합치거나, 서로 다른 곳의 정보를 결합해 가상 레코드를 만들기도 한다. 갱신 측면에서는 특정 데이터 조합만 저장을 허용하는 검증 규칙이 있거나, 제공한 데이터와는 다른 데이터를 추론해 저장하기도 한다.
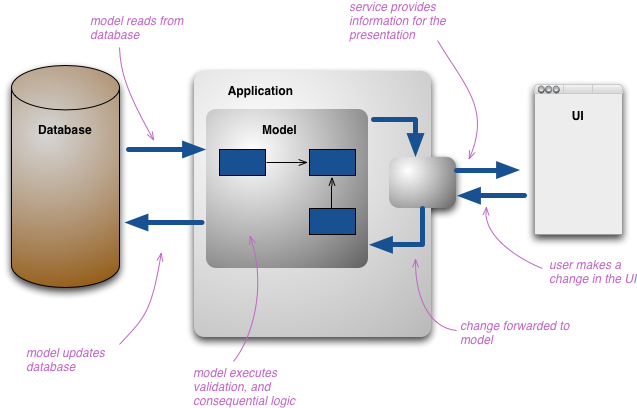
이런 일들이 일어나면서 우리는 정보의 여러 표현을 보게 된다. 사용자는 이 정보의 다양한 프레젠테이션을 통해 상호작용하는데, 각각은 서로 다른 표현이다. 개발자는 보통 모델의 핵심 요소를 조작하기 위해 자신들의 개념 모델을 만든다. 도메인 모델을 사용한다면, 이것이 보통 도메인의 개념적 표현이 된다. 또한 영속 저장소를 개념 모델과 최대한 가깝게 만드는 편이다.
이처럼 여러 표현 계층으로 이루어진 구조는 꽤 복잡해질 수 있지만, 이렇게 하더라도 사람들은 여전히 이를 하나의 개념적 표현으로 환원하여 모든 프레젠테이션 사이의 개념적 통합 지점으로 삼는다.
CQRS가 도입하는 변화는 그 개념 모델을 갱신과 표시를 위한 별도 모델로 분리하는 것이다. 이는 CommandQuerySeparation의 용어를 따라 각각 Command(명령)와 Query(조회)라고 부른다. 그 근거는, 특히 복잡한 도메인에서는 명령과 조회에 동일한 개념 모델을 사용하면 둘 중 어느 쪽에도 잘 맞지 않는, 더 복잡한 모델로 흐르기 쉽기 때문이다.
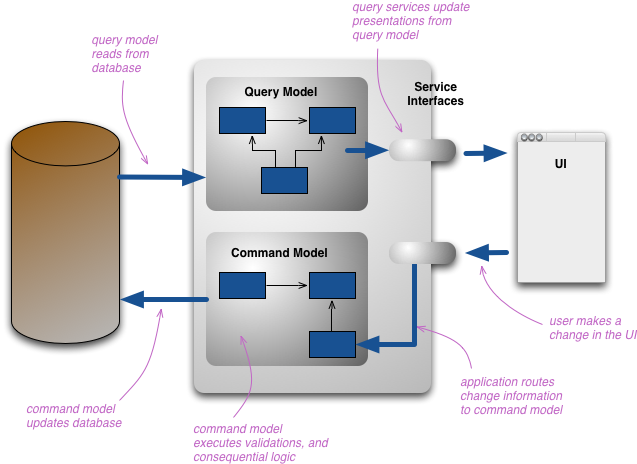
여기서 말하는 별도 모델은 가장 흔히는 서로 다른 객체 모델을 의미하며, 아마 서로 다른 논리 프로세스에서, 어쩌면 별도의 하드웨어에서 실행될 것이다. 웹 예를 들면, 사용자는 조회 모델로 렌더링된 웹 페이지를 본다. 변경을 일으키면 그 변경은 처리하기 위해 별도의 명령 모델로 라우팅되고, 그 결과 변화가 조회 모델에 전달되어 갱신된 상태를 렌더링한다.
여기에는 상당한 변주가 가능하다. 메모리 내 모델이 같은 데이터베이스를 공유할 수도 있으며, 이 경우 데이터베이스가 두 모델 사이의 통신 역할을 한다. 반대로 각기 다른 데이터베이스를 사용할 수도 있는데, 이렇게 되면 사실상 조회 측 데이터베이스를 실시간 ReportingDatabase로 만드는 셈이다. 이 경우 두 모델 또는 그들의 데이터베이스 사이에 어떤 통신 메커니즘이 필요하다.
두 모델이 반드시 별도의 객체 모델일 필요는 없다. 같은 객체가 명령 측과 조회 측에 서로 다른 인터페이스를 제공할 수도 있는데, 관계형 데이터베이스의 뷰와 비슷하다. 하지만 내가 CQRS 이야기를 들을 때는 대개 명확히 분리된 모델을 뜻한다.
CQRS는 자연스럽게 몇 가지 다른 아키텍처 패턴과 잘 맞물린다.
다른 패턴과 마찬가지로 CQRS도 어떤 곳에서는 유용하지만, 어떤 곳에서는 그렇지 않다. 많은 시스템은 CRUD 심적 모델에 잘 맞으므로 그 스타일로 구현해야 한다. CQRS는 관련된 모든 이들에게 상당한 인지적 도약을 요구하므로, 그 도약을 감수할 만한 이득이 없다면 시도하지 말아야 한다. 나는 CQRS를 성공적으로 사용한 사례도 보았지만, 지금까지 접한 사례의 대다수는 그다지 좋지 않았다. CQRS가 소프트웨어 시스템을 심각한 곤경에 빠뜨리는 중대한 요인으로 작용한 경우를 많이 보았다.
특히 CQRS는 시스템 전체가 아니라 시스템의 특정 부분(DDD 용어로 BoundedContext)에만 사용해야 한다. 이런 관점에서 각 경계 컨텍스트는 어떻게 모델링할지에 대해 자체적인 결정을 내려야 한다.
지금까지 내가 본 이점은 두 갈래다. 첫째, 소수의 복잡한 도메인은 CQRS로 접근하는 것이 더 쉬울 수 있다. 다만 CQRS에 적합한 도메인은 극히 소수라는 점을 강조하고 싶다. 보통은 명령 측과 조회 측 사이에 겹침이 충분히 커서 모델을 공유하는 편이 더 쉽다. CQRS에 맞지 않는 도메인에 CQRS를 적용하면 복잡도만 늘어나 생산성이 떨어지고 위험이 증가한다.
다른 주요 이점은 고성능 애플리케이션을 다루는 데 있다. CQRS는 읽기와 쓰기의 부하를 분리하여 각각을 독립적으로 확장할 수 있게 해준다. 애플리케이션에서 읽기와 쓰기 사이에 큰 불균형이 있다면 매우 유용하다. 설사 그렇지 않더라도 두 측면에 서로 다른 최적화 전략을 적용할 수 있다. 예를 들어 조회와 갱신에 서로 다른 데이터베이스 접근 기법을 사용할 수 있다.
도메인이 CQRS에 맞지 않지만, 복잡하거나 성능 문제를 유발하는 조회가 있다면 ReportingDatabase를 여전히 사용할 수 있음을 기억하라. CQRS는 모든 조회에 별도 모델을 사용한다. 리포팅 데이터베이스를 사용하면 대부분의 조회는 여전히 메인 시스템이 처리하되, 더 부담이 큰 조회만 리포팅 데이터베이스로 오프로드할 수 있다.
이러한 이점에도 불구하고, CQRS 사용에는 매우 신중해야 한다. 많은 정보 시스템은 읽는 방식과 같은 방식으로 갱신되는 정보 기반이라는 개념에 잘 들어맞으며, 이런 시스템에 CQRS를 추가하면 상당한 복잡도를 더할 수 있다. 유능한 팀의 손에 있더라도 생산성을 크게 떨어뜨리고 프로젝트에 불필요한 위험을 더한 사례를 분명히 보았다. 그러므로 CQRS는 도구 상자에 넣어 둘 만한 패턴이긴 하지만, 잘 쓰기 어렵고 잘못 다루면 중요한 부분을 쉽게 망쳐버릴 수 있음을 명심하라.