ZeroMQ의 필요성, 기본 패턴(요청-응답, 발행-구독, 파이프라인), 예제 코드와 함께 안정적으로 확장 가능한 메시징 애플리케이션을 설계·구현하는 방법을 소개한다.
ZeroMQ를 어떻게 설명할까? 우리 중 일부는 ZeroMQ가 해주는 멋진 일들을 나열하는 것부터 시작한다. 소켓에 스테로이드를 단 것 같아요. 라우팅이 되는 우편함 같아요. 엄청 빠르죠! 또 어떤 이들은 자신의 깨달음의 순간, 모든 것이 명확해지던 그 짜릿한 사토리, 패러다임 전환의 순간을 공유하려 한다. 그냥 모든 게 단순해져요. 복잡함이 사라져요. 머리가 트여요. 또 어떤 이들은 비교를 통해 설명한다. 더 작고 단순하지만, 그래도 익숙하게 보이죠. 개인적으로 나는 왜 ZeroMQ를 만들었는지를 떠올리는 걸 좋아한다. 그게 아마 지금 이 글을 읽고 있는 당신이 서 있는 자리와 가장 가까울 것이다.
프로그래밍은 과학에 예술을 덧입힌 것이다. 우리 대부분은 소프트웨어의 물리학을 이해하지 못하고, 또 그게 제대로 가르쳐지는 경우도 거의 없기 때문이다. 소프트웨어의 물리학은 알고리즘, 자료구조, 언어, 추상화 같은 것이 아니다. 이런 것들은 우리가 만들고, 쓰고, 버리는 도구에 지나지 않는다. 소프트웨어의 진짜 물리학은 사람의 물리학, 특히 복잡함 앞에서의 우리의 한계와, 큰 문제를 나누어 함께 풀고자 하는 우리의 욕망이다. 이것이 프로그래밍이라는 과학이다. 사람들이 쉽게 이해하고 사용할 수 있는 빌딩 블록을 만들면, 사람들은 함께 일하며 가장 거대한 문제들까지도 해결하기 시작한다.
우리는 연결된 세상에 살고 있고, 현대 소프트웨어는 이 세상을 헤쳐 나가야 한다. 그러니 내일의 거대한 해결책을 위한 빌딩 블록들은 연결되어 있고, 엄청난 병렬성을 가져야 한다. 더 이상 코드는 "강하고 묵묵한" 존재로는 충분치 않다. 코드는 코드와 대화해야 한다. 코드는 수다스럽고, 사교적이며, 잘 연결되어 있어야 한다. 코드는 인간의 뇌처럼 동작해야 한다. 수조 개의 개별 뉴런이 서로에게 메시지를 쏘아 보내는, 중앙 통제도 단일 장애점도 없는, 그럼에도 엄청나게 어려운 문제를 풀어내는 거대한 병렬 네트워크. 그리고 코드의 미래가 인간의 뇌를 닮은 것이 우연이 아니다. 결국 모든 네트워크의 끝단에는 어떤 수준에서든 인간의 뇌가 있기 때문이다.
스레드, 프로토콜, 네트워크 같은 걸 조금이라도 다뤄봤다면, 이게 사실상 불가능하다는 걸 안다. 이건 꿈에 가깝다. 실제 상황을 처리하기 시작하면 소켓 몇 개로 프로그램 몇 개를 연결하는 것만으로도 곧장 끔찍해진다. 수조 개라고? 상상도 못 할 비용이 든다. 컴퓨터를 연결하는 일은 너무 어렵기 때문에, 이 일을 대신해 주는 소프트웨어와 서비스는 수십억 달러 규모의 비즈니스가 되었다.
그래서 우리는 배선(네트워크 인프라)은 이미 우리가 쓸 수 있는 능력보다 수년은 앞서 있는데, 정작 소프트웨어는 그걸 못 따라가는 세상에 살고 있다. 1980년대에는 소프트웨어 위기가 있었고, 당시 선도적인 소프트웨어 엔지니어였던 Fred Brooks는 생산성, 신뢰성, 단순성을 한 자릿수 이상 끌어올릴 "은탄환"은 없다고 믿었다.
Brooks는 이 위기를 해결한 자유·오픈소스 소프트웨어를 보지 못했다. FOSS는 우리가 지식을 효율적으로 공유할 수 있게 했다. 오늘 우리는 또 다른 소프트웨어 위기에 직면해 있다. 다만 이건 별로 이야기되지 않는다. 오직 가장 크고 부유한 회사들만이 연결된 애플리케이션을 만들 여력이 있다. 클라우드는 있지만, 그것은 폐쇄적이다. 우리의 데이터와 지식은 우리의 개인용 컴퓨터에서, 우리가 접근할 수도 경쟁할 수도 없는 클라우드 속으로 사라지고 있다. 우리의 소셜 네트워크는 누가 소유하고 있을까? 마치 메인프레임-PC 혁명이 거꾸로 흘러가는 것과 같다.
정치철학 이야기는 다른 책으로 남겨두자. 중요한 점은 이렇다. 인터넷은 엄청나게 잘 연결된 코드를 가능하게 하지만, 실제로는 그게 우리 대부분에게는 손이 닿지 않는다는 것이다. 그래서 보건, 교육, 경제, 교통 등에서의 큰 흥미로운 문제들이 여전히 풀리지 못하고 있다. 코드를 연결할 방법이 없고, 그러니 이 문제들을 함께 풀 수 있는 뇌들도 연결할 방법이 없기 때문이다.
연결된 코드를 위한 도전 과제를 풀려는 시도는 수없이 많았다. 퍼즐의 일부씩을 푸는 IETF 명세만 해도 수천 개다. 애플리케이션 개발자의 관점에서, HTTP는 아마도 그나마 단순해서 잘 작동한 유일한 해법일 것이다. 하지만 HTTP는 어쩌면, 개발자와 아키텍트들에게 큰 서버와 얇고 멍청한 클라이언트라는 사고방식을 심어 줌으로써 문제를 더 악화시켰을지도 모른다.
그래서 지금도 사람들은 생(raw) UDP와 TCP, 사설 프로토콜, HTTP, 웹소켓을 써서 애플리케이션을 연결하고 있다. 여전히 고통스럽고, 느리며, 확장하기 어렵고, 본질적으로 중앙집중적이다. 분산 P2P 아키텍처는 대부분 장난감일 뿐, 실제 일에 쓰이지 않는다. 데이터를 교환하기 위해 Skype나 Bittorrent를 쓰는 애플리케이션이 얼마나 되는가?
다시 프로그래밍의 과학 이야기로 돌아가 보자. 세상을 고치려면 두 가지를 해야 했다. 첫째, "어떤 코드든 어디서든 다른 코드와 연결하는" 일반적인 문제를 풀어야 했다. 둘째, 사람들이 쉽게 이해하고 사용할 수 있는, 가능한 한 단순한 빌딩 블록으로 그것을 감싸야 했다.
말도 안 되게 단순해 보인다. 어쩌면 정말 단순할지도 모른다. 그게 바로 요지다.
다음과 같이 가정하자.
예제들은 공개 GitHub 저장소에 있다. 모든 예제를 가장 간단히 가져오는 방법은 이 저장소를 clone 하는 것이다:
git clone --depth=1 https://github.com/imatix/zguide.git그 다음, examples 서브디렉터리를 살펴보자. 언어별 예제가 있다. 사용하는 언어의 예제가 없다면, 번역을 제출하길 권한다. 이 글이 지금처럼 유용해진 것도 많은 사람들의 번역 덕분이다. 모든 예제는 MIT/X11 라이선스로 제공된다.
이제 코드로 시작해 보자. 당연히 Hello World 예제부터 시작한다. 클라이언트와 서버를 만든다. 클라이언트는 서버에게 "Hello"를 보내고, 서버는 "World"로 응답한다. 다음은 C로 작성한 서버 코드다. ZeroMQ 소켓을 포트 5555에 열고, 요청을 읽어 들인 다음, 각 요청에 "World"로 응답한다:
// Hello World server
#include <zmq.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <assert.h>
int main (void)
{
// 클라이언트와 대화할 소켓
void *context = zmq_ctx_new ();
void *responder = zmq_socket (context, ZMQ_REP);
int response = zmq_bind (responder, "tcp://*:5555");
assert (response == 0); // 응답 코드가 성공을 의미하는지 확인
while (1) {
static const size_t kReadBufferLength = 10;
char buffer [kReadBufferLength];
zmq_recv (responder, buffer, kReadBufferLength, 0);
printf ("Received Hello\n");
sleep (1); // '작업'을 하는 척
static const char kReplyString[] = "World";
zmq_send(responder, kReplyString, sizeof(kReplyString) - 1, 0);
}
return 0;
}...(중략: 모든 언어별 코드 블록은 원문과 동일하며, 주석만 한국어로 자연스럽게 번역되어 있다. 아래에서도 마찬가지로 코드 자체는 그대로 두고, 설명과 주석·문장만 번역한다.)
그림 2 - 요청-응답
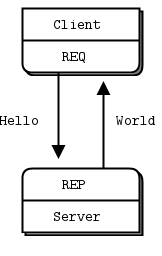
REQ-REP 소켓 쌍은 일종의 락스텝(lockstep)으로 동작한다. 클라이언트는 루프 안에서 (또는 필요하다면 한 번만) zmq_send()를 호출한 다음 zmq_recv()를 호출한다. 이 순서를 어기고(예: 연속해서 두 번 send) 다른 순서로 호출하면, send나 recv 호출에서 -1이 반환된다. 마찬가지로 서비스(서버)는 필요한 만큼 zmq_recv()를 먼저, 그 다음 zmq_send()를 호출해야 한다.
ZeroMQ는 C를 기준(reference) 언어로 사용하며, 예제 역시 주로 C를 쓴다. 온라인에서 이 글을 읽고 있다면, 예제 아래의 링크가 다른 언어로 번역된 코드로 연결된다. C++ 버전 서버를 비교해 보자:
// ... (코드 동일, 주석은 한국어로 번역)ZeroMQ API는 C와 C++에서 비슷하다는 것을 볼 수 있다. PHP나 Java 같은 언어에서는 더 많은 것을 감쌀 수 있어서, 코드가 더 읽기 쉬워진다:
// ... (코드 동일, 주석 번역)// ... (코드 동일, 주석 번역)다른 언어들에서도 서버는 같은 구조를 가진다.
이제 클라이언트 코드를 보자.
// Hello World client
#include <zmq.h>
#include <string.h>
#include <stdio.h>
#include <unistd.h>
int main (void)
{
printf ("Connecting to hello world server...\n");
void *context = zmq_ctx_new ();
void *requester = zmq_socket (context, ZMQ_REQ);
zmq_connect (requester, "tcp://localhost:5555");
int request_nbr;
for (request_nbr = 0; request_nbr != 10; request_nbr++) {
char buffer [10];
printf ("Sending Hello %d...\n", request_nbr);
zmq_send (requester, "Hello", 5, 0);
zmq_recv (requester, buffer, 10, 0);
printf ("Received World %d\n", request_nbr);
}
zmq_close (requester);
zmq_ctx_destroy (context);
return 0;
}...(이하 모든 언어별 hwclient 코드 블록 포함)
이제 이 코드가 너무 단순해서 비현실적으로 보일 수도 있다. 하지만 앞에서 본 것처럼 ZeroMQ 소켓에는 슈퍼파워가 있다. 이 서버에 수천 개의 클라이언트를 한꺼번에 던져도, 서버는 여전히 잘, 그리고 빠르게 동작할 것이다. 재미삼아, 클라이언트를 먼저 실행한 다음 나중에 서버를 실행해 보라. 그래도 모든 것이 잘 동작한다. 그리고 이것이 의미하는 바를 잠시 생각해 보라.
두 프로그램이 실제로 하는 일을 간단히 설명해 보자. 이들은 ZeroMQ 컨텍스트(context)를 만들고, 소켓을 하나 만든다. 용어가 낯설더라도 지금은 신경 쓰지 말자. 곧 익숙해질 것이다. 서버는 REP(응답) 소켓을 포트 5555에 바인딩한다. 서버는 루프를 돌며 요청을 기다리고, 각 요청마다 응답을 보낸다. 클라이언트는 요청을 보내고, 서버로부터 응답을 읽는다.
서버를 Ctrl-C로 죽였다가 다시 시작하면, 클라이언트는 제대로 복구되지 않을 것이다. 크래시한 프로세스로부터 복구하는 일은 그리 간단하지 않다. 믿을 수 있는 요청-응답 플로를 만드는 일은 꽤 복잡해서, 4장 - 신뢰할 수 있는 요청-응답 패턴을 다룰 때까지 미룰 것이다.
겉으로 보기에는 단순하지만, 내부에서는 많은 일이 벌어지고 있다. 하지만 프로그래머 입장에서 중요한 것은 코드가 얼마나 짧고 간결한지, 그리고 무거운 부하에서도 얼마나 잘 죽지 않는지다. 이것이 요청-응답 패턴이며, 아마 ZeroMQ를 사용하는 가장 단순한 방법일 것이다. 이는 RPC와 고전적인 클라이언트/서버 모델에 대응된다.
ZeroMQ는 보내는 데이터의 바이트 수 말고는 아무것도 알지 못한다. 즉, 애플리케이션이 데이터를 다시 읽을 수 있도록, 안전하게 포맷하는 책임은 전적으로 여러분에게 있다. 객체나 복잡한 데이터 타입에 대해서는 Protocol Buffers 같은 특화 라이브러리의 역할이다. 하지만 단순한 문자열이라도 신경을 써야 한다.
C와 몇몇 다른 언어에서 문자열은 널 바이트(null byte)로 끝난다. 우리는 "HELLO" 문자열을 이 널 바이트까지 포함해 다음과 같이 보낼 수 있다:
zmq_send (requester, "Hello", 6, 0);하지만 다른 언어에서 문자열을 보낼 때는, 보통 이 널 바이트를 포함하지 않는다. 예를 들어, 파이썬에서 같은 문자열을 보낼 때는 이렇게 한다:
socket.send ("Hello")이 경우, 와이어(네트워크 상)에는 길이(짧은 문자열의 경우 1바이트)와 문자열 내용(각 문자를 표현하는 바이트들)만 실린다.
그림 3 - ZeroMQ 문자열

이를 C 프로그램에서 읽으면, 얼핏 문자열처럼 보이고, 운 좋게 뒤에 우연히 널 바이트가 따라오면 운 좋게 문자열처럼 동작할 수도 있다. 하지만 엄밀히 말해 올바른 C 스타일 문자열이 아니다. 클라이언트와 서버가 문자열 포맷에 합의하지 않으면, 이상한 결과를 얻게 된다.
C에서 ZeroMQ로부터 문자열 데이터를 받을 때는, 그 문자열이 안전하게 종료되었다고 믿어서는 안 된다. 문자열을 읽을 때마다 항상 한 바이트를 더 담을 수 있는 새 버퍼를 할당하고, 그 안에 데이터를 복사한 다음 끝에 널 바이트를 붙여야 한다.
따라서 다음과 같은 규칙을 세우자. ZeroMQ 문자열은 길이가 명시되고, 와이어 상에는 널 바이트 없이 전송된다. 가장 단순한 경우(그리고 예제에서 그렇게 할 것이다), ZeroMQ 문자열은 ZeroMQ 메시지 프레임 하나에 깔끔하게 대응된다. 이는 위 그림처럼, 길이와 바이트들로 구성된다.
C에서 ZeroMQ 문자열을 받아 C 문자열로 만들어 애플리케이션에 전달하려면, 다음과 같이 해야 한다:
// 소켓에서 ZeroMQ 문자열을 받아 C 문자열로 변환한다
// 길이가 255자를 넘으면 잘라낸다
static char *
s_recv (void *socket) {
char buffer [256];
int size = zmq_recv (socket, buffer, 255, 0);
if (size == -1)
return NULL;
if (size > 255)
size = 255;
buffer [size] = '\0';
/* *nix에서는 strndup(buffer, sizeof(buffer)-1)를 사용 */
return strdup (buffer);
}이 함수는 유용한 헬퍼 함수다. 재사용할 수 있는 것들을 만드는 정신에 따라, 올바른 ZeroMQ 포맷으로 문자열을 보내는 s_send 함수도 작성하고, 이를 재사용할 수 있는 헤더 파일에 모아 두자.
그 결과물이 zhelpers.h인데, 이를 사용하면 더 깔끔하고 짧은 C용 ZeroMQ 애플리케이션을 작성할 수 있다. 소스는 꽤 길고, C 개발자들에게만 흥미로울 것이므로, 시간 날 때 읽어 보라.
zhelpers.h와 이 가이드의 뒤에 나오는 예제들에서 쓰이는 s_ 접두사는 "static 함수나 변수"라는 의미의 표식이다.
ZeroMQ는 여러 버전이 있고, 문제가 생기면 종종 나중 버전에서 이미 고쳐진 이슈일 때가 있다. 따라서 지금 링크된 ZeroMQ의 정확한 버전이 무엇인지 아는 것은 꽤 유용한 트릭이다.
다음은 그 일을 하는 아주 간단한 프로그램이다.
// Report 0MQ version
#include <zmq.h>
int main (void)
{
int major, minor, patch;
zmq_version (&major, &minor, &patch);
printf ("Current 0MQ version is %d.%d.%d\n", major, minor, patch);
return 0;
}...(이하 C++, C#, CL, Delphi, Erlang, Elixir, F#, Felix, Go, Haskell, Java, Julia, Lua, Node.js, Objective-C, Perl, PHP, Python, Q에 대한 version 예제 코드 포함)
두 번째 고전적인 패턴은 일방향 데이터 배포(one-way data distribution)다. 서버가 여러 클라이언트에게 업데이트를 푸시한다. 여기서는 우편번호(Zip code), 온도, 상대습도로 구성된 날씨 업데이트를 푸시하는 예제를 보자. 실제 기상 관측소처럼, 우리는 무작위 값을 생성할 것이다.
다음은 서버 코드다. 이 애플리케이션에는 포트 5556을 사용하자.
// Weather update server
// Binds PUB socket to tcp://*:5556
// Publishes random weather updates
#include "zhelpers.h"
int main (void)
{
// 컨텍스트와 publisher 준비
void *context = zmq_ctx_new ();
void *publisher = zmq_socket (context, ZMQ_PUB);
int rc = zmq_bind (publisher, "tcp://*:5556");
assert (rc == 0);
// 난수 생성기 초기화
srandom ((unsigned) time (NULL));
while (1) {
// 상사를 속일 만한 값들을 만든다
int zipcode, temperature, relhumidity;
zipcode = randof (100000);
temperature = randof (215) - 80;
relhumidity = randof (50) + 10;
// 모든 subscriber에게 메시지 전송
char update [20];
sprintf (update, "%05d %d %d", zipcode, temperature, relhumidity);
s_send (publisher, update);
}
zmq_close (publisher);
zmq_ctx_destroy (context);
return 0;
}...(이하 C++, C#, Common Lisp, Delphi, Erlang, Elixir, F#, Felix, Go, Haskell, Haxe, Java, Julia, Lua, Node.js, Objective-C, Perl, PHP, Python 등의 언어로 작성된 wuserver 예제가 이어진다.)
이 업데이트 스트림에는 시작도 끝도 없다. 끊임없이 이어지는 방송과 같다.
다음은 클라이언트 애플리케이션이다. 이 앱은 업데이트 스트림을 들으면서 주어진 우편번호와 관련된 것만 골라 잡는다. 기본값은 뉴욕시(10001)다. 모험을 시작하기에 딱 좋은 도시니까.
// Weather update client
// Connects SUB socket to tcp://localhost:5556
// Collects weather updates and finds avg temp in zipcode
#include "zhelpers.h"
int main (int argc, char *argv [])
{
// 서버와 대화할 소켓
printf ("Collecting updates from weather server...\n");
void *context = zmq_ctx_new ();
void *subscriber = zmq_socket (context, ZMQ_SUB);
int rc = zmq_connect (subscriber, "tcp://localhost:5556");
assert (rc == 0);
// 구독할 우편번호, 기본값은 NYC, 10001
const char *filter = (argc > 1)? argv [1]: "10001 ";
rc = zmq_setsockopt (subscriber, ZMQ_SUBSCRIBE,
filter, strlen (filter));
assert (rc == 0);
// 100개의 업데이트 처리
int update_nbr;
long total_temp = 0;
for (update_nbr = 0; update_nbr < 100; update_nbr++) {
char *string = s_recv (subscriber);
int zipcode, temperature, relhumidity;
sscanf (string, "%d %d %d",
&zipcode, &temperature, &relhumidity);
total_temp += temperature;
free (string);
}
printf ("Average temperature for zipcode '%s' was %dF\n",
filter, (int) (total_temp / update_nbr));
zmq_close (subscriber);
zmq_ctx_destroy (context);
return 0;
}...(이하 C++, C#, Common Lisp, Delphi, Erlang, Elixir, F#, Felix, Go, Haskell, Haxe, Java, Julia, Lua, Node.js, Objective-C, Perl, PHP, Python 등 언어별 wuclient 예제 포함)
그림 4 - 발행-구독(Publish-Subscribe)
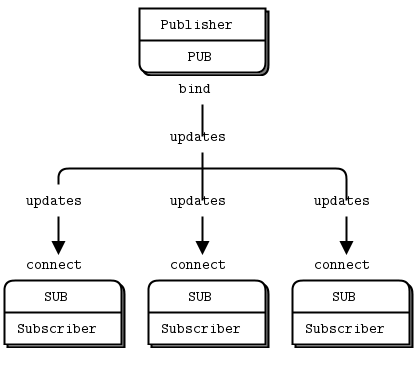
SUB 소켓을 사용할 때는 zmq_setsockopt()와 ZMQ_SUBSCRIBE를 사용해 구독을 반드시 설정해야 한다는 점에 주의하자. 구독을 하나도 설정하지 않으면, 메시지를 전혀 받지 못한다. 초보자들이 자주 하는 실수다. Subscriber는 여러 개의 구독을 설정할 수 있고, 이들은 합집합처럼 동작한다. 즉, 어떤 업데이트가 설정된 구독 중 하나라도 매치되면, subscriber는 그 메시지를 받는다. Subscriber는 특정 구독을 취소할 수도 있다. 구독은 종종(하지만 항상은 아닌) 출력 가능한 문자열이다. 동작 방식은 zmq_setsockopt() 문서를 참고하라.
PUB-SUB 소켓 쌍은 비동기적이다. 클라이언트는 루프 안에서(또는 필요하다면 한 번만) zmq_recv()를 호출한다. SUB 소켓에 메시지를 보내려고 하면 에러가 발생한다. 마찬가지로 서비스(PUB 측)는 필요한 만큼 zmq_send()를 호출하지만, PUB 소켓에서는 zmq_recv()를 호출해서는 안 된다.
이론적으로는 ZeroMQ 소켓에서 어느 쪽이 connect를 하고 어느 쪽이 bind를 하는지는 상관 없다. 하지만 실제로는 나중에 설명하겠지만 문서화되지 않은 차이가 있다. 지금은 네트워크 설계상 정말 불가능한 경우가 아니라면, PUB 쪽을 bind하고 SUB 쪽을 connect 하는 것이 좋다.
PUB-SUB 소켓에 대해 꼭 알아야 할 중요한 점이 하나 더 있다. subscriber가 정확히 언제부터 메시지를 받기 시작하는지는 알 수 없다는 것이다. subscriber를 시작하고, 잠시 기다렸다가 publisher를 시작했다 해도, subscriber는 publisher가 보내는 최초의 몇 개 메시지를 항상 놓친다. subscriber가 publisher에 연결되는 동안(이 역시 아주 짧지만 0이 아닌 시간이 걸린다), publisher는 이미 메시지를 보내고 있을 수 있기 때문이다.
이 "느린 합류자(slow joiner)" 증상은 많은 사람들에게 자주 들이받히는 문제라, 여기서 자세히 설명하겠다. ZeroMQ는 비동기 I/O, 즉 백그라운드에서 I/O를 처리한다는 점을 기억하자. 다음과 같이 두 노드가 순서대로 동작한다고 하자.
이 경우, subscriber는 대개 아무것도 받지 못한다. 여러분은 눈을 깜박이며 구독 필터를 제대로 설정했는지 확인해 볼 것이고, 다시 시도해도 subscriber는 여전히 아무것도 받지 못할 것이다.
TCP 연결을 맺는 일에는 왕복(handshake)이 필요한데, 네트워크와 피어 사이의 홉 수에 따라 수 밀리초가 걸린다. 그 시간 동안 ZeroMQ는 많은 메시지를 보낼 수 있다. 예를 들어, 연결을 맺는데 5ms가 걸리고, 같은 링크가 초당 100만 메시지를 처리할 수 있다고 하자. subscriber가 publisher에 connect하고 있는 5ms 동안, publisher는 1ms 만에 1,000개의 메시지를 다 보내 버릴 수 있다.
2장 - 소켓과 패턴에서, publisher와 subscribers를 동기화하여 subscriber들이 실제로 연결되어 준비될 때까지는 데이터를 발행하지 않도록 하는 법을 설명할 것이다. publisher를 지연시키는 가장 단순하고 멍청한 방법은 sleep을 쓰는 것이다. 하지만 실제 애플리케이션에서 이렇게 해서는 안 된다. 매우 취약하고, 우아하지 않으며, 느리기 때문이다. sleep은 단지 어떤 일이 벌어지는지 스스로 확인하기 위한 용도로만 쓰고, 그 다음에는 2장 - 소켓과 패턴을 참고해 제대로 된 방법을 익히자.
동기화의 대안은, 발행되는 데이터 스트림이 무한하며 시작과 끝이 없다고 그냥 가정하는 것이다. 또한 subscriber는 자신이 시작되기 전에 무슨 일이 있었는지는 신경 쓰지 않는다고 가정한다. 우리가 날씨 클라이언트 예제를 만든 방식이 바로 이렇다.
클라이언트는 자신이 선택한 우편번호를 구독하고, 그 우편번호에 대한 업데이트를 100개 모은다. 우편번호가 무작위로 분포되어 있다면, 서버가 보내는 업데이트는 약 천만 개 정도가 될 것이다. 클라이언트를 먼저 시작한 다음 서버를 시작해도, 클라이언트는 계속 잘 동작한다. 서버를 멈췄다가 다시 시작해도, 클라이언트는 계속 잘 동작한다. 클라이언트가 100개의 업데이트를 모으면, 평균을 계산하고 출력한 뒤 종료한다.
발행-구독(pub-sub) 패턴에 관해 몇 가지 포인트를 정리하자.
하나의 subscriber는 여러 publisher에 connect할 수 있다(각각 한 번의 connect 호출). 그러면 데이터가 인터리브(interleaved)되어 도착하는데, 이는 어떤 publisher도 다른 publisher를 압도하지 못하도록 "공정 큐잉(fair-queuing)"된다.
publisher에 연결된 subscriber가 하나도 없다면, publisher는 그저 모든 메시지를 버린다.
TCP를 사용하고 있고 subscriber가 느리다면, 메시지는 publisher 측에 큐잉된다. 나중에 설명할 "high-water mark" 설정으로 publisher를 보호할 수 있다.
ZeroMQ 3.x부터, 연결형 프로토콜(TCP tcp://, IPC ipc://)을 사용할 때의 필터링은 publisher 쪽에서 수행된다. epgm:// 프로토콜을 사용할 때에는 subscriber 쪽에서 필터링이 수행된다. ZeroMQ 2.x에서는 모든 필터링이 subscriber 쪽에서 수행되었다.
내 노트북(2011년형 Intel i5, 평범한 사양)에서, 1천만 개의 메시지를 수신/필터링하는 데 걸리는 시간은 대략 이 정도다:
$ time wuclient
Collecting updates from weather server...
Average temperature for zipcode '10001 ' was 28F
real 0m4.470s
user 0m0.000s
sys 0m0.008s그림 5 - 병렬 파이프라인
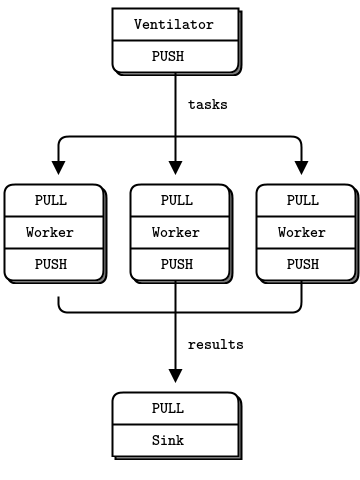
마지막 예제로(아마도 당신은 이미 맛있는 코드에 지쳐서, 비교 추상 규범에 관한 언어학적 논의로 돌아가고 싶을지도 모르겠다), 작은 슈퍼컴퓨팅을 해 보자. 그 다음에 커피를 마시면 된다. 우리의 슈퍼컴퓨팅 애플리케이션은 꽤 전형적인 병렬 처리 모델이다. 구성 요소는 다음과 같다.
실제 환경에서는 worker들이 아주 빠른 박스들에서, 아마도 GPU(그래픽 처리 장치)를 사용해 무거운 계산을 수행할 것이다. 다음은 ventilator다. 100개의 작업을 생성하는데, 각 작업은 worker에게 몇 밀리초 동안 잠자라고 알려 주는 메시지다.
// Task ventilator
// Binds PUSH socket to tcp://localhost:5557
// Sends batch of tasks to workers via that socket
#include "zhelpers.h"
int main (void)
{
void *context = zmq_ctx_new ();
// 메시지를 보낼 소켓
void *sender = zmq_socket (context, ZMQ_PUSH);
zmq_bind (sender, "tcp://*:5557");
// 작업 시작 신호를 보낼 소켓
void *sink = zmq_socket (context, ZMQ_PUSH);
zmq_connect (sink, "tcp://localhost:5558");
printf ("Press Enter when the workers are ready: ");
getchar ();
printf ("Sending tasks to workers...\n");
// 첫 번째 메시지는 "0"으로, 배치 시작을 알린다
s_send (sink, "0");
// 난수 생성기 초기화
srandom ((unsigned) time (NULL));
// 작업 100개 전송
int task_nbr;
int total_msec = 0; // 예상 총 비용(ms)
for (task_nbr = 0; task_nbr < 100; task_nbr++) {
int workload;
// 1~100ms 사이의 무작위 작업량
workload = randof (100) + 1;
total_msec += workload;
char string [10];
sprintf (string, "%d", workload);
s_send (sender, string);
}
printf ("Total expected cost: %d msec\n", total_msec);
zmq_close (sink);
zmq_close (sender);
zmq_ctx_destroy (context);
return 0;
}...(이하 C++, C#, CL, Delphi, Erlang, Elixir, F#, Felix, Go, Haskell, Haxe, Java, Julia, Lua, Node.js, Objective-C, Perl, PHP, Python 등의 taskvent 예제 포함)
다음은 worker 애플리케이션이다. 메시지를 하나 받아서 해당 시간만큼 잠자고, 작업 완료를 알리는 신호를 보낸다.
// Task worker
// Connects PULL socket to tcp://localhost:5557
// Collects workloads from ventilator via that socket
// Connects PUSH socket to tcp://localhost:5558
// Sends results to sink via that socket
#include "zhelpers.h"
int main (void)
{
// 메시지를 받을 소켓
void *context = zmq_ctx_new ();
void *receiver = zmq_socket (context, ZMQ_PULL);
zmq_connect (receiver, "tcp://localhost:5557");
// 메시지를 보낼 소켓
void *sender = zmq_socket (context, ZMQ_PUSH);
zmq_connect (sender, "tcp://localhost:5558");
// 영원히 작업 처리
while (1) {
char *string = s_recv (receiver);
printf ("%s.", string); // 진행 상황 표시
fflush (stdout);
s_sleep (atoi (string)); // 작업 수행
free (string);
s_send (sender, ""); // sink로 결과 전송
}
zmq_close (receiver);
zmq_close (sender);
zmq_ctx_destroy (context);
return 0;
}...(이하 각 언어별 taskwork 예제 포함)
다음은 sink 애플리케이션이다. 100개의 작업 완료 신호를 모으고, 전체 처리에 걸린 시간을 계산해, worker들이 실제로(여러 개일 경우) 병렬로 동작했는지 확인한다.
// Task sink
// Binds PULL socket to tcp://localhost:5558
// Collects results from workers via that socket
#include "zhelpers.h"
int main (void)
{
// 컨텍스트와 소켓 준비
void *context = zmq_ctx_new ();
void *receiver = zmq_socket (context, ZMQ_PULL);
zmq_bind (receiver, "tcp://*:5558");
// 배치 시작 대기
char *string = s_recv (receiver);
free (string);
// 지금부터 시간 측정 시작
int64_t start_time = s_clock ();
// 100개의 완료 신호 처리
int task_nbr;
for (task_nbr = 0; task_nbr < 100; task_nbr++) {
char *string = s_recv (receiver);
free (string);
if (task_nbr % 10 == 0)
printf (":");
else
printf (".");
fflush (stdout);
}
// 배치 처리 시간 계산 및 출력
printf ("Total elapsed time: %d msec\n",
(int) (s_clock () - start_time));
zmq_close (receiver);
zmq_ctx_destroy (context);
return 0;
}...(이하 언어별 tasksink 예제 포함)
한 배치의 평균 비용은 5초 정도다. worker를 1개, 2개, 4개로 실행해 보면 sink에서 다음과 같은 결과를 볼 수 있다.
이 코드에서 몇 가지 중요한 점을 자세히 살펴보자.
worker는 upstream(ventilator)과 downstream(sink) 양쪽 모두에 connect 한다. 이는 worker를 마음대로 추가할 수 있음을 의미한다. 만약 worker들이 bind를 했다면, (a) 더 많은 엔드포인트가 필요하고 (b) worker를 추가할 때마다 ventilator나 sink를 수정해야 했을 것이다. 우리는 ventilator와 sink를 아키텍처의 안정적인(stable) 부분이라 부르고, worker들을 동적인(dynamic) 부분이라고 부른다.
배치 시작 시점과 모든 worker의 준비 완료를 동기화해야 한다. 이는 ZeroMQ에서 꽤 흔한 함정이지만, 쉬운 해결책은 없다. zmq_connect 호출에는 일정 시간이 든다. 따라서 다수의 worker가 ventilator에 connect할 때, 가장 먼저 성공적으로 연결된 worker 하나가, 나머지 worker들이 연결되는 짧은 동안에 대량의 메시지를 가져가 버릴 수 있다. 배치 시작을 아무렇게나 맞추지 않으면, 시스템은 전혀 병렬로 동작하지 않는다. ventilator 코드에서 사용자 입력을 기다리는 부분을 제거해 보고, 어떤 일이 벌어지는지 관찰해 보라.
ventilator의 PUSH 소켓은 모든 worker에게 작업을 골고루 분산한다(단, 배치가 나가기 전에 모든 worker가 미리 연결되어 있어야 한다). 이를 _로드 밸런싱(load balancing)_이라고 부르며, 나중에 더 자세히 살펴볼 것이다.
sink의 PULL 소켓은 worker들로부터 결과를 고르게 수집한다. 이를 _공정 큐잉(fair-queuing)_이라고 한다.
그림 6 - 공정 큐잉(Fair Queuing)
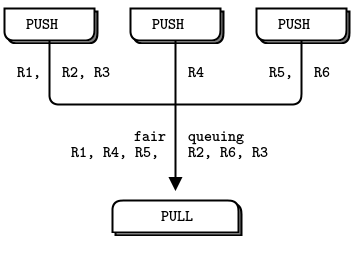
파이프라인 패턴에서도 "느린 합류자" 증상이 나타나며, 그 결과 PUSH 소켓이 제대로 로드 밸런싱을 하지 않는다는 오해를 낳는다. PUSH/PULL을 사용하는데, 어떤 worker가 다른 worker보다 훨씬 많은 메시지를 받는다면, 그 PULL 소켓이 다른 것보다 더 빨리 합류했기 때문이다. 그 worker는 나머지 worker들이 연결을 완료하기 전에 많은 메시지를 먼저 가져간다. 제대로 된 로드 밸런싱을 원한다면, 3장 - 고급 요청-응답 패턴에 나오는 로드 밸런싱 패턴을 살펴보는 것이 좋다.
이제 몇 가지 예제를 본 만큼, ZeroMQ를 실제 앱에 당장 쓰고 싶을 것이다. 그 전에, 잠깐 숨을 고르고 진정한 뒤, 몇 가지 기본적인 조언을 곱씹어 보자. 이 조언들은 나중에 겪을 수많은 스트레스와 혼란을 줄여 줄 것이다.
ZeroMQ는 한 단계씩 배워라. 표면적으로는 하나의 단순한 API지만, 그 속에는 수많은 가능성이 숨어 있다. 가능한 한 천천히, 각 가능성을 하나씩 익혀라.
예쁜 코드를 써라. 추한 코드는 문제를 숨기고, 다른 사람들이 당신을 도와주기 어렵게 만든다. 여러분은 의미 없는 변수 이름에 익숙해질 수 있지만, 코드를 읽는 사람들은 그렇지 않다. 실제 단어이면서, "이 변수는 도대체 무슨 용도인지 설명하기 귀찮아서 그냥 이렇게 지었어요"가 아닌 이름을 써라. 일관된 들여쓰기와 깔끔한 레이아웃을 쓰라. 예쁜 코드를 쓰면, 세상이 더 편안해진다.
만드는 동안 테스트하라. 프로그램이 동작하지 않을 때, 문제의 원인이 되는 코드가 다섯 줄 이내여야 한다. ZeroMQ의 마법을 시도할 때는 특히 그렇다. 처음 시도에는 절대 제대로 동작하지 않을 것이다.
예상과 다른 동작을 발견하면, 코드를 잘게 쪼개고, 각 부분을 따로 테스트해서, 어느 부분이 제대로 동작하지 않는지 찾아라. ZeroMQ는 본질적으로 모듈식 코드를 만들 수 있게 해 준다. 이를 적극적으로 활용하라.
필요할 때 추상화(클래스, 메서드 등)를 만들어라. 코드를 copy/paste 할수록, 버그도 함께 copy/paste 하게 된다.
ZeroMQ 애플리케이션은 항상 _컨텍스트(context)_를 만드는 것부터 시작해, 그 컨텍스트를 사용해 소켓을 만든다. C에서는 zmq_ctx_new() 호출이 그것이다. 한 프로세스 안에서는 정확히 하나의 컨텍스트만 생성해 사용하는 것이 좋다. 기술적으로, 컨텍스트는 한 프로세스 내의 모든 소켓을 담는 컨테이너이며, inproc 소켓(한 프로세스 내의 스레드끼리 연결하기 위한 가장 빠른 수단)을 위한 트랜스포트 역할을 한다. 런타임에 한 프로세스에 컨텍스트가 두 개 있다면, 이는 ZeroMQ 인스턴스가 두 개 있는 것과 같다. 의도적으로 그런 구조를 만든 것이라면 괜찮지만, 그렇지 않다면 다음을 기억하자.
프로세스 시작 시 한 번 zmq_ctx_new()를 호출하고, 종료 시 한 번 zmq_ctx_destroy()를 호출하라.
fork() 시스템 호출을 사용하는 경우에는, fork 이후 자식 프로세스 코드의 맨 앞에서 zmq_ctx_new()를 호출해야 한다. 일반적으로 흥미로운(ZeroMQ와 관련된) 일은 자식 프로세스에서 하고, 부모 프로세스는 지루한 프로세스 관리만 하는 것이 좋다.
품격 있는 프로그래머들은 품격 있는 해결사(hit man)와 같은 좌우명을 갖고 있다. "일을 마치면 항상 흔적을 지운다." 파이썬 같은 언어에서는 ZeroMQ를 사용할 때 많은 것들이 자동으로 해제된다. 하지만 C를 사용할 때는, 다 쓴 객체들을 조심스럽게 해제해야 한다. 그렇지 않으면 메모리 누수, 불안정한 애플리케이션, 전반적으로 나쁜 카르마를 얻게 된다.
메모리 누수도 문제지만, ZeroMQ는 애플리케이션 종료 방식에 꽤 까다롭다. 이유는 기술적이고 복잡하지만, 요점은 이렇다. 소켓을 하나라도 열어 놓은 채로 두면, zmq_ctx_destroy()가 영원히 블록된다는 것이다. 심지어 모든 소켓을 닫았다 하더라도, 기본적으로 zmq_ctx_destroy()는 pending connect나 send가 있는 한 계속 기다린다. 이때는 소켓을 닫기 전에 해당 소켓의 LINGER를 0으로 설정해야 한다.
ZeroMQ에서 우리가 신경 써야 할 객체는 메시지, 소켓, 컨텍스트다. 다행히 단순한 프로그램에서는 다음 규칙만 따르면 된다.
가능하면 zmq_send()와 zmq_recv()를 사용하라. 그러면 zmq_msg_t 객체를 직접 다룰 필요가 없다.
zmq_msg_recv()를 사용했다면, 받은 메시지는 다 사용한 즉시 zmq_msg_close()로 해제해야 한다.
소켓을 매우 자주 열고 닫는다면, 아키텍처를 다시 설계해야 할 신호일 수 있다. 어떤 경우에는, 컨텍스트를 파괴할 때까지 소켓 핸들이 실제로는 해제되지 않는다.
프로그램을 종료할 때는, 소켓을 모두 닫은 뒤 zmq_ctx_destroy()를 호출해 컨텍스트를 파괴하라.
C 개발에 관한 이야기였다. 자동 객체 파괴 기능이 있는 언어에서는, 스코프를 벗어날 때 소켓과 컨텍스트가 함께 파괴된다. 예외를 사용하는 경우에는, 다른 자원과 마찬가지로 finally 블록 같은 곳에서 정리 코드를 넣어야 한다.
멀티스레딩을 사용한다면, 이야기가 조금 더 복잡해진다. 멀티스레딩은 다음 장에서 다룰 것이다. 하지만 몇몇 독자들은 경고에도 불구하고 먼저 달리기 시작할 테니, 멀티스레드 ZeroMQ 애플리케이션에서 깔끔하게 종료하는 요령을 간단히 적어 둔다.
첫째, 하나의 소켓을 여러 스레드에서 동시에 사용하지 말라. 왜 그게 재미있어 보이는지 설명하지 말고, 그냥 그러지 말자. 둘째, 진행 중인 요청이 있는 각 소켓을 셧다운해야 한다. 올바른 방법은 LINGER 값을 짧게(예: 1초) 설정한 뒤 소켓을 닫는 것이다. 사용 중인 언어 바인딩이 컨텍스트를 파괴할 때 자동으로 이렇게 해주지 않는다면, 패치를 보내 보라.
마지막으로 컨텍스트를 파괴한다. 그러면 같은 컨텍스트를 공유하는 스레드들에서 블록 상태였던 recv, poll, send 호출이 에러를 반환하게 된다. 그 에러를 잡아낸 뒤, 해당 스레드 안에서 LINGER를 설정하고 소켓들을 닫고, 스레드를 종료하면 된다. 같은 컨텍스트를 두 번 파괴해서는 안 된다. 메인 스레드에서의 zmq_ctx_destroy는 자신이 알고 있는 모든 소켓이 안전하게 닫힐 때까지 블록된다.
보라! 충분히 복잡하고 귀찮기 때문에, 제대로 된 언어 바인딩 제작자는 이 동작을 자동으로 처리하고, 사용자가 소켓 종료 댄스를 직접 춰야 할 필요가 없도록 해 줄 것이다.
이제 ZeroMQ를 실제로 본 만큼, 다시 "왜"라는 질문으로 돌아가 보자.
요즘 많은 애플리케이션은 LAN이든 인터넷이든 어떤 네트워크를 가로질러 늘어선 컴포넌트들로 이뤄져 있다. 그래서 많은 개발자들이 결국은 메시징을 하게 된다. 어떤 개발자들은 메시지 큐 제품을 사용하지만, 대부분의 경우는 TCP나 UDP를 직접 사용해 스스로 해결한다. 이 프로토콜들은 사용하는 것 자체는 어렵지 않다. 하지만 A에서 B로 몇 바이트를 전송하는 일과, 어떤 식으로든 신뢰할 수 있는 메시징을 구현하는 일 사이에는 큰 간극이 있다.
생(raw) TCP를 사용해 컴포넌트들을 연결하기 시작하면, 다음과 같은 전형적인 문제들에 부딪힌다. 재사용 가능한 메시징 레이어라면, 적어도 이들 대부분은 해결해야 한다.
I/O를 어떻게 다룰 것인가? 애플리케이션을 블록시킬 것인가, 아니면 백그라운드에서 I/O를 처리할 것인가? 이는 핵심적인 설계 결정이다. 블로킹 I/O는 잘 확장되지 않는 아키텍처를 만든다. 하지만 백그라운드 I/O는 제대로 구현하기 매우 어렵다.
동적인 컴포넌트, 즉 잠깐씩 사라지는 구성 요소들을 어떻게 다룰 것인가? 컴포넌트를 공식적으로 "클라이언트"와 "서버"로 나누고, 서버는 절대 사라지지 않는다고 강제할 것인가? 그렇다면 서버와 서버를 연결하고 싶을 때는 어떻게 할 것인가? 몇 초마다 재연결을 시도할 것인가?
메시지를 와이어 상에서 어떻게 표현할 것인가? 버퍼 오버플로에 안전하고, 작은 메시지에 효율적이며, 동시에 가장 큰 고양이 파티 동영상까지 담을 수 있을 만큼 유연한 프레이밍을 어떻게 할 것인가?
즉시 전달할 수 없는 메시지들은 어떻게 할 것인가? 특히, 어떤 컴포넌트가 다시 온라인으로 돌아오기를 기다리는 동안은? 메시지를 버릴 것인가, 데이터베이스에 넣을 것인가, 메모리 큐에 넣을 것인가?
메시지 큐를 어디에 둘 것인가? 큐에서 읽는 컴포넌트가 매우 느려 큐가 점점 쌓인다면 어떻게 할 것인가? 그때의 전략은?
메시지가 유실되면 어떻게 할 것인가? 새로운 데이터를 기다릴 것인가, 재전송을 요청할 것인가, 아니면 메시지가 절대 유실되지 않도록 보장하는 신뢰 계층을 만들 것인가? 그 계층이 크래시한다면?
다른 네트워크 트랜스포트를 사용해야 한다면 어떻게 할 것인가? 예를 들어, TCP 유니캐스트 대신 멀티캐스트나 IPv6를 써야 한다면? 애플리케이션을 다시 써야 할까, 아니면 트랜스포트를 어떤 레이어에서 추상화할 수 있을까?
메시지를 어떻게 라우팅할 것인가? 같은 메시지를 여러 피어에게 보낼 수 있을까? 원래 요청자에게 응답을 돌려보낼 수 있을까?
다른 언어를 위한 API는 어떻게 쓸 것인가? 와이어 레벨 프로토콜을 다시 구현할 것인가, 아니면 라이브러리를 래핑할 것인가? 전자의 경우, 어떻게 효율적이고 안정적인 스택을 보장할 수 있을까? 후자의 경우, 상호 호환성을 어떻게 보장할 수 있을까?
데이터를 어떻게 표현해야 서로 다른 아키텍처에서 읽을 수 있을까? 특정 데이터 타입 인코딩을 강제할 것인가? 어디까지가 메시징 시스템의 책임이고, 어디서부터가 상위 레이어의 책임인가?
네트워크 에러를 어떻게 다룰 것인가? 기다렸다가 재시도할 것인가, 조용히 무시할 것인가, 아니면 즉시 종료할 것인가?
Hadoop Zookeeper 같은 전형적인 오픈소스 프로젝트를 예로 들어보자. C API 코드인 src/c/src/zookeeper.c를 읽어 보라. 내가 이 코드를 처음 읽었을 때(2013년 1월), 4,200줄의 난해한 코드 속에 문서화되지 않은 클라이언트/서버 네트워크 통신 프로토콜이 숨어 있었다. select 대신 poll을 써서 효율적으로 만들려 애쓴 흔적은 보인다. 하지만 사실 Zookeeper는 재사용 가능한 메시징 레이어와, 명시적으로 문서화된 와이어 레벨 프로토콜을 사용했어야 한다. 이 특정 바퀴를 모든 팀이 매번 다시 만드는 것은 엄청난 낭비다.
그렇다면, 재사용 가능한 메시징 레이어는 어떻게 만들 수 있을까? 왜 이렇게 많은 프로젝트들이 이 기술을 필요로 함에도 불구하고, 사람들은 여전히 TCP 소켓을 직접 코드에서 몰고 다니며, 위에서 나열한 문제들을 매번 처음부터 다시 풀고 있을까?
알고 보니, 재사용 가능한 메시징 시스템을 만드는 일은 정말로 어렵다. 그래서 이걸 제대로 시도한 FOSS 프로젝트가 거의 없고, 상용 메시징 제품들은 복잡하고 비싸며, 유연하지 않고, 깨지기 쉽다. 2006년에 iMatix는 AMQP를 설계했다. 이는 FOSS 개발자들에게 메시징 시스템을 위한 최초의 재사용 가능한 레시피 중 하나를 제공했다. AMQP는 많은 다른 설계들보다 낫게 동작하지만, 여전히 상당히 복잡하고 비싸며 취약하다. 사용하는 데 몇 주가 걸리고, 험한 상황에서도 크래시하지 않는 안정적인 아키텍처를 만드는 데에는 몇 달이 걸린다.
그림 7 - 메시징의 시작

AMQP 같은 대부분의 메시징 프로젝트들은, 이 긴 문제 목록을 재사용 가능한 방식으로 풀기 위해 "브로커(broker)"라는 새로운 개념을 도입한다. 브로커는 주소 지정, 라우팅, 큐잉을 담당한다. 그러면 애플리케이션은 이 브로커와 통신할 수 있도록 클라이언트/서버 프로토콜이나, 어떤 문서화되지 않은 프로토콜 위에 올라선 API 집합을 사용하게 된다. 큰 네트워크의 복잡성을 줄이는 데에는 브로커가 훌륭하다. 하지만 브로커 기반 메시징을 Zookeeper 같은 제품에 붙이는 것은, 상황을 더 나쁘게 만들 뿐이다. 큰 박스를 하나 더 얹고, 새로운 단일 장애점을 추가하는 꼴이기 때문이다. 브로커는 금세 병목이자 새로 관리해야 할 위험 요소가 된다. 소프트웨어가 이를 지원한다면 두 번째, 세 번째, 네 번째 브로커를 추가하고, 어떤 페일오버 스킴을 짤 수 있다. 사람들이 실제로 그렇게 한다. 그러면 더 많은 움직이는 부품, 더 많은 복잡성, 더 많은 고장 가능성이 생긴다.
그리고 브로커 중심 구성을 사용하면, 그걸 운영하기 위한 별도의 운영팀이 필요하다. 브로커들을 밤낮 없이 지켜보고, 말썽을 부리면 몽둥이질해야 한다. 박스를 더 두고, 백업 박스도 두어야 하며, 이 박스들을 돌볼 사람도 필요하다. 이런 투자는 여러 팀이 수년에 걸쳐 만드는, 많은 부품을 가진 대규모 애플리케이션에나 어울린다.
그림 8 - 메시징의 끝

그래서 중소 규모 애플리케이션 개발자들은 진퇴양난이다. 네트워크 프로그래밍을 피하고 확장되지 않는 단일체(monolithic) 애플리케이션을 만들든지, 아니면 네트워크 프로그래밍에 뛰어들어 복잡하고 유지보수하기 어려운 깨지기 쉬운 애플리케이션을 만들든지. 아니면 메시징 제품에 의존해, 잘 확장되긴 하지만 비싸고 쉽게 깨지는 기술에 의존하는 애플리케이션을 만들든지. 딱히 좋은 선택지가 없었기 때문에, 메시징은 대체로 20세기에 머물러 있었고, 사용자들에게는 부정적인 감정, 지원·라이선스를 판매하는 이들에게는 즐거운 미소를 안겨 주던 분야였다.
우리가 필요로 했던 것은, 메시징의 일을 해내지만, 그 일을 너무나 단순하고 저렴하게 수행해서, 어떤 애플리케이션에도 거의 비용 없이 쓸 수 있는 무언가였다. 그냥 링크해서 쓰면 되는 라이브러리여야 한다. 그 외에 다른 의존성은 없어야 한다. 추가적인 움직이는 부품이 없어야 하니, 추가적인 위험도 없어야 한다. 어떤 OS에서든 돌아가고, 어떤 프로그래밍 언어와도 함께 사용할 수 있어야 한다.
ZeroMQ가 바로 그것이다. 효율적이고 임베디드 가능한 라이브러리로, 애플리케이션이 네트워크를 가로질러 자연스럽게(scale-out) 확장되도록 도와주는 대부분의 문제를, 거의 비용 없이 해결해 준다.
좀 더 구체적으로 말하면,
ZeroMQ는 백그라운드 스레드에서 비동기적으로 I/O를 처리한다. 이 스레드들은 락이 없는 데이터 구조를 사용해 애플리케이션 스레드와 통신하므로, ZeroMQ를 사용하는 동시성 애플리케이션은 별도의 락이나 세마포어, 기타 대기 상태를 필요로 하지 않는다.
컴포넌트들은 동적으로 나타났다 사라질 수 있고, ZeroMQ는 자동으로 재연결을 수행한다. 이는 컴포넌트를 어떤 순서로든 시작할 수 있음을 의미한다. 언제든 네트워크에 합류하고 떠날 수 있는 서비스들로 구성된 "서비스 지향 아키텍처(SOA)"를 만들 수 있다.
필요할 때는 메시지를 자동으로 큐잉한다. ZeroMQ는 이를 영리하게 처리해, 메시지를 큐에 넣기 전에 가능한 한 수신자에 가까운 위치까지 밀어 넣는다.
큐가 가득 찼을 때의 처리(이른바 "high-water mark")를 제어할 수 있다. 큐가 가득 차면, ZeroMQ는 사용하는 메시징 패턴 종류에 따라 자동으로 송신자를 블록시키거나, 메시지를 버린다.
애플리케이션이 서로 다른 트랜스포트(TCP, 멀티캐스트, 인-프로세스, 프로세스 간) 위에서 통신하도록 해 준다. 코드를 바꾸지 않고 트랜스포트를 바꿀 수 있다.
느리거나 블록된 리더를 안전하게 처리한다. 사용하는 메시징 패턴에 따라 서로 다른 전략을 제공한다.
요청-응답(request-reply), 발행-구독(pub-sub) 등 다양한 패턴을 통해 메시지를 라우팅할 수 있다. 이 패턴들이 네트워크 위에서 토폴로지, 즉 구조를 만드는 수단이다.
한 호출로 큐잉, 포워딩, 메시지 캡처를 수행하는 프락시를 만들 수 있다. 프락시는 네트워크 상의 연결 복잡도를 줄여 준다.
와이어 상에서 메시지를 있는 그대로, 전송된 그대로 전달한다. 간단한 프레이밍을 사용하므로, 10k 메시지를 쓰면 10k 메시지를 그대로 받는다.
메시지 포맷에 아무 제약을 두지 않는다. 메시지는 0 바이트에서 기가바이트까지의 블롭(blob)일 수 있다. 데이터를 표현할 때는 msgpack, Google Protocol Buffers 같은, 다른 상위 제품을 선택하면 된다.
네트워크 에러를 지능적으로 처리한다. 의미 있는 경우에는 자동으로 재시도한다.
탄소 발자국을 줄여 준다. 적은 CPU로 더 많은 일을 한다는 것은, 박스들이 더 적은 전력을 쓰고, 오래된 박스를 더 오래 쓸 수 있다는 뜻이다. 알 고어는 ZeroMQ를 사랑할 것이다.
사실 ZeroMQ는 이보다 더 많은 일을 한다. ZeroMQ는 네트워크 대응 애플리케이션을 개발하는 방식 자체에 은근한 변화를 일으킨다. 표면적으로 ZeroMQ는 zmq_recv(), zmq_send()를 호출하는 소켓스러운 API다. 하지만 금세 메시지 처리 루프가 애플리케이션의 중심이 되고, 애플리케이션은 여러 개의 메시지 처리 작업들로 쪼개진다. 이는 우아하고 자연스럽다. 그리고 잘 확장된다. 각 작업은 하나의 노드에 대응되고, 노드들은 여러 트랜스포트 위에서 서로 통신한다. 하나의 프로세스 안에서 두 노드(노드는 스레드), 하나의 박스 안에서 두 노드(노드는 프로세스), 하나의 네트워크 안에서 두 노드(노드는 박스) — 이것들은 모두 같은 것이고, 애플리케이션 코드를 바꿀 필요도 없다.
ZeroMQ의 확장성을 실제로 보자. 다음은 날씨 서버를 실행한 뒤, 여러 클라이언트를 병렬로 실행하는 셸 스크립트다.
wuserver &
wuclient 12345 &
wuclient 23456 &
wuclient 34567 &
wuclient 45678 &
wuclient 56789 &클라이언트들이 실행되는 동안 top 같은 명령으로 활성 프로세스를 보면, (4코어 박스에서) 대략 이런 모습을 보게 된다.
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
7136 ph 20 0 1040m 959m 1156 R 157 12.0 16:25.47 wuserver
7966 ph 20 0 98608 1804 1372 S 33 0.0 0:03.94 wuclient
7963 ph 20 0 33116 1748 1372 S 14 0.0 0:00.76 wuclient
7965 ph 20 0 33116 1784 1372 S 6 0.0 0:00.47 wuclient
7964 ph 20 0 33116 1788 1372 S 5 0.0 0:00.25 wuclient
7967 ph 20 0 33072 1740 1372 S 5 0.0 0:00.35 wuclient여기서 어떤 일이 벌어지는지 잠시 생각해 보자. 날씨 서버에는 소켓이 하나뿐인데, 동시에 다섯 개의 클라이언트에 데이터를 보내고 있다. 이론적으로는 수천 개의 동시 클라이언트를 둘 수도 있다. 서버 애플리케이션은 이 클라이언트들을 보지도 않고, 직접 대화하지도 않는다. ZeroMQ 소켓은 작은 서버처럼 동작하면서, 조용히 클라이언트 요청을 받아들이고, 네트워크가 처리할 수 있는 한 빠르게 데이터를 밀어 넣는다. 그리고 멀티스레드 서버이기도 해서, CPU에서 더 많은 성능을 뽑아낸다.
이 변경 사항들은 기존 애플리케이션 코드에 직접적인 영향을 주지 않는다.
pub-sub 필터링이 subscriber 측이 아니라 publisher 측에서 수행된다. 이는 많은 pub-sub 사용 사례에서 성능을 크게 향상시킨다. 3.2와 2.1/2.2 버전의 publisher와 subscriber를 섞어 써도 안전하다.
ZeroMQ 3.2에는 여러 새 API 메서드가 추가되었다. (zmq_disconnect(), zmq_unbind(), zmq_monitor(), zmq_ctx_set() 등)
다음은 애플리케이션과 언어 바인딩에 주요한 영향을 주는 부분들이다.
zmq_send()와 zmq_recv()의 인터페이스가 더 단순한 형태로 변경되었다. 예전 기능은 이제 zmq_msg_send()와 zmq_msg_recv()가 제공한다. 증상: 컴파일 에러. 해결: 코드를 수정해야 한다.
이 두 메서드는 성공 시 양수 값을, 에러 시 -1을 반환한다. 2.x에서는 성공 시 항상 0을 반환했다. 증상: 실제로는 잘 동작하는데도 에러처럼 보인다. 해결: 반환값이 0이 아닌지를 보지 말고, 정확히 -1인지 여부만 검사하라.
zmq_poll()는 이제 마이크로초가 아니라 밀리초 단위로 대기한다. 증상: 애플리케이션이 반응을 멈춘 것처럼 보이거나(사실은 1000배 느려진 것뿐이다). 해결: 아래 정의된 ZMQ_POLL_MSEC 매크로를 모든 zmq_poll 호출에 사용하라.
ZMQ_NOBLOCK는 이제 ZMQ_DONTWAIT라는 이름을 쓴다. 증상: ZMQ_NOBLOCK 매크로에서 컴파일 실패.
ZMQ_HWM 소켓 옵션은 ZMQ_SNDHWM과 ZMQ_RCVHWM으로 나뉘었다. 증상: ZMQ_HWM 매크로에서 컴파일 실패.
대부분(하지만 전부는 아님)의 zmq_getsockopt() 옵션은 이제 정수 값을 사용한다. 증상: zmq_setsockopt 및 zmq_getsockopt에서 런타임 에러.
ZMQ_SWAP 옵션이 제거되었다. 증상: ZMQ_SWAP에서 컴파일 실패. 해결: 이 기능을 사용하는 코드는 다시 설계해야 한다.
2.x와 3.2 둘 다에서 돌아가야 하는 애플리케이션(언어 바인딩 등)을 위해서는, 가능한 한 3.2를 흉내 내는 것이 좋다. 아래는 C/C++ 코드가 두 버전 모두에서 동작하도록 도와주는 C 매크로 정의다(출처: CZMQ).
#ifndef ZMQ_DONTWAIT
# define ZMQ_DONTWAIT ZMQ_NOBLOCK
#endif
#if ZMQ_VERSION_MAJOR == 2
# define zmq_msg_send(msg,sock,opt) zmq_send (sock, msg, opt)
# define zmq_msg_recv(msg,sock,opt) zmq_recv (sock, msg, opt)
# define zmq_ctx_destroy(context) zmq_term(context)
# define ZMQ_POLL_MSEC 1000 // zmq_poll는 usec 단위
# define ZMQ_SNDHWM ZMQ_HWM
# define ZMQ_RCVHWM ZMQ_HWM
#elif ZMQ_VERSION_MAJOR == 3
# define ZMQ_POLL_MSEC 1 // zmq_poll는 msec 단위
#endif전통적인 네트워크 프로그래밍은 한 소켓이 하나의 연결, 하나의 피어와 대화한다는 일반적인 가정 위에 서 있다. 멀티캐스트 프로토콜도 있긴 하지만, 이는 다소 이질적인 존재다. "하나의 소켓 = 하나의 연결"이라는 가정 아래 우리는 아키텍처를 특정 방식으로 확장해 왔다. 각 소켓, 각 피어와 대화하는 하나의 스레드를 만들고, 그 스레드 안에 상태와 지능을 집어넣는다.
ZeroMQ의 세계에서 소켓은, 여러 개의 연결을 자동으로 관리해 주는 빠른 백그라운드 통신 엔진으로 들어가는 문과 같다. 우리는 이 연결들을 볼 수도, 직접 다룰 수도, 열거나 닫을 수도, 그 위에 상태를 올려놓을 수도 없다. 블로킹 send/recv를 쓰든, poll을 쓰든, 우리가 직접 만지는 것은 소켓뿐이지, 소켓이 관리하는 연결들은 아니다. 이 연결들은 비공개이자 보이지 않으며, 이것이 ZeroMQ가 확장성을 갖는 비결이다.
이 덕분에, 여러분의 코드가 소켓과만 대화하면, 어떤 수의 연결이든, 어떤 네트워크 프로토콜이든 상관없이, 코드 변경 없이 처리할 수 있다. 메시징 패턴이 애플리케이션 코드 안에 있을 때보다, ZeroMQ 안에 자리잡고 있을 때 훨씬 더 싸게(scale-out 비용이 적게) 확장된다.
그러니 기존의 가정은 더 이상 맞지 않는다. 예제 코드를 읽을 때, 여러분의 뇌는 그것을 아는 것에 맞춰 해석하려 들 것이다. 여러분은 "socket"이라는 단어를 보고, "아, 이건 다른 노드와의 하나의 연결을 나타내는구나"라고 생각할 것이다. 틀렸다. 여러분은 "thread"라는 단어를 보고, 또다시 "아, 스레드는 다른 노드와의 하나의 연결을 나타내는구나"라고 생각할 것이고, 여전히 틀릴 것이다.
이 가이드를 처음 읽고 있다면, ZeroMQ 코드를 하루나 이틀(아마도 3~4일) 써 보기 전까지는 혼란스러울 수 있다. 특히 ZeroMQ가 여러분에게 얼마나 많은 것을 단순하게 만들어 주는지 느끼면서, 무의식적으로 옛 가정을 ZeroMQ에 씌워 보려 들 것이다. 하지만 그렇게는 동작하지 않는다. 그리고 어느 순간, 여러분은 깨달음을 얻게 될 것이다. 짜릿한 사토리, 패러다임 전환의 순간. 모든 것이 명확해지는 그 순간.