원자 변수의 핵심은 단순한 원자성이 아니라 메모리 순서 제약을 통해 스레드 간 동기화를 성립시키는 데 있으며, 저수준 동기화에서 흔한 함정과 이를 검증·설계 원칙으로 피하는 방법을 살펴본다.
URL: https://sander.saares.eu/2026/01/25/atomic-variables-are-not-only-about-atomicity/
코드는 컴파일된다. 모든 테스트도 통과한다. 스테이징 환경도 멀쩡하다. 그런데도 하루에 한 번쯤, 프로덕션 플릿의 몇몇 서버가 이해할 수 없는 오류 메시지와 함께 미스터리하게 크래시를 관측한다. 도달 불가능한 코드에 도달했다거나, 최대 8개만 담을 수 있는 컬렉션에서 9개를 꺼냈다거나, 그런 류의 메시지다. 직접 동기화 프리미티브를 굴리기 시작하면 만나는 세계에 오신 것을 환영한다.
코드 광산에서 20년을 보낸 뒤에도, 커스텀 스레드 동기화 로직을 마주하면 작성자 머릿속에 공포와 의심이 스민다. 실수하기는 너무 쉽고, 알아채기는 너무 어렵다.
중요한 점은, 오늘날의 AI-강화 엔지니어링 루프에서는 우리가 깨닫지 못한 채 커스텀 동기화 로직을 코드에 포함시키는 상황이 생길 수 있다는 것이다! 경험적 증거에 따르면 LLM은 뮤텍스나 메시징 채널 같은 더 안전한 대안이 있는데도, 원자 변수를 사용해 커스텀 멀티스레드 신호/동기화 로직을 작성하는 데 꽤 만족해하는 경향이 있다.
동기화 로직을 제대로 다루려면 책 한 권 분량이 되겠지만, 이 글은 커스텀 동기화 프리미티브의 기초 일부를 조망하는 것을 목표로 한다. AI 코딩 어시스턴트가 생성한 로직을 최소한 리뷰하고 검증하는 데 도움이 될 수 있는 필수 지식을 접근 가능한 형태로 제공하려 한다.
동기화 프리미티브를 만들 때 쓰이는 핵심 재료는 두 가지다.
이 글은 전자만 다룬다. 더 높은 수준의 동기화 프리미티브를 의도적으로 피하는 상황에서, 원자 변수가 제공하는 활용법과 로직 동기화의 근본 능력을 살펴본다. 흔한 함정을 탐구하고, 관련 검증 도구와 몇 가지 핵심 설계 원칙을 적용해 이를 피하는 방법을 본다.
“원자 변수”라는 이름은 매우 오해를 부른다. 이 이름은 변수의 원자성(atomicity) 성질을 과도하게 강조한다. 원자성은 실제로 존재하며 이 주제와 관련이 있지만, 원자 변수는 원자성만큼이나 중요한 다른 성질들도 가진다. 이 불행한 명명 편향은 이 주제가 역사적으로 증명되었듯 이해하기 어려운 이유 중 하나였을 가능성이 크다. 우리가 원자 변수를 사용하는 이유는 (오직) 원자적이기 때문이 아닌 경우가 많다!
특히 이 글에서는 원자 변수의 원자성과 메모리 순서 성질을 아주 명확히 구분하려 한다. 먼저, 두 스레드에서 카운터를 증가시키려는 고전적인 멀티스레딩 예제부터 시작한다.
참고: 이 글의 코드 스니펫은 핵심만 보여주는 발췌본이다. 전체 저장소는 https://github.com/sandersaares/order-in-memory 에 있다.
두 스레드가 공유 데이터를 다루는데, 프로그래밍 실수로 프로그램이 잘못된 결과로 끝난다. 무슨 일이 벌어지는지, 왜 그런지, 어떻게 고치는지 보자.
프로그램은 두 개의 스레드로 구성되며, 둘 다 같은 카운터를 증가시킨다.

각 스레드는 카운터를 100만 번 증가시키므로, 카운터 값은 200만이 되길 기대한다.
루프 안에서
black_box()를 쓰는 점에 주목하라. 이는 컴파일러가 전체 루프를 “+= 1_000_000”으로 최적화해 버리는 것을 막기 위해 중요하다. 블랙박스는 증가 연산과 루프 사이에 최적화 장벽을 만든다. 우리가 작성한 코드가 하드웨어가 실행하는 코드와 항상 같지는 않다. 허용되는 컴파일러 변환을 이해하는 것은 저수준 프리미티브로 올바른 멀티스레드 코드를 작성하는 데 결정적일 수 있다.
또한
unsafe블록 사용에 주목하라. Rust는 여기서 발을 쏘지 않도록 보호하려고 하며, 기본 안전 모드에서는 이런 잘못된 멀티스레드 로직을 작성하지 못하게 한다.unsafe가 곧 “무효”를 뜻하는 것은 아니다. 단지 프로그래머가 컴파일러의 일부 책임을 넘겨받는다는 의미다. 하지만 이 예제에서는 실제로 무효가 맞다. 예시를 위해 의도적으로 책임을 다하지 않을 것이다.
이 코드를 실행하면 실행할 때마다 다른 답이 나오지만, 거의 항상 카운터가 기대값 200만에 도달하지 못해 assertion 실패가 난다.
cargo run --example 01_failure_to_increment --release --quiet
thread 'main' (34824) panicked at examples\01_failure_to_increment.rs:27:5:
assertion left == right failed
left: 1105737
right: 2000000
Intel/AMD와 ARM(예: Mac) 등 서로 다른 하드웨어 플랫폼에 접근할 수 있다면 둘 다에서 이 코드를 실행해 보라. 흥미롭게도 결과가 다를 수 있다. 차이를 발견했다면, 왜 그런 차이가 존재하는지에 대한 최선의 추측을 댓글로 남겨 달라.
이 예제의 단순한 설명은, 각 루프 반복이 다음으로 구성된다는 것이다.
즉시 두 스레드가 서로 방해할 수 있는 방식이 떠오른다.
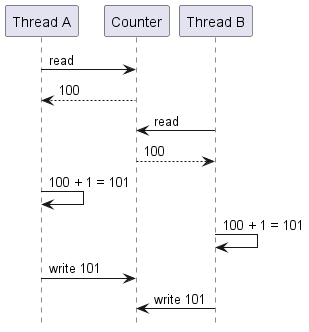
두 스레드가 같은 값을 로드하고, 각각 1 증가시킨 뒤, 동시에(또는 거의 동시에) 새 값을 저장할 수 있다. 논리적으로는 증가가 두 번 일어났지만 값은 1만 증가한다.
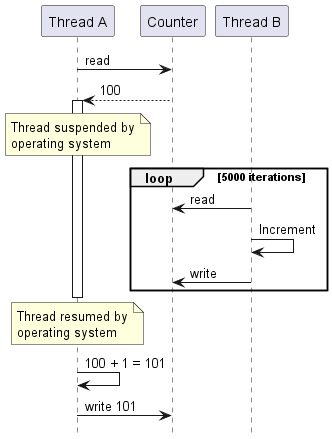
또는 한 스레드가 값 N을 로드한 뒤 OS에 의해 중단되었다가, 다른 스레드가 5000번 증가시켜 N+5000이 된 후, 원래 스레드가 재개되어 N+1을 써 버리면 다른 스레드의 5000번 증가가 지워진다.
이것은 데이터 레이스이며, Rust에서는 정의되지 않은 동작(Undefined Behavior)으로 간주된다. 이 프로그램은 유효하지 않다.
해결은 간단하다. 이 카운터가 여러 스레드에서 동시에 접근된다는 사실을 컴파일러에 알려야 한다. 이것이 원자 변수가 해결할 수 있는 부분이다. 원자 변수의 원자성 성질은, 원자 변수에 대해 수행되는 어떤 연산도 동시에 몇 개의 스레드가 접근하든 동일한 효과를 보장한다. 여러 스레드가 동시에 어떤 데이터에 접근하고 그중 하나라도 쓰기를 한다면, 그 데이터에는 원자 변수를 사용해야 한다.
이를 적용하려면 카운터를 u64에서 AtomicU64로 바꾼다. 증가를 위해 += 대신 fetch_add()를 사용한다. 이 메서드는 또한 해당 연산에 적용할 메모리 순서 제약을 지정하는 인자를 요구한다. 이 예제에서는 Relaxed 순서를 지정하는데, 이는 “제약 없음”을 의미하며 컴파일러와 하드웨어에 최대한의 자유를 준다.
이제 unsafe 키워드는 필요 없다. 안전한 Rust 코드에서는 데이터 레이스가 불가능하기 때문이다. 다만 안전한 Rust 코드에서도 (동기화 로직 오류를 포함한) 논리 오류는 여전히 가능하다. “안전(safe)”은 “정확(correct)”을 뜻하지 않는다. 그래도 unsafe를 없애면 잠재 오류의 한 클래스가 통째로 제거되므로 매우 바람직한 변화다.
프로그램을 실행하면 기대대로 항상 200만이 나온다.
cargo run --example 02_failure_to_increment_fixed --release --quiet
All increments were correctly applied.
이 첫 예제의 요점은, 원자 변수의 원자성 성질이 여러 스레드가 같은 변수를 마치 단일 스레드에서 일어나는 것처럼 다룰 수 있게 해 준다는 점을 강조하는 데 있다.
여기서 핵심은 “그 변수에 대해서(on that variable)”라는 부분이다! 다뤄야 할 변수가 둘 이상이면 원자성만으로는 충분하지 않다. 그때 메모리 순서 제약이 등장한다. 다만 그 전에 잠깐 샛길로 빠져 보자.
unsafe 키워드를 전혀 쓰지 않는다면, 안전한 Rust의 약속 중 하나로서 코드에 데이터 레이스가 없음을 확신할 수 있다. 하지만 unsafe 코드를 사용한다면? unsafe는 정당한 Rust 기능이며, 단지 가드레일을 낮춰 컴파일러가 완전히 검증할 수 없는(그러나 우리가 완전히 유효하다고 믿는) 코드를 작성할 수 있게 한다.
문제는 “우리가 믿는다”는 부분이다! 저수준 동기화 로직에서 실수하면 수년간 알아채지 못할 수 있다. 하루에 10번, 10,000대 서버 중 무작위 서버 한 대가 재현 불가능한 기괴한 크래시를 일으키고, 덤프도 말이 안 되어 수천 개의 실제 사용자 세션이 날아가는 식으로만 관측될지도 모른다. 이런 실패는 이론이 아니다. 그 10,000대 서버는 아주 현실이었고, 작성자는 실제로 그런 수개월짜리 탐정 놀이를 겪었다.
좋은 소식은 Rust가 여기서 도움을 준다는 것이다. Rust 툴체인에는 Miri 분석 도구가 포함되어 있고, 이는 데이터 레이스와 기타 무효 코드를 탐지할 수 있다. Cargo의 “run”이나 “test” 명령을 감싸는 래퍼로 사용하면 된다. 예를 들어 첫 번째 예제를 Miri로 실행하려면:
rustup toolchain install nightly
rustup +nightly component add miri
cargo +nightly miri run --example 01_failure_to_increment
error: Undefined Behavior: Data race detected between (1) non-atomic write on thread `unnamed-1` and (2) non-atomic read on thread `unnamed-2` at alloc1
--> examples\01_failure_to_increment.rs:19:17
|
19 | COUNTER += 1;
| ^^^^^^^^^^^^ (2) just happened here
|
help: and (1) occurred earlier here
--> examples\01_failure_to_increment.rs:11:17
|
11 | COUNTER += 1;
| ^^^^^^^^^^^^
= help: this indicates a bug in the program: it performed an invalid operation, and caused Undefined Behavior
= help: see https://doc.rust-lang.org/nightly/reference/behavior-considered-undefined.html for further information
= note: this is on thread `unnamed-2`
note: the current function got called indirectly due to this code
--> examples\01_failure_to_increment.rs:16:20
|
16 | let thread_b = thread::spawn(|| {
| ____________________^
17 | | for _ in 0..INCREMENT_COUNT {
18 | | _ = black_box(unsafe {
19 | | COUNTER += 1;
... |
22 | | });
| |______^
Miri는 데이터 레이스를 보자마자 즉시 불평한다. 다만 탐지는 예제/테스트가 실제로 문제의 실행 순서를 밟아야만 가능하므로, 항상 쉽게 구성되지는 않는다. 그럼에도 테스트/예제 커버리지가 있는 코드라면 매우 값진 검증 도구다.
unsafe 키워드가 들어간 코드는 Miri로 테스트하는 것을 필수로 여겨야 한다.
또한 Miri는, unsafe에 의존하는 서드파티 크레이트를 직접 사용하는 안전 코드에 대해서도(서드파티 자체 테스트에 더해) 추가 안전망으로 강력 추천된다. 안전 코드라도 Miri로 검증하는 것은, 작성자에게 실제로 가치가 있었고 서드파티 크레이트의 문제를 드러내기도 했다. 심지어 이미 충분히 테스트되고 실전 검증이 끝났을 것 같은 유명 크레이트에서조차 말이다.
Miri는 단독 바이너리와 테스트 모두 실행할 수 있지만, 사용 시 몇 가지 특별한 주의가 필요하다. Miri는 에뮬레이터 같은 것으로, 어쩌면 별도의 운영체제/하드웨어 플랫폼에 더 가깝다고 생각하는 편이 낫다. 이 에뮬레이션된 플랫폼에는 실제 Windows/Linux/Mac OS가 돌아가지 않으므로, 앱이 OS와 대화하려 하면 패닉이 난다. 일부 OS API는 에뮬레이션되지만 대부분은 아니다. 예를 들어 네트워크 통신이나 추가 프로세스 생성은 Miri에서 동작하지 않는다.
일반적으로 이는, 테스트 중 일부만 Miri에서 실행할 수 있고 나머지는 #[cfg_attr(miri, ignore)]로 제외해야 한다는 뜻이다.
이 제한에는 쉬운 해결책이 없다. Miri의 이점을 얻으려면 unsafe 블록을 포함하는 로직이 Miri가 에뮬레이트하지 않는 OS API와 통신하는 로직과 완전히 분리되도록 API를 설계해야 한다.
사이드퀘스트를 마치고 데이터 레이스 탐지를 위해 Miri를 쓰는 법을 배웠으니, 원자 변수의 두 번째 중요한 성질인 메모리 순서 제약을 정의하는 능력으로 돌아가 보자.
원자 변수의 원자성 성질은 하나의 변수만 다루면 충분하다. 다음 예제에서는 별도의 변수 두 개: 배열과 그 배열을 가리키는 포인터가 등장한다. 이 예제를 올바르게 동기화하려면 메모리 순서 제약이 필요하다.
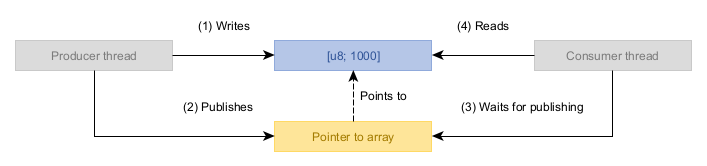
이 예제의 로직은 비교적 단순하다. 두 스레드 Producer와 Consumer가 있고, Producer가 데이터를 Consumer에게 전달한다. 작업은 개념적으로 다음 연산으로 구성된다.
0x01을 쓴다. 즉 [1_u8; 1000]에 해당하는 것을 만든다.예시 목적상 많은 바이트를 다루기 위해 배열을 쓸 뿐이다. 이렇게 하면 원하는 효과가 더 높은 확률로 드러난다. 하지만 정확한 데이터 타입은 중요하지 않으며, 배열이 단순한 정수여도 로직은 동일하다.
이 코드를 작성해 보자.
코드는 이미 한 가지 실수를 피하고 있다. 게시되는 포인터를 AtomicPtr 타입의 원자 변수에 저장한다. 이유는 첫 번째 문제와 같다. 여러 스레드에서 동시에 접근되는 데이터는 원자 변수의 원자성 성질이 보장하는 정합성을 위해 원자 변수를 사용해야 한다. Producer만 쓰고 Consumer만 읽더라도 상관없다. 읽기 접근도 쓰기 접근만큼 중요하다. 동시 접근 데이터에서 원자 변수를 생략할 수 있는 경우는 모든 접근이 공유 참조를 통해서만 이뤄질 때뿐이다. 물론 Rust도 원자 변수를 생략하려 하면 최대한 막으려 한다(예: 같은 변수에 대해 &mut 배타 참조와 & 공유 참조를 동시에 만들게 허용하지 않는다).
여기서 포인터와 배열 내용의 차이를 짚는 것이 중요하다. 왜 배열 내부 데이터는 원자 변수가 필요 없을까(즉 왜 [AtomicU8; 1000]이 아닐까)?
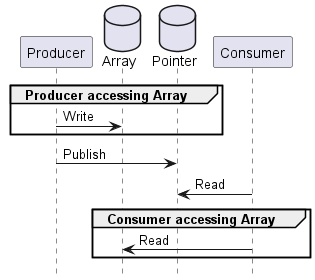
배열 내용도 두 스레드가 접근하긴 하지만 동시에 접근하지는 않기 때문이다. Producer는 배열을 게시하기 전에만 내용을 접근하고, Consumer는 게시된 배열을 받은 후에만 내용을 접근한다. 개념적 연산 순서상 Producer와 Consumer가 배열을 동시에 접근하는 시간적 겹침이 없으므로, 이 데이터에 원자 변수를 쓸 필요가 없다.
예제에서는 이 검증 로직을 많은 반복으로 수행해, 매우 낮은 확률의 이상 현상도 잡아내려 한다. 앞서 말한 “10,000대 중 1대가 하루에 크래시”는, 각 시스템이 수만 개 동시 세션을 처리한다는 점을 감안하면 매우 낮은 발생 빈도다. 예제에서는 0.0001% 확률의 결함도 탐지할 수 있을 만큼 확실히 하고 싶다. 멀티스레드 로직은 큰 결과를 낳는 미묘한 오류를 만들 수 있어 극단적 철저함이 요구된다. 물론 현실의 테스트 코드에서 보통 이렇게까지 하지는 않지만, 특정 조건에서는(특히 Miri와 결합할 때) 여전히 유용한 기법이 될 수 있다.
로직을 다시 보자. 한 스레드에서는 배열을 만들고 게시한다. 다른 스레드에서는 게시되기를 기다린 뒤 소비한다. 그럴듯해 보인다. x64 시스템에서 실행해 보자.
cargo run --example 03_array_passing --release --quiet
This may take a few minutes. Please wait...
No anomalies observed after 250000 iterations.
동작한다! 매우 직관적인 로직이 실패하는 걸 보지 않아도 돼서 다행이다.
그럼 ARM 시스템에서도 해 보자. 마침 하나 있다.
cargo run --example 03_array_passing --release --quiet
This may take a few minutes. Please wait...
Observed anomalous sum: 1000 x 1 == 936
Anomaly was detected on iteration 1879/250000.
이런, 맙소사!
프로그램이 유효(valid)하다는 것은 프로그래밍 언어의 규칙을 만족한다는 뜻이다. 이 규칙은 하드웨어가 강제하는 규칙과 다르다. 프로그래밍 언어는 서로 다른 규칙을 가진 여러 하드웨어 플랫폼을 지원하는 경향이 있기 때문이다.
따라서 무효한 프로그램도 다음 두 조건이 맞으면 “올바르게” 동작할 수 있다.
이것이 x64에서 성공한 이유다. 두 요인이 모두 우리 편이었다.
우리가 작성한 배열 공유 프로그램은 데이터 레이스라는 프로그래밍 오류를 포함하므로 무효한 Rust 코드다. 데이터 레이스는 정의되지 않은 동작이며, 컴파일러는 UB가 발생한 경우 무엇이든 할 수 있다. 멀쩡한 척할 수도 있고, 문제 코드를 삭제할 수도 있고, 크립토 마이너를 넣을 수도 있고, 우리 이름으로 대출을 받을 수도 있다. 우리는 운 좋게도 컴파일러가 코드를 완전히 망가뜨릴 변환을 적용하지 않았다.
x64 플랫폼은 멀티스레딩 규칙이 꽤 관대해서, 하드웨어 관점에서는 문제가 없었고 프로그램도 올바르게 동작했다. 프로그래머 관점에서는, 코드가 언어 관점에서 무효인데도 하드웨어가 기대대로 움직여 준 셈이다.
ARM 플랫폼은 훨씬 관대하지 않다. 무효 코드가 ARM에서 올바르게 동작할 확률은 더 낮다. 작성자가 테스트한 ARM 시스템에서는 대략 0.002% 정도로 실패하지만, 이는 하드웨어와 실행 코드에 크게 의존한다.
실수에 대한 허용치가 낮기 때문에, 저수준 멀티스레딩 로직을 ARM 프로세서에서 테스트하는 것은 가치가 있다.
어쨌든 Miri는 언어 규칙에 대해 동작을 검증하므로 하드웨어와 무관하게 데이터 레이스를 즉시·일관되게 탐지한다.
MIRIFLAGS=” -Zmiri-ignore-leaks”
cargo +nightly miri run --example 03_array_passing
error: Undefined Behavior: Data race detected between (1) retag write on thread `unnamed-2` and (2) retag read of type `[u8; 1000]` on thread `unnamed-1` at alloc3323
--> examples\03_array_passing.rs:52:53
|
52 | let array: &[u8; ARRAY_SIZE] = unsafe { &*ptr };
| ^^^^^ (2) just happened here
|
help: and (1) occurred earlier here
--> examples\03_array_passing.rs:38:33
|
38 | ARRAY_PTR.store(Box::into_raw(data), Ordering::Relaxed);
| ^^^^^^^^^^^^^^^^^^^
= help: retags occur on all (re)borrows and as well as when references are copied or moved
= help: retags permit optimizations that insert speculative reads or writes
= help: therefore from the perspective of data races, a retag has the same implications as a read or write
= help: this indicates a bug in the program: it performed an invalid operation, and caused Undefined Behavior
= help: see https://doc.rust-lang.org/nightly/reference/behavior-considered-undefined.html for further information
= note: this is on thread `unnamed-1`
note: the current function got called indirectly due to this code
--> examples\03_array_passing.rs:25:24
|
25 | let consumer = thread::spawn(|| {
| ________________________^
26 | | // We start Producer here, to ensure that Consumer starts first.
27 | | // This increases the probability of seeing the desired effects.
28 | | let _producer = thread::spawn(|| {
... |
66 | | });
| |__________^
여기서는 MIRIFLAGS 환경 변수로 Miri의 메모리 누수 탐지기를 명시적으로 꺼야 한다. 각 반복이 고유한 메모리 주소를 갖도록 예제가 의도적으로 메모리를 누수시키기 때문인데, 이는 이슈를 재현하기 쉬운 현실적인 메모리 접근 패턴이다.
ARM 하드웨어에서 예제가 실패한다는 사실은 분명하지만, 왜 그런지는 덜 명확하다. Miri의 오류 메시지는 대개 조사 시작점일 뿐 전체 그림을 드러내지는 않는다. 관련 요인을 살펴보자.
우리는 흔히 코드 실행을 선형 과정으로 생각한다. 예를 들어 Producer 스레드의 배열 게시를 다음처럼 사고한다.
0x01 바이트로 채운다.이는 어떤 의미에서는 참이지만, 특정 의미에서만 그렇다. 스레드 로컬하게만, 그리고 추상적으로만 그렇다.
이것이 앞서 예제 설명에서 다음과 같은 표현을 쓴 이유다.
개념적 연산 순서(conceptual sequence of operations) 에서는 Producer와 Consumer가 배열을 동시에 접근하는 시간이 겹치지 않는다 [..].
이는 우리가 원하던 바다. 하지만 우리가 작성한 코드는 사실 다른 연산 순서를 정의한다! 프로그래밍 언어는 하드웨어에서 일어나는 일을 매우 단순화해 보여준다. 추상화 계층을 뚫고 내려가면, 이 환상을 깨뜨리는 요소가 많다.
첫째, 컴파일러가 코드를 어떻게 보는지 고려해야 한다. 컴파일러는 더 최적이라고 판단하면 연산 순서를 재배치할 수 있다. 연산 간 의존성이 위배되지 않는 한, 최종 결과가 같다고 판단하면 합법이다. 우리의 배열 게시 코드에서 의존성은 무엇일까? 아래에서 위로 살펴보면:
0x01로 채워진다. 당연히 채우기 전에 배열은 생성되어야 한다.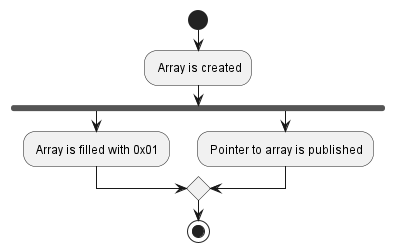
그런데 0x01로 채우는 것과 포인터를 게시하는 것 사이 관계는 어떨까? 코드가 이 둘 사이 관계를 정의하지 않는다. 컴파일러 관점에서 “배열 채우기”와 “포인터 게시”는 독립이다. 컴파일러가 포인터를 게시한 후에 배열을 0x01로 채우기로 결정해도 전혀 합법이다! 우리가 “채우기” 코드를 “포인터 게시” 코드보다 앞에 썼다는 사실만으로는 두 연산 간 의존성이 성립하지 않는다.
이 예제의 컴파일된 머신 코드를 조금 살펴보면, 운 좋게도 컴파일러가 재배치를 하지 않았다. 이는 작성 시점의 이야기이며 컴파일러 버전에 따라 바뀔 수 있다. 이런 행운은 x64에서 코드가 동작하는 이유 중 하나다. 미래의 컴파일러가 여기서 재배치를 한다면 x64에서도 깨질 수 있다. 이는 올바른 멀티스레드 코드에서는 X가 Y보다 먼저 일어나길 원할 때, 때로는 연산 사이 의존성을 명시해야 함을 시사한다. 다음 장에서 방법을 다룬다.
여기까지는 컴파일러 이야기였다. 컴파일러가 아무 것도 재배치하지 않더라도, 하드웨어가 코드를 실행할 때 무엇을 하는지도 고려해야 한다. 하드웨어의 동작은 전혀 선형이 아니다. 현대 CPU는 많은 연산을 동시에 수행하며, 아직 결정되지 않은 미래 분기까지 추측 실행한다.
원칙은 동일하다. 하드웨어는 해당 아키텍처 규칙 셋에서 최종 결과가 같다면 그렇게 할 수 있다. 하드웨어는 0x01 채우기와 포인터 게시 사이에 의존성이 있다고 볼까?
하드웨어에서 고려해야 할 관계/의존성은 여러 종류가 있지만, 크게 단순화하면:
0x01로 채우기”와 “포인터 게시” 사이에 의존성이 있다0x01로 채우기”와 “포인터 게시”가 독립이다그 결과 ARM에서는, Producer 스레드가 포인터를 게시하기 전에 배열을 0x01로 채웠더라도 Consumer 스레드가 배열이 0x01로 채워지기 전에 게시된 포인터를 관측하는 일이 가끔 발생할 수 있다.
결국 “왜 일어나는가”의 상세 메커니즘은 크게 중요하지 않다. 하드웨어 아키텍처 규칙이 그것을 허용하며, 하드웨어 내부에서 그런 결과를 만드는 메커니즘은 여러 가지일 수 있다(예: 포인터 게시와 0x01 채우기가 서로 다른 실행 유닛에서 진짜 동시에 실행되거나, 0x01 채우기는 먼저 일어나지만 메모리 변경이 다른 프로세서로 즉시 전파되지 않을 수도 있다).
좋은 소식은, Rust 언어 규칙을 따르면 Rust가 타깃하는 모든 하드웨어 아키텍처와의 호환이 보장된다는 점이다. 우리는 Rust가 기대하는 것만 신경 쓰면 된다. 하드웨어 아키텍처 이야기는 Rust 언어 규칙이 왜 존재하는지 이해를 돕기 위한 것뿐이다.
컴파일러 재배치 방지와 Consumer가 올바른 순서를 보게 만드는 두 측면 모두를 고치려면, 컴파일러와 하드웨어에 “포인터 게시”와 “배열 채우기” 사이 의존성이 존재함을 알려야 한다.
Producer 스레드의 0x01 쓰기와 Consumer 스레드의 배열 내용 읽기 사이에 데이터 레이스가 있음을 확인했다. 빠진 데이터 의존성을 추가해 이를 고치자. 그러면 코드는 유효한 Rust 코드가 되고, 하드웨어는 아키텍처와 무관하게 Rust가 기대하는 대로(그리고 우리가 기대하는 대로) 동작하게 된다.
데이터 의존성 정의에는 두 가지 변경이 필요하다.
첫째, 컴파일러에 “배열 포인터 게시”가 그 이전에 있던 모든 코드(즉 0x01 쓰기) 실행에 의존함을 알려야 한다. 이를 위해 Release 메모리 순서를 사용한다.
메모리 순서 모드의 이름은 상당히 혼란스럽다. 이름에 너무 많은 의미를 부여하지 말라. 수년 동안 다뤄온 작성자에게도 여전히 혼란스럽고 신호 대비 노이즈가 크다.
Release 순서는 “이 연산은 같은 스레드에서 그 이전에 있었던 모든 연산에 의존한다”를 의미한다.
컴파일러 관점에서는 Release만으로도 의존성이 설정되고 문제 되는 재배치가 방지되므로 충분한 경우가 많다.
하지만 이것만으로는 하드웨어 관점에서 데이터 의존성이 성립하지 않는다!
하드웨어 관점에서 Release는 실제로 쓰는 데이터에 붙는 메타데이터라고 생각하는 편이 유용하다. 쓰기 연산을 하드웨어가 수행하는 방식을 반드시 바꾸는 것이 아니라, 트랜잭션의 첫 단계만 설정한다.
루프를 닫아 트랜잭션을 완성하려면, 읽는 쪽에서 그 메타데이터 선언을 하드웨어가 존중하도록 지시해야 한다. 이를 위해 Acquire 메모리 순서를 쓴다. Acquire 순서는 “값이 Release로 쓰였으면, 그 값을 쓰기 전에 원래 스레드가 썼던 모든 것을 함께 보도록 보장하라”를 의미한다.
하드웨어가 이를 어떻게 구현하는지는 구현/아키텍처 정의에 달렸지만, Acquire를 “의존하는 모든 데이터가 도착할 때까지 기다려라”는 명령으로 생각해도 된다. 그렇다, 문자 그대로다. Acquire는 프로세서가 데이터가 도착할 때까지 코드 실행을 멈추게 만들 수도 있다!
이는 원자 변수가 느리다는 사실을 다시 상기시킨다. 동기화는 하드웨어 입장에서 시간과 노력이 들며 공짜가 아니다. 뮤텍스 같은 헤비급 프리미티브보다는 저렴하지만, 일반 메모리 접근과 비교하면 여전히 비용이 크다. 많은 프로세서를 가진 시스템에서 고확장성을 목표로 하는 코드는 원자 변수만 기반으로 하더라도 동기화 로직을 최소화해야 한다.
연산 간 의존성은 추론하기 어렵기 때문에, 이해를 돕기 위해 처음의 다이어그램에 실제로 1, 2, 3, 4 단계가 관련 참여자 관점에서 그 순서로 일어나도록 보장하는 의존 관계를 주석으로 달아 보자.

AtomicPtr 사용으로 보장된다. 포인터 자체는(고립된 상태에서) 여러 스레드가 올바르게 다룰 수 있으며, null이 아닌 값을 읽기 전에 null이 아닌 값이 저장되어 있어야 한다.쓰기에서 Release, 읽기에서 Acquire를 조합하면 데이터 의존성이 만들어지면서 데이터 레이스가 해결된다.
Release 쓰기는 Producer 스레드에서 의존성을 설정한다.Acquire 읽기는 그 의존성을 Consumer 스레드로 “전파”한다.이제 컴파일러와 하드웨어 모두 데이터 간 관계를 알게 되었고 각자 적절히 처리할 수 있다. ARM에서 다시 실행해 보자.
cargo run --example 04_array_passing_fixed --release --quiet
This may take a few minutes. Please wait...
No anomalies observed after 250000 iterations.
깔끔하게 통과한다! 수정 버전을 Miri로 돌려도 깨끗한 건강 진단을 받는다.
위 개념을 강화하기 위해, Arc 같은 참조 카운팅 스마트 포인터를 어떻게 구현할 수 있을지 보자. Arc는 값이 여러 클론에 의해 소유되며, 마지막 클론이 드롭될 때 값을 정리한다.
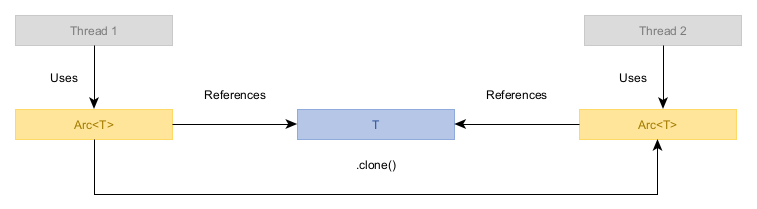
사용은 대략 다음과 같아야 한다(예시는 생략).
Arc의 단순 구현은 다음으로 구성된다.
Arc 클론이 공유하는, 타입 T의 소유 값.
이 공유 상태를 구조체로 만들고, 각각 이 구조체를 가리키는 복제 가능한 스마트 포인터를 만든다.
구현을 더 진행하기 전에, 앞서 다룬 내용을 바탕으로 설계를 분석해 보자.
원자 변수가 필요한가? 여러 스레드가 같은 변수를 동시에 접근하고 그중 하나라도 쓰기를 하면 원자 변수가 필요하다는 것을 기억하자.
소유 값 T는 동시 사용 관점에서 읽기 전용으로 볼 수 있다. 우리의 Arc는 T를 수정하지 않고, 변이를 허용하지 않는 공유 참조만 돌려주기 때문이다. 변이가 일어나는 경우(즉 T를 드롭하는 경우)에도 오직 마지막 Arc 클론만 T를 드롭할 수 있으므로, 드롭이 발생한다면 다른 스레드가 그 값에 접근하고 있을 수 없다.
따라서 T의 저장에는 원자 변수가 필요 없다. 이는 좋은 소식인데, 범용 Atomic<T> 타입은 없고 원자 변수는 원시 타입에 대해서만 존재하며, T는 무엇이든 될 수 있기 때문이다. 실제로 동기화 로직의 한 원칙은, 동시 쓰기 가능한 접근은 원시 타입에서만 가능하며 복잡한 타입에는 뮤텍스 같은 다른 접근이 필요하다는 것이다.
반면 참조 카운트는 모든 Arc 클론에 의해 수정되므로 원자 변수(예: AtomicUsize)여야 한다.
메모리 순서를 신경 써야 하는가? 멀티스레드 연산에 변수가 여러 개 얽히면 메모리 순서가 중요하다는 것을 기억하자.
이건 처음 보면 “멀티스레드 연산과 관련된 것은 참조 카운트뿐이고 T는 드롭될 때까지 읽기 전용이며 드롭은 단일 스레드 맥락에서 일어난다”라고 생각할 수 있다. 하지만 이 추론은 틀렸다.
오류는, Rust 객체가 공유 참조 &만 있어도 반드시 읽기 전용인 것은 아니라는 점이다! 객체를 변이시키는 데 &mut가 꼭 필요한 건 아니다. 타입 T는 내부 가변성을 가질 수 있다. Mutex<U>, 원자 변수 등 배타 참조 없이도 변이를 허용하는 필드를 가질 수 있다. “원자 변수가 필요한가” 판단에서는 이것이 중요하지 않았지만(T가 내부에서 처리), 데이터 의존성 관점에서는 중요하다.
즉 실제로는 두 개의 잠재적으로 변하는 변수가 있다: T와 참조 카운트.
하지만 여전히 원래 질문의 답은 아니다. 이 둘이 의존적인지 독립적인지 판단해야 한다. 컴파일러/하드웨어에 알려야 하는 데이터 의존성이 존재하는가? 각 값의 전체 생명주기를 고려해야 한다. 핵심은 마지막 Arc 클론이 참조 카운트를 0으로 감소시킨 후에 T 인스턴스를 드롭해야 한다는 점이다.
이 “후에(after)”가 우리가 찾는 의존성이다. 객체를 드롭하려면 그 객체 안의 데이터에 접근하는 드롭 로직이 실행되어야 하며, 그 드롭 로직이 다른 스레드에서 발생했던 변경이 모두 가시화된 ‘최종’ 버전의 T를 보도록 보장해야 한다(즉 다른 스레드가 Arc 클론을 드롭하기 전에 했던 모든 쓰기를 보게 해야 한다).
다르게 말하면 T의 드롭은 T 생명주기의 마지막 연산이어야 한다. 이렇게 말하면 당연하지만, 멀티스레드에서는 자동으로 성립하지 않는다.
이를 위해 Arc에서는 참조 카운트에서 T로의 데이터 의존성을 신호하는 메모리 순서 제약을 부과해야 한다.
Arc 클론이 드롭될 때, 참조 카운트 감소를 Release로 수행해 이 스레드에서 T에 대한 어떤 쓰기든 감소 연산이 다른 스레드에 보이기 전에 먼저 보이도록 신호한다.Arc 클론이 드롭될 때, 참조 카운트 감소를 Acquire로 수행해(만약 감소 결과가 0이 되어 T를 드롭해야 한다면) 다른 스레드들이 참조 카운트를 감소시키기 전에 일어난 모든 변경을 보도록 보장한다.그렇다. 같은 연산이 Release와 Acquire를 모두 가져야 한다. 이것이 표준 메모리 순서 제약 중 하나인 Ordering::AcqRel이다.
참조 카운트를 증가시키는 경우는 신경 쓰지 않아도 된다는 점에 유의하라. 증가 시에는 T를 드롭하는 것과 관련된 의존성이 없기 때문이다. 마지막 감소 이후 T가 드롭될 때만 데이터 의존성이 얽힌다. 따라서 증가 연산은 Relaxed를 사용할 수 있다. 서로 다른 스레드의 Arc 클론들은 T가 드롭되지 않는 한 T에 대한 쓰기를 신경 쓰지 않는다.
물론 타입 T 자체는 스레드 간 쓰기 동기화가 필요할 수 있지만, 그런 경우 T의 변이 로직이 스스로 필요한 메모리 순서 제약을 정의하면 된다.
cargo run --example 05_arc --release --quiet
Value: 42
Thread Two Value: 42
Thread Three Value: 42
cargo +nightly miri run --example 05_arc
Value: 42
Thread Two Value: 42
Thread Three Value: 42
동작한다. Miri도 불평하지 않는다. 기능하는 Arc를 만들었다!
앞 장에서 만든 Arc는 참조 카운트 감소를 항상 Acquire+Release로 수행하므로 최적이 아니다. 문제는 Acquire 부분이 참조 카운트가 0이 될 때만 필요하다는 점이다. 0이 아니면 T를 드롭하지 않으니 다른 스레드의 쓰기를 모두 볼 필요가 없다.
Acquire 메모리 순서는 하드웨어에 “멈추고 데이터를 기다려라”는 명령이 될 수 있음을 기억하라. 우리는 매 감소마다 비용을 치르고 있을지도 모른다!
해결책이 있다.
Release만으로 수행한다.Acquire 펜스(fence) 를 둔다.T를 드롭한다.펜스는 이전의 원자 변수 연산을 “강화(strengthen)”하는 데 쓰이는 동기화 프리미티브로, Acquire 비용을 필요할 때만 치르게 해 준다. 이는 마치 이전의 원자 연산(참조 카운트 감소)에 메모리 순서를 적어둔 것과 같은 효과를 내지만, 그 효과를 더 나중 시점/코드에서 조건부로 적용할 수 있게 한다.
이 코드는 기능적으로 동일하지만 더 효율적이다. 효과의 크기는 하드웨어 아키텍처에 따라 달라지며, 일부 아키텍처에서는 0일 수도 있다.
이 글의 예제들은 컴파일러의 가드레일을 낮춰 위험한 일을 하기 위해 unsafe를 사용했다. 예제를 짧고 요점 있게 하느라 죄를 하나 지었는데, unsafe 블록에 대한 안전 주석(safety comment)을 제공하지 않았다.
안전 주석은 유지보수 가능한 unsafe Rust 코드를 쓰는 데 필수다. 이는 도전-응답(challenge-response) 쌍의 절반이다.
unsafe fn의 API 문서는 호출자가 지켜야 하는 안전 요구사항(safety requirements) 을 정의한다. 이것이 도전이다.안전 주석을 작성하는 과정에서 “사실 요구사항을 만족하지 못하고 있네?”라는 깨달음이 생기며 오류가 발견되는 경우가 흔하다. 작성 후에도 안전 주석은 리뷰어와 미래 유지보수자에게(그리고 unsafe Rust에 쉽게 혼란스러워하는 AI 에이전트에게도) 매우 귀중하다.
안전 주석은 모든 unsafe Rust 코드에서 필수로 여겨야 한다. 모든 unsafe 함수 호출에는 안전 요구사항을 어떻게 충족하는지 설명하는 안전 주석이 동반되어야 한다. 안전 주석 없는 unsafe 코드는 리뷰 불가능하고 유지보수 불가능하다. unsafe Rust에서는 안전 주석이 소스 코드의 상당 부분을 차지하는 것이 정상이며 기대되는 바다.
다만 AI가 생성한 안전 주석은 극도로 조심하라. 흔히 “SAFETY: 다 괜찮음, 유효함, 나를 믿어 bro” 스타일이고, 호출하는 함수의 안전 요구사항을 어떻게 충족하는지 제대로 설명하지 못한다. AI가 호출된 함수의 안전 요구사항을 읽으려 시도조차 하지 않는 경우가 많아, 주석이 완전히 동문서답인 손 흔들기(hand-waving)일 수 있다.
안전 주석과 비슷하게, 원자 연산에는 지정한 메모리 순서 제약이 왜 올바른지 설명하는 주석을 함께 달아두는 것이 좋은 관행이다.
메모리 순서 제약 로직은 역공학하고 수동으로 검증하기가 매우 어렵다. 미래 유지보수자의 정신 건강과 미래 AI 수정의 성공을 위해, 원자 변수의 모든 연산에 주석을 남겨라.
프로덕션급 Arc 구현이라면, 다음과 같은 상세한 안전/동기화 로직 주석을 기대할 수 있다(예시는 생략).