Kubernetes에서 PostgreSQL을 배포할 때 견고한 비즈니스 연속성(HA/DR) 전략을 구현하기 위한 핵심 아키텍처 고려사항을 개관합니다.
URL: https://cloudnative-pg.io/docs/1.28/architecture
Title: Architecture | CloudNativePG
이 문서 페이지는 Kubernetes에서 PostgreSQL을 배포할 때 견고한 비즈니스 연속성 전략을 구현하기 위한 핵심 아키텍처 고려사항을 개관합니다. 이러한 고려사항에는 다음이 포함됩니다.
postgres 워커 노드 예약(Reservation): 특정 워커 노드를 postgres 작업에 전용으로 할당해 PostgreSQL 워크로드를 격리함으로써 최적의 성능을 보장하고 다른 워크로드로부터의 간섭을 최소화합니다.PostgreSQL은 데이터베이스 관리 시스템이므로 Kubernetes에서 상태 기반(stateful) 워크로드로 취급되어야 합니다. 무상태 애플리케이션은 주로 트래픽 리다이렉션을 통해 고가용성(HA)과 재해 복구(DR)를 달성하지만, 데이터베이스의 경우 상태를 여러 위치에 복제해야 하며, 가능하면 연속적이고 즉각적인 방식으로 다음 두 전략 중 하나를 채택해야 합니다.
CloudNativePG는 간단한 이유로 애플리케이션 레벨 복제에 의존합니다. PostgreSQL DBMS는 Write Ahead Log(WAL) 배송(shipping) 기반의 견고하고 신뢰할 수 있는 내장 물리적 복제(physical replication) 기능을 제공하며, 전 세계 수백만 사용자가 10년 이상 프로덕션에서 사용해 왔기 때문입니다.
PostgreSQL은 네트워크를 통한 비동기/동기 스트리밍 복제뿐 아니라 비동기 파일 기반 로그 배송(일반적으로 폴백 옵션으로 사용됨, 예: 오브젝트 스토어에 WAL 파일 저장)을 모두 지원합니다. 복제본은 보통 _스탠바이 서버(standby server)_라고 부르며, Hot Standby 기능 덕분에 읽기 전용 워크로드에도 사용할 수 있습니다.
Kubernetes는 기본적으로 서로 이중화된 저지연 프라이빗 네트워크로 연결된 분리된 물리적 위치(데이터 센터, 장애 영역, 또는 더 흔히 가용 영역(availability zone))에 걸쳐 클러스터를 구성할 수 있게 해줍니다.
분산 시스템인 Kubernetes 클러스터의 권장 최소 가용 영역 수는 3개(3)이며, 이를 통해 단일 영역 장애에도 컨트롤 플레인이 복원력을 가질 수 있습니다. 자세한 내용은 "Running in multiple zones"를 참고하세요. 이는 각 데이터 센터가 항상 활성(active) 상태이며 동시에 워크로드를 실행할 수 있음을 의미합니다.
note
대부분의 퍼블릭 클라우드 제공자의 관리형 Kubernetes 서비스는 각 리전에서 이미 3개 이상의 가용 영역을 제공합니다.
3개(3) 이상의 영역을 갖는 다중 가용 영역 Kubernetes 아키텍처는 PostgreSQL 사용을 위해 우리가 권장하는 구성입니다. 이 시나리오는 클라우드 제공자가 관리하는 Kubernetes 서비스에서 일반적입니다.
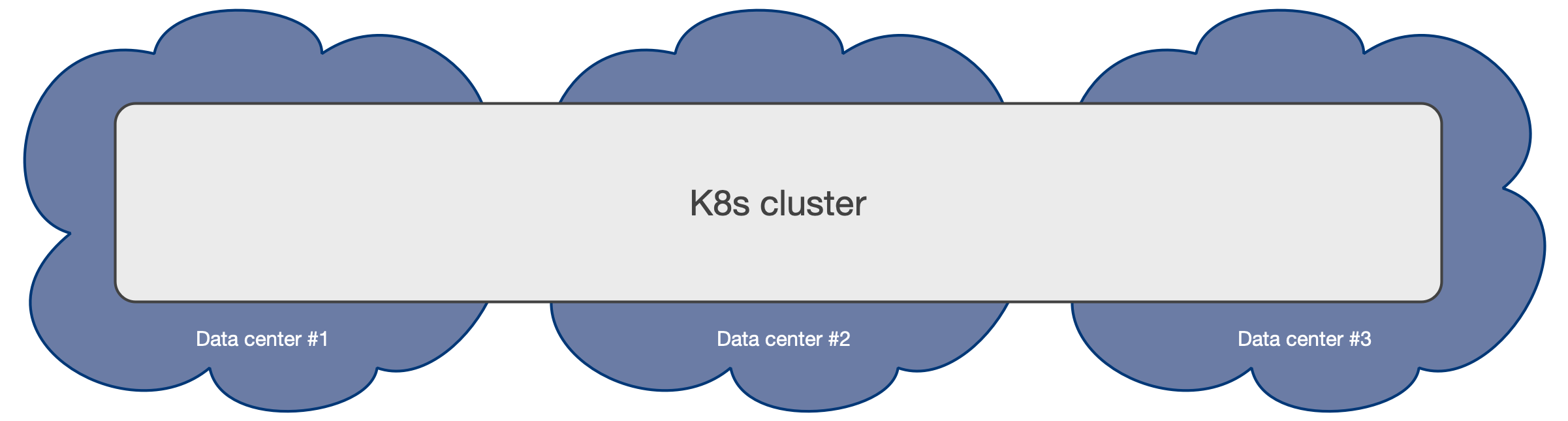
이러한 아키텍처는 CloudNativePG 오퍼레이터가 단일 Kubernetes 클러스터 내에서 모든 가용 영역을 활성으로 취급하면서, 영역 전반에 걸쳐 Cluster 리소스의 전체 라이프사이클을 제어할 수 있게 합니다. 여기에는 (그 외 다양한 작업을 포함해) 친화성 규칙, 톨러레이션, 노드 셀렉터에 기반한 선언적 스케줄링, 자동 페일오버, 자가 치유, 업데이트 등이 포함됩니다. 모든 기능은 단일 Kubernetes 클러스터 내에서 영역을 가로질러 매끄럽게 동작합니다.
동일 Kubernetes 클러스터 내에서 스토리지, 워커 노드, 가용 영역 수준의 shared-nothing 배포를 통해 PostgreSQL 클러스터를 어떻게 설계할 수 있는지에 대해서는 아래의 "PostgreSQL 아키텍처" 섹션을 참고하세요.
추가로, 선언적 구성을 통해 서로 다른 리전에 "패시브" PostgreSQL 레플리카 클러스터를 호스팅하는 분산 PostgreSQL 토폴로지를 배포하고 관리하기 위해 Kubernetes 클러스터를 활용할 수 있습니다. 이 구성은 재해 복구(DR), 읽기 전용 작업, 또는 리전 간 가용성에 이상적입니다.
Important
각 오퍼레이터 배포는 로컬 Kubernetes 클러스터 내부의 작업만 관리할 수 있습니다. 제어된 스위치오버 또는 예기치 않은 페일오버와 같은 Kubernetes 클러스터 간 작업은 수동으로(예: GitOps) 조율하거나 상위 수준의 클러스터 관리 도구를 사용해 조율해야 합니다.
Kubernetes 클러스터가 단 하나의 가용 영역만 가지고 있더라도, CloudNativePG는 PostgreSQL 데이터베이스의 HA 및 DR 결과를 개선할 수 있는 다양한 기능을 제공합니다. 가능한 한 단일 장애 지점(SPoF)을 가용 영역 수준으로 끌어올리는 것이 목표입니다. 즉, CloudNativePG 클러스터에 장애가 발생하기 전에 먼저 해당 영역에서 장애(아웃티지)가 발생해야 하도록 만드는 것입니다.
이 시나리오는 하나의 데이터 센터만 이용 가능한 자체 운영(on-premise) Kubernetes 클러스터에서 일반적입니다.
단일 가용 영역 Kubernetes 클러스터는, 저지연 연결이 가능한 범위 내에 두 개의 데이터 센터만 있는 경우 유일하게 실현 가능한 옵션입니다(보통 같은 대도시권). 영역이 2개뿐이면 최소 3개 영역이 필요한 다중 가용 영역 Kubernetes 클러스터를 만들 수 없습니다. 그 결과 사용자는 액티브/패시브 구성으로 두 개의 별도 Kubernetes 클러스터를 만들어야 하며, 두 번째 클러스터는 주로 재해 복구용으로 사용됩니다(레플리카 클러스터 기능 참조).
Hint
Kubernetes 여정 초기 단계라면 이 문서를 인프라 팀과 공유하세요. 두 데이터 센터 구성은 전통적인 베어메탈 또는 VM 기반 인프라에서 Kubernetes로 “리프트 앤 시프트” 전환한 결과일 수 있으며, 인프라 아키텍처가 설계될 당시 3개 이상 영역 시나리오에서 Kubernetes가 제공하는 이점이 알려지지 않았거나 반영되지 않았을 수 있습니다. 궁극적으로 다른 두 곳과 연결된 세 번째 물리적 위치는 조직이 고려할 만한 유효한 옵션이 될 수 있으며, 애플리케이션 레벨의 일상적 복잡성을 물리 인프라 레벨로 내려 전체 인프라 비용을 절감할 수 있습니다.
단일 가용 영역 Kubernetes 클러스터 내에서 스토리지 및 워커 노드 수준에서만 shared-nothing 배포를 통해 PostgreSQL 클러스터를 어떻게 설계할 수 있는지에 대해서는 아래의 "PostgreSQL 아키텍처" 섹션을 참고하세요. 이 시나리오에서 HA를 위해서는 PostgreSQL 인스턴스가 서로 다른 워커 노드에 위치하고 동일 스토리지를 공유하지 않는 것이 더욱 중요합니다.
DR의 경우, 추가 Kubernetes 클러스터를 사용해 “패시브” PostgreSQL 레플리카 클러스터를 호스팅하는 분산 토폴로지를 정의함으로써 SPoF를 단일 영역 위로 끌어올릴 수 있습니다. 이 시나리오의 다른 Kubernetes 워크로드와 마찬가지로, 어떤 Kubernetes 클러스터를 프라이머리로 승격할지 결정(프로모션)은 수동으로 해야 합니다.
레플리카 클러스터 기능을 통해 분산 PostgreSQL 토폴로지를 정의하고, 먼저 프라이머리 클러스터를 강등(demote)한 다음 레플리카 클러스터를 승격(promote)하여 데이터 센터 간 제어된 스위치오버를 조율할 수 있으며, 이전 프라이머리를 재클론(re-clone)할 필요가 없습니다. 페일오버는 이제 완전히 선언적이지만, Kubernetes 클러스터 간 자동 페일오버는 CloudNativePG 범위 밖입니다. 오퍼레이터는 단일 Kubernetes 클러스터 내에서만 동작할 수 있기 때문입니다.
Important
CloudNativePG는 상위 수준의 오퍼레이터 또는 관리 도구를 통해 서로 다른 Kubernetes 클러스터 간 PostgreSQL 액티브/패시브 토폴로지를 조율하는 데 필요한 모든 프리미티브와 프로브를 제공합니다.
다중 가용 영역 환경이든(혹은 더 중요하게는) 단일 가용 영역이든, 프로덕션에서는 PostgreSQL 워크로드를 postgres 전용 워커 노드에 배치하여 격리할 것을 강력히 권장합니다. PostgreSQL 워크로드 실행에 전용으로 할당된 Kubernetes 워커 노드를 Postgres 노드 또는 postgres 노드라고 합니다. 이 접근은 데이터베이스 작업을 위한 최적의 성능과 리소스 할당을 보장합니다.
Hint
일반적인 경험칙으로, Postgres 노드는 3의 배수로 배치하세요—이상적으로는 가용 영역당 1개 노드입니다. 3개 노드는 (프라이머리 1개와 스탠바이 레플리카 2개로 구성된) 3인스턴스 PostgreSQL 클러스터가 서로 다른 노드에 분산되도록 해 장애 허용성과 가용성을 높이기 때문에 최적의 숫자입니다.
Kubernetes에서는 IaC(Infrastructure as Code) 관행에 맞춰, 노드 레이블과 테인트(taint)를 선언적으로 사용해 이를 달성할 수 있습니다. 레이블은 노드가 postgres 워크로드를 실행할 수 있음을 보장하고, 테인트는 postgres가 아닌 워크로드가 해당 노드에 스케줄링되는 것을 방지하는 데 도움이 됩니다.
Important
이 방법론은 컴퓨팅 리소스 측면뿐 아니라(로컬 연결 디스크를 사용할 경우) 스토리지 측면에서도 PostgreSQL 워크로드를 다른 워크로드로부터 격리하는 가장 간단한 방법입니다. 서로 다른 PostgreSQL 클러스터가 같은 노드를 공유할 수도 있지만, 레이블과 테인트를 사용해 특정 Cluster의 단일 인스턴스에 노드를 전용으로 할당하도록 한 단계 더 강화할 수 있습니다.
CloudNativePG는 node-role.kubernetes.io/postgres 레이블 사용을 권장합니다. 이는 예약된 레이블(*.kubernetes.io)이므로 워커 노드가 생성된 이후에만 적용할 수 있습니다.
노드에 postgres 레이블을 할당하려면 다음 명령을 사용하세요.
kubectl label node <NODE-NAME> node-role.kubernetes.io/postgres=
Cluster 리소스가 postgres 노드에 스케줄링되도록 하려면, 매니페스트에서 .spec.affinity.nodeSelector 구성을 올바르게 설정해야 합니다. 예시는 다음과 같습니다.
spec: # <snip> affinity: # <snip> nodeSelector: node-role.kubernetes.io/postgres: ""
CloudNativePG는 node-role.kubernetes.io/postgres 테인트 사용을 권장합니다.
노드에 postgres 테인트를 할당하려면 다음 명령을 사용하세요.
kubectl taint node <NODE-NAME> node-role.kubernetes.io/postgres=:NoSchedule
Cluster 리소스가 postgres 테인트가 있는 노드에 스케줄링되도록 하려면, 매니페스트에서 .spec.affinity.tolerations 구성을 올바르게 설정해야 합니다. 예시는 다음과 같습니다.
spec: # <snip> affinity: # <snip> tolerations: - key: node-role.kubernetes.io/postgres operator: Exists effect: NoSchedule
CloudNativePG는 동일 Kubernetes 클러스터 내에서 여러 핫 스탠바이 레플리카를 관리하기 위해 비동기/동기 스트리밍 복제 기반 클러스터를 지원하며, 사양은 다음과 같습니다.
HA를 위한 옵션의 다수 핫 스탠바이 레플리카를 포함할 수 있는 단일 프라이머리
애플리케이션을 위한 사용 가능한 서비스:
-rw: 애플리케이션은 클러스터의 프라이머리 인스턴스에만 연결-ro: 애플리케이션은 읽기 전용 워크로드를 위해 핫 스탠바이 레플리카에만 연결(선택)-r: 애플리케이션은 읽기 전용 워크로드를 위해 어떤 인스턴스에도 연결(선택)PostgreSQL 클러스터의 복원력을 높이기 위해 권장되는 shared-nothing 아키텍처:
Important
위 서비스는 Cluster 구성의 managed.services 섹션을 통해 설정할 수 있습니다. 서비스 수를 줄이거나 유형(기본값은 ClusterIP)을 선택하여 구성할 수 있습니다. 자세한 내용은 아래의 "서비스 관리(Service Management)" 섹션을 참고하세요.
아래 다이어그램은 3개의 서로 다른 가용 영역에 걸쳐, 각기 별도의 노드에서 실행되며 PostgreSQL 데이터용 전용 로컬 스토리지를 갖는 PostgreSQL 클러스터에 대해 권장되는 shared-nothing 아키텍처를 단순화해 보여줍니다.
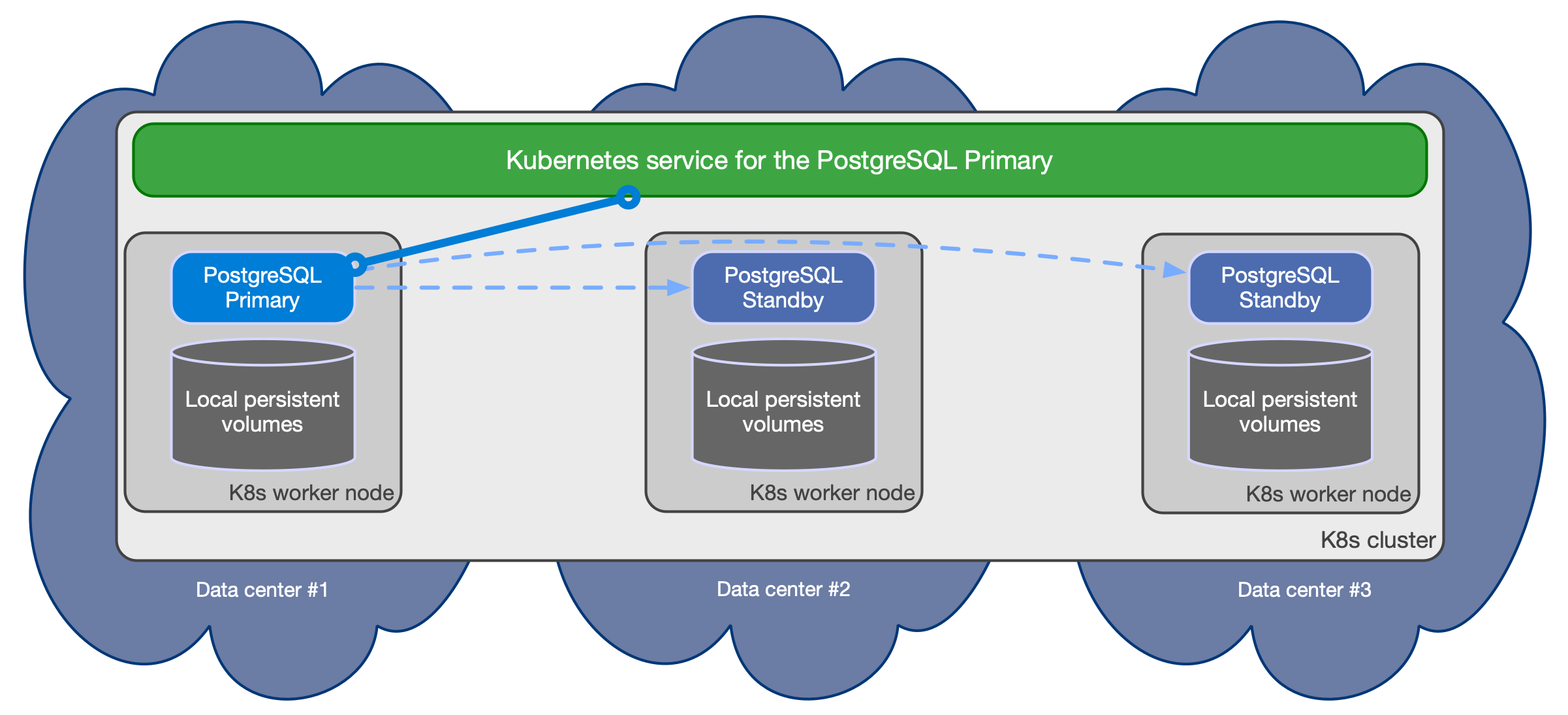
CloudNativePG는 클러스터의 토폴로지가 변경되면 위 서비스들을 자동으로 업데이트합니다. 예를 들어 페일오버가 발생하면, 승격된 프라이머리를 가리키도록 -rw 서비스를 자동으로 업데이트하여 애플리케이션 트래픽이 매끄럽게 리다이렉트되도록 보장합니다.
Replication
동기 설정을 포함해 CloudNativePG가 PostgreSQL 복제에 어떻게 의존하는지에 대한 자세한 내용은 "Replication" 섹션을 참고하세요.
애플리케이션에서 연결하기
동일 Kubernetes 클러스터 내 무상태 애플리케이션에서 CloudNativePG에 연결하는 방법은 "Connecting from an application" 섹션을 참고하세요.
커넥션 풀링(Connection Pooling)
PgBouncer를 커넥션 풀러로 활용하고 애플리케이션과 PostgreSQL 클러스터 사이에 액세스 레이어를 만드는 방법은 "Connection Pooling" 섹션을 참고하세요.
애플리케이션은 다음 다이어그램에서 보듯, Kubernetes 오퍼레이터에 의해 _현재 프라이머리(current primary)_로 선출된 PostgreSQL 인스턴스에 연결하도록 선택할 수 있습니다.
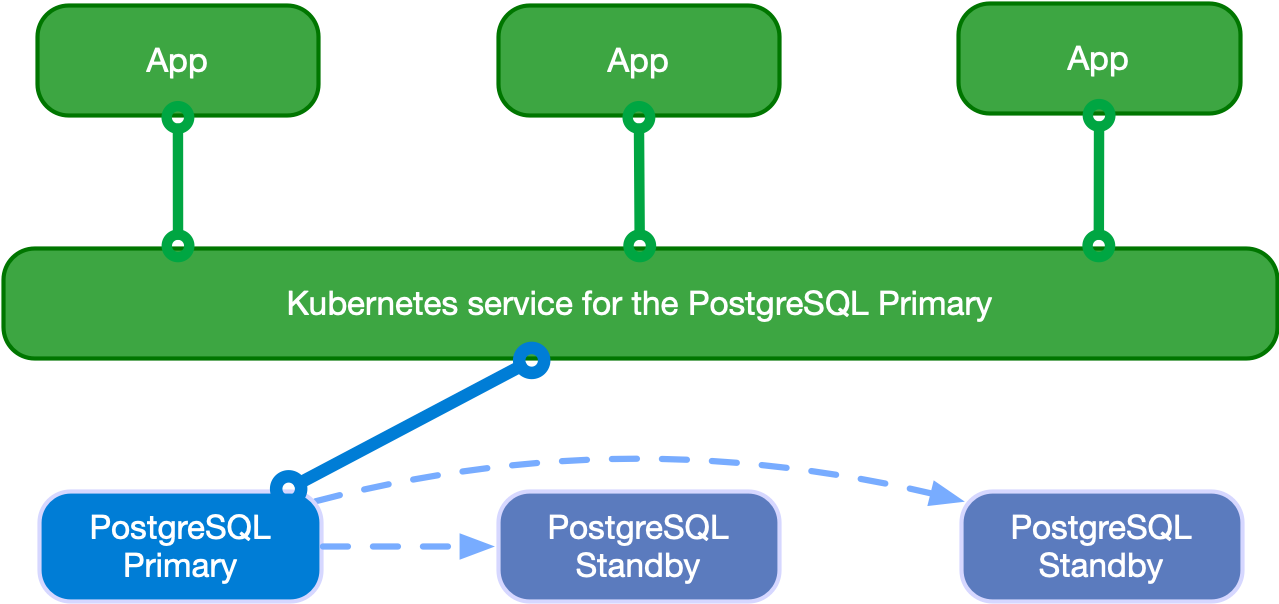
애플리케이션은 -rw 접미사 서비스를 사용할 수 있습니다.
프라이머리가 일시적 또는 영구적으로 사용할 수 없게 되는 경우, 고가용성을 위해 CloudNativePG가 페일오버를 트리거하며 -rw 서비스가 클러스터의 다른 인스턴스를 가리키도록 전환합니다.
Important
애플리케이션은 Hot Standby가 갖는 제약을 이해하고, 이러한 워크로드를 처리할 때 PostgreSQL이 동작하는 방식에 익숙해야 합니다.
애플리케이션은 오퍼레이터가 제공하는 -ro 서비스를 통해 핫 스탠바이 레플리카에 접근할 수 있습니다. 이 서비스는 애플리케이션이 읽기 전용 쿼리를 프라이머리 노드에서 오프로딩(offload)할 수 있게 합니다.
다음 다이어그램은 아키텍처를 보여줍니다.

애플리케이션은 -r 서비스를 통해 어떤 PostgreSQL 인스턴스에도 접근할 수 있습니다.
info
CloudNativePG는 이 섹션에서 설명하는 것처럼 레플리카 클러스터를 사용해 분산 PostgreSQL 토폴로지를 정의할 수 있는 기능을 통해, 여러 Kubernetes 클러스터에 걸친 PostgreSQL 배포를 지원합니다.
분산 PostgreSQL 클러스터에서는 언제나 단 하나의 PostgreSQL 인스턴스만 프라이머리로 동작할 수 있습니다. 이는 애플리케이션이 어느 시점이든 단 하나의 Kubernetes 클러스터 내에서만 쓰기 작업을 수행할 수 있음을 의미합니다.
하지만 비즈니스 연속성 목표를 위해 다음은 필수적입니다.
위 우려를 해결하기 위해 CloudNativePG는 서로 다른 Kubernetes 클러스터에 분산된 PostgreSQL 토폴로지 개념을 도입합니다. 이 토폴로지는 하나의 프라이머리 PostgreSQL 클러스터와 하나 이상의 PostgreSQL 레플리카 클러스터로 구성됩니다. 이 기능은 **레플리카 클러스터를 이용한 분산 PostgreSQL 토폴로지(distributed PostgreSQL topology with replica clusters)**라고 하며, 프라이빗/퍼블릭/하이브리드/멀티 클라우드 환경에서 멀티 클러스터 배포를 가능하게 합니다.
레플리카 클러스터는 별도의 Cluster 리소스로, 다른 소스로부터 지속적으로 복구(continuous recovery) 상태를 유지하며 복제합니다. 소스는 WAL 아카이브로부터의 WAL shipping일 수도 있고, 프라이머리 또는 스탠바이(캐스케이딩)로부터의 스트리밍 복제일 수도 있습니다.
아래 다이어그램은 두 개의 서로 다른 Kubernetes 클러스터에 걸친 PostgreSQL 클러스터를 보여줍니다. 첫 번째 Kubernetes 클러스터에 프라이머리 클러스터가 있고, 두 번째 Kubernetes 클러스터에 레플리카 클러스터가 있습니다. 두 번째 Kubernetes 클러스터는 회사의 재해 복구 클러스터로 동작하며, 첫 번째 클러스터가 재해로 인해 사용할 수 없게 될 경우 활성화할 준비가 되어 있습니다.
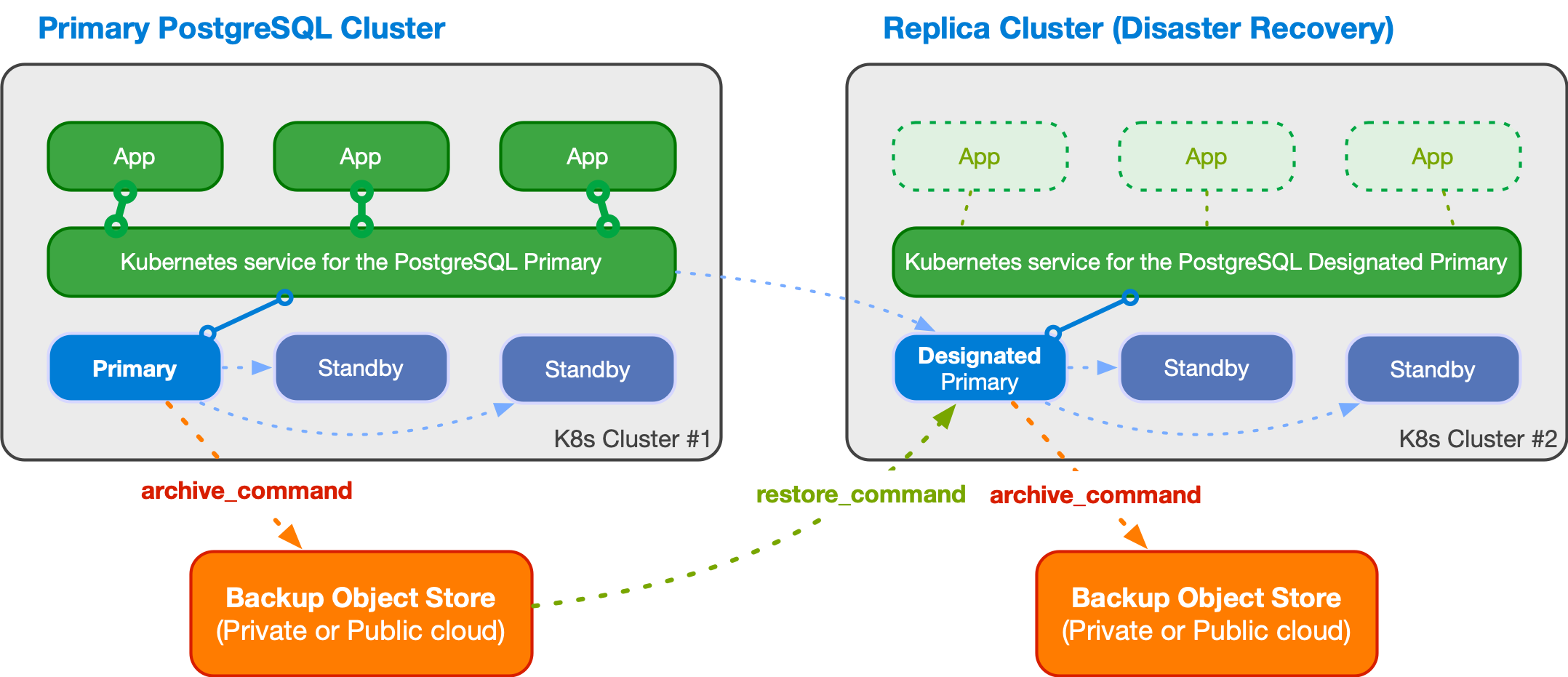
레플리카 클러스터는 프라이머리 클러스터와 동일한 아키텍처를 가질 수 있습니다. 레플리카 클러스터에는 프라이머리 인스턴스 대신 지정 프라이머리(designated primary) 인스턴스가 있으며, 이는 임의 개수의 캐스케이딩 스탠바이 서버와 함께 스트리밍 복제 중인 스탠바이 서버입니다(대칭 아키텍처).
지정 프라이머리는 언제든 승격(promote)될 수 있으며, 레플리카 클러스터를 쓰기 연결을 수용할 수 있는 프라이머리 클러스터로 변환합니다. 이는 보통 다음에 의해 트리거됩니다.
warning
CloudNativePG는 단일 Kubernetes 클러스터를 넘어서는 권한이 없기 때문에, 클러스터 간 자동 페일오버를 수행할 수 없습니다. 이러한 작업은 수동으로 수행하거나 멀티 클러스터/페더레이션을 인지하는 상위 권한에 위임해야 합니다.
Important
CloudNativePG는 선언적 구성을 통해 분산 토폴로지를 제어할 수 있게 해주며, GitOps를 포함한 IaC 프로세스의 일부로 이러한 절차를 자동화할 수 있습니다.
위 예시에서 지정 프라이머리는 스트리밍 복제(primary_conninfo)를 통해 WAL 업데이트를 수신합니다. 폴백으로는, restore_command 및 barman-cloud-wal-restore를 통해 Barman Cloud 플러그인을 사용하는 등 파일 기반 WAL shipping을 사용해 오브젝트 스토어에서 WAL 세그먼트를 가져올 수 있습니다.
CloudNativePG를 사용하면 여러 레플리카 클러스터를 포함하는 토폴로지를 정의할 수 있습니다. 또한 레플리카 수가 더 적은 레플리카 클러스터를 정의한 뒤, 클러스터가 프라이머리로 승격될 때 그 수를 늘릴 수도 있습니다.
레플리카 클러스터
물리적 레플리카 클러스터가 어떻게 동작하는지, 그리고 서로 다른 Kubernetes 클러스터에 걸쳐 읽기 전용 클러스터를 포함하는 분산 토폴로지를 어떻게 정의하는지에 대한 더 자세한 정보는 "Replica Clusters" 섹션을 참고하세요. 이 접근은 전역 재해 복구 및 고가용성(HA) 전략을 크게 강화할 수 있습니다.