FoundationDB의 논리적 구조와 주요 컴포넌트에 대해 설명합니다. 클러스터의 유연한 아키텍처, 트랜잭션 처리 과정, 주요 역할에 대한 상세한 정보를 제공합니다.
FoundationDB는 아키텍처를 유연하고 운영이 쉽도록 설계합니다. 애플리케이션은 데이터를 FoundationDB로 직접 전송하거나, 레이어라는 사용자 정의 모듈을 통해 전송할 수 있습니다. 이 레이어는 새로운 데이터 모델을 제공하거나 기존 시스템과의 호환성을 제공하거나, 심지어 전체 프레임워크로 동작할 수 있습니다. 두 경우 모두 모든 데이터는 정렬된 트랜잭션 키-값 API를 통해 단일 위치에 저장됩니다.
아래 다이어그램은 논리적 아키텍처를 보여줍니다.
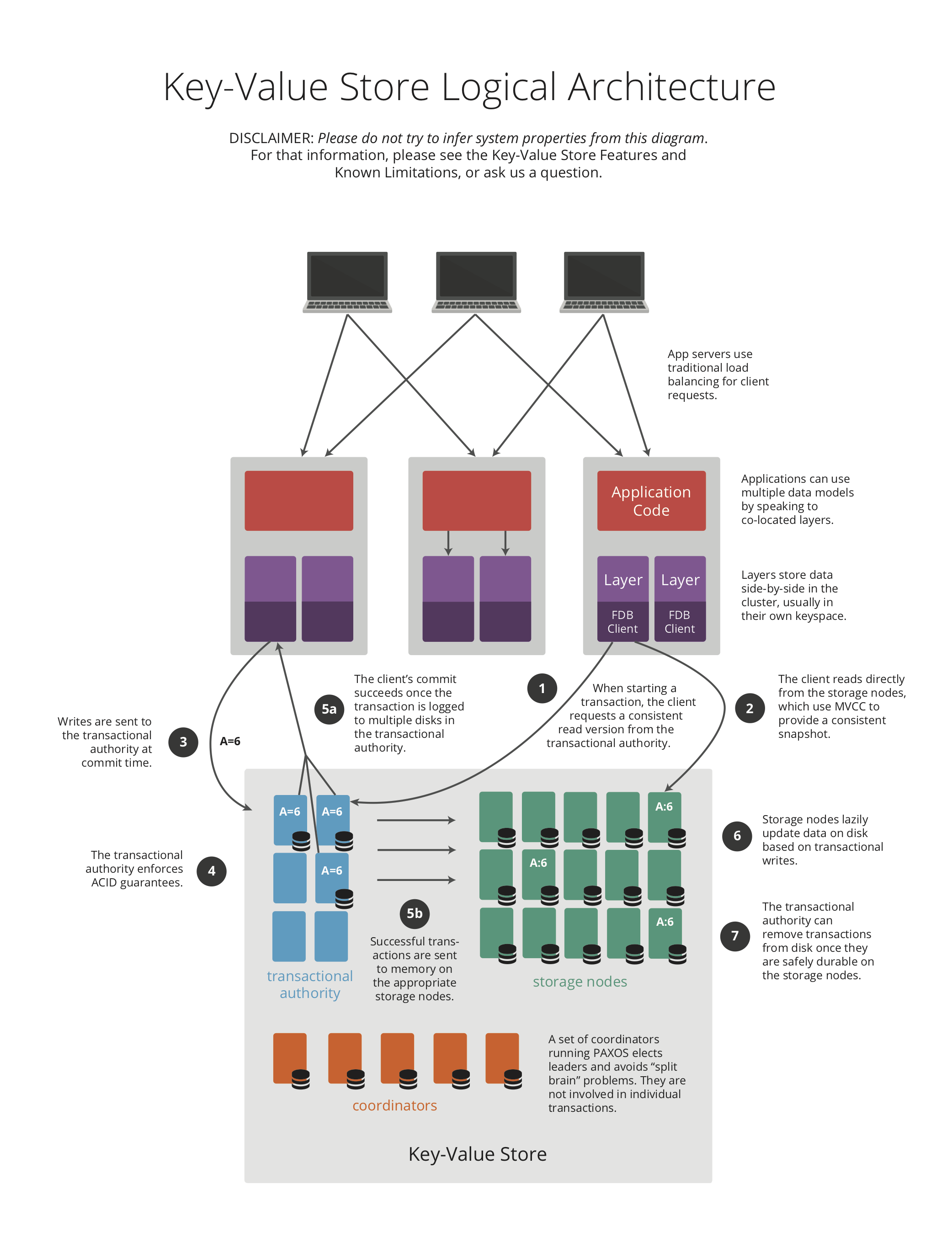
FoundationDB 아키텍처는 프로세스에 다양한 역할(Coordinators, Storage Servers, Master 등)을 할당하는 분리된 설계를 채택했습니다. 클러스터는 서로 다른 역할을 서로 다른 프로세스로 할당하려고 하지만, 클러스터 구성을 맞추기 위해 여러 Stateless 역할이 단일 프로세스에 공존(배정)될 수도 있습니다. 데이터베이스의 확장은 각 역할별 프로세스 수의 수평 확장으로 달성합니다.
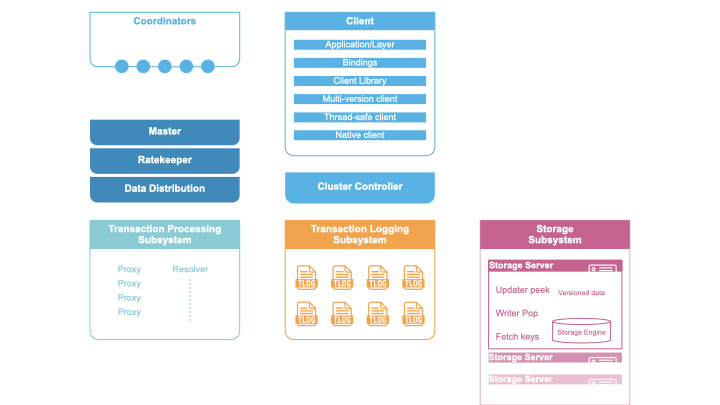
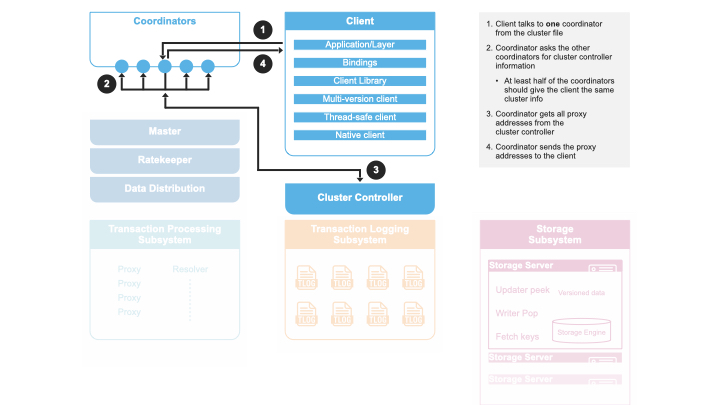
모든 클라이언트와 서버는 클러스터 파일을 통해 FoundationDB 클러스터에 연결합니다. 이 파일에는 코디네이터들의 IP:PORT가 저장되어 있습니다. 클라이언트와 서버는 모두 코디네이터를 이용해 클러스터 컨트롤러에 연결합니다. 서버는 클러스터 컨트롤러가 없는 경우 이를 맡으려고 시도하며, 선출되면 클러스터 컨트롤러에 등록합니다. 클라이언트는 클러스터 컨트롤러로부터 최신 GRV 프록시와 Commit 프록시 목록을 유지받습니다.
클러스터 컨트롤러는 다수 코디네이터에 의해 선출되는 싱글톤입니다. 클러스터 내 모든 프로세스의 진입점이며, 프로세스 장애 감지를 담당하고 프로세스별 역할 할당 및 시스템 정보의 교환을 중계합니다.
마스터는 쓰기 서브시스템의 세대 교체를 조율합니다. 쓰기 서브시스템에는 마스터, GRV 프록시, Commit 프록시, Resolver, 트랜잭션 로그가 포함되며, 이 세 역할은 하나의 단위로 간주되어 이들 중 하나라도 장애가 발생하면 전체 역할을 교체합니다. 마스터는 변경 배치의 Commit 버전을 Commit 프록시에 제공합니다.
과거에는 Ratekeeper와 Data Distributor가 마스터와 함께 동일 프로세스에 포함되어 있었으나, 6.2 버전 이후 둘 다 클러스터 내 싱글톤이 되었으며, 수명도 마스터와 분리되었습니다.
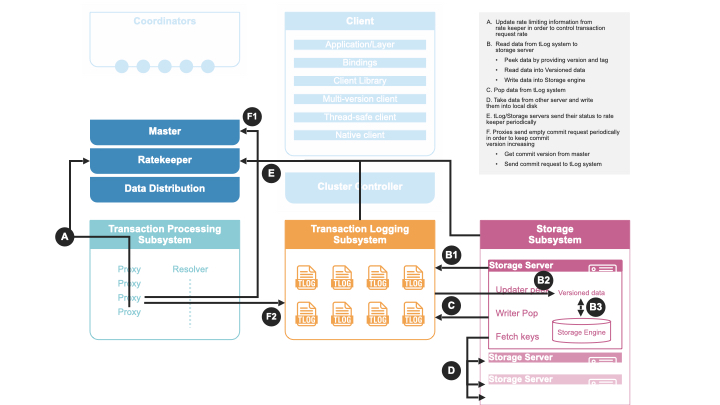
GRV 프록시는 읽기 버전 제공을 담당하며, Ratekeeper와 통신하여 읽기 버전 제공 속도를 제어합니다. 읽기 버전을 제공하기 위해, GRV 프록시는 모든 마스터에 현재 시점의 최대 Commit 버전을 요청하고, 트랜잭션 로그가 멈추지 않았는지도 확인합니다. Ratekeeper는 GRV 프록시가 읽기 버전을 제공하는 속도를 인위적으로 늦춥니다.
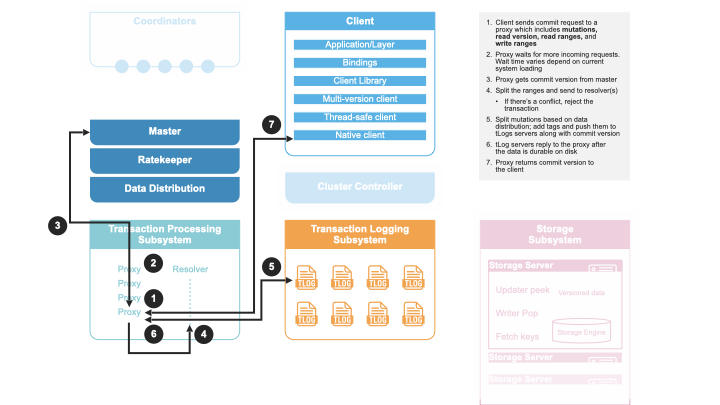
Commit 프록시는 트랜잭션 커밋, 커밋 버전 마스터 통보, 각 키 범위별 책임 스토리지 서버 추적을 담당합니다.
커밋 과정:
'\xff' 바이트로 시작하는 키 스페이스는 시스템 메타데이터용으로 예약되어 있습니다. 해당 공간에 커밋된 모든 변경 사항은 리졸버를 통해 모든 Commit 프록시에 분배됩니다. 이 메타데이터에는 키 범위와 이를 담당하는 스토리지 서버의 매핑이 포함되며, Commit 프록시가 클라이언트 요청 시 이 정보를 제공합니다. 클라이언트는 이 매핑을 캐시하고, 해당 키를 가진 서버가 없으면 캐시를 갱신하여 Commit 프록시에서 최신 서버 목록을 다시 가져옵니다.
트랜잭션 로그는 빠른 커밋 레이턴시를 위해 디스크에 변경 사항을 영속화합니다. 커밋 프록시로부터 버전 순서대로 커밋을 수신하고, 데이터가 디스크에 쓰이고 fsync된 후에만 Commit 프록시에 응답합니다. 디스크에 기록하기 전에, 해당 키 범위를 담당하는 스토리지 서버로 즉시 전달합니다. 스토리지 서버가 변경을 디스크에 영속화하면 로그에서 해당 내용을 삭제(pop)합니다(대략 커밋 후 6초 내외). 단, 로그의 디스크 내용은 프로세스가 재부팅될 때만 읽습니다. 스토리지 서버 장애 시, 해당 서버로 가야 할 변경 내용이 로그에 쌓이게 됩니다. 데이터 분배가 새로운 서버에 해당 데이터 범위의 책임을 맡기면, 장애 서버로 가야 할 로그 데이터는 버려집니다.
리졸버는 트랜잭션 간 충돌을 판별합니다. 트랜잭션이 읽은 키가 해당 트랜잭션의 읽기 버전과 커밋 버전 사이에 기록된 경우 충돌로 간주합니다. 리졸버는 최근 5초 이내 커밋된 모든 변경사항을 메모리에 보관하여 새로운 트랜잭션의 읽기와 비교합니다.
클러스터의 대부분 프로세스는 스토리지 서버입니다. 각 서버는 특정 키 범위에 할당되며, 그 범위의 모든 데이터를 저장합니다. 5초 이내 변경 사항은 메모리에, 5초 전의 데이터는 디스크에 저장합니다. 클라이언트는 반드시 최근 5초 이내의 버전에 대해 읽어야 하며, 아니면 transaction_too_old 오류가 발생합니다. SSD 스토리지 엔진은 SQLite 기반 B-트리를 사용하고, 메모리 엔진은 메모리에 append-only 로그로 저장하며, 재부팅 시 디스크에서만 읽습니다. 다가오는 FoundationDB 7.0 버전에서는 B-트리 엔진이 Redwood 엔진으로 교체될 예정입니다.
데이터 디스트리뷰터는 스토리지 서버의 생애관리를 담당하며, 각 데이터 범위를 담당할 서버를 선정하고 데이터가 모든 스토리지 서버에 균등하게 분배되도록 보장합니다. Data Distributor는 클러스터 싱글톤으로 Cluster Controller에 의해 할당 및 모니터링됩니다. 내부 문서 참고.
Ratekeeper는 시스템 부하를 모니터링하고, 클러스터가 포화에 가까울 때 프록시의 읽기 버전 제공 속도를 늦춰 클라이언트 트랜잭션 속도를 낮춥니다. 클러스터 싱글톤으로 클러스터 컨트롤러가 할당 및 모니터링합니다.
클라이언트는 FoundationDB 클러스터와 통신하기 위해 특정 언어 바인딩(라이브러리)을 사용합니다. 언어 바인딩은 여러 버전의 C 라이브러리 로드를 지원하여, 오래된 FoundationDB 클러스터와의 호환성을 제공합니다. 현재 C, Go, Python, Java, Ruby 바인딩이 공식 지원됩니다.
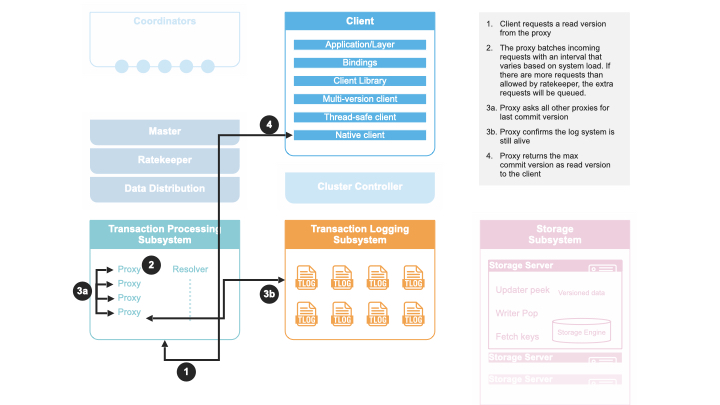
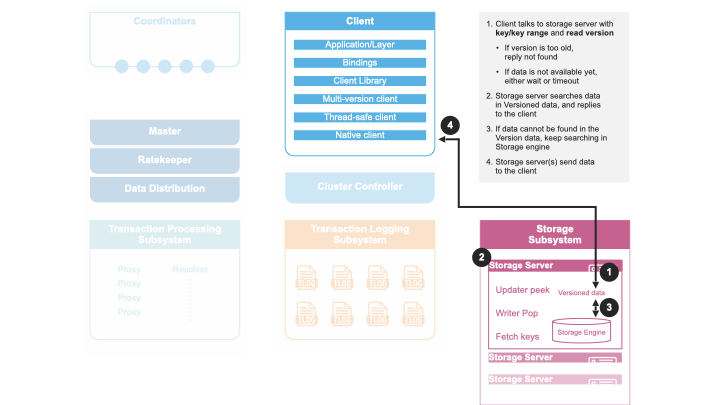
FoundationDB에서 데이터베이스 트랜잭션은 클라이언트가 먼저 GRV 프록시 중 하나에 읽기 버전을 요청하면서 시작합니다. 이 버전은 클라이언트가 알 수 있는(FoundationDB 외부 채널을 통해 알게 된 것 포함) 모든 커밋 버전보다 큽니다. 따라서 클라이언트는 이전 커밋 결과를 빠짐없이 볼 수 있습니다.
이후 클라이언트는 여러 번 스토리지 서버에 읽기 요청을 보내 동일한 읽기 버전에 대한 값을 얻습니다. 쓰기 작업은 클러스터에 전송하지 않고 클라이언트 메모리에만 보관합니다. 기본적으로, 동일 트랜잭션 내에서 기록한 키를 읽을 경우 바로 새 값을 반환합니다.
커밋 시, 클라이언트는 트랜잭션 데이터(읽기, 쓰기 모두)를 Commit 프록시에 보내고 커밋 또는 중단 응답을 기다립니다. 트랜잭션이 다른 작업과 충돌하면 클라이언트는 처음부터 다시 시도할 수 있습니다. 커밋에 성공하면 Commit 프록시는 커밋 버전을 클라이언트와 마스터에 각각 돌려주어 GRV 프록시가 최신 커밋 정보를 얻도록 합니다(이 커밋 버전은 항상 읽기 버전보다 큽니다).
FoundationDB 아키텍처는 클라이언트 읽기와 쓰기(트랜잭션 커밋)의 확장을 분리합니다. 클라이언트는 분산된 스토리지 서버에 직접 읽기 요청을 보내므로, 읽기는 스토리지 서버 수에 비례하여 선형 확장됩니다. 마찬가지로, 쓰기는 Commit 프록시, Resolver, 트랜잭션 로그 서버 프로세스 증가로 확장됩니다.
클라이언트가 GRV 프록시에 읽기 버전을 요청하면, GRV 프록시는 마스터에게 최신 커밋 버전을 묻고, 복제 정책을 충족하는 트랜잭션 로그 집합이 가동 중인지 확인합니다. 그런 다음, 가장 큰 커밋 버전을 클라이언트에 읽기 버전으로 응답합니다.
GRV 프록시가 마스터에 최신 커밋 버전을 묻는 이유는 마스터가 모든 커밋 프록시의 최대 커밋 버전 정보를 중앙에서 관리하기 때문입니다.
복제 정책에 부합하는 트랜잭션 로그의 가동 상태를 확인하는 이유는, GRV 프록시가 새로운 세대의 GRV 프록시로 대체되지 않았음을 보장하기 위해서입니다. GRV 프록시는 세대별로 매번 배정되는 Stateless 역할이므로, 만약 복구(recovery)가 발생했는데도 이전 GRV 프록시가 아직 살아있으면, 과거 GRV 프록시가 오래된 읽기 버전을 제공할 수 있습니다. 결과적으로 read-only 트랜잭션은 구버전 데이터를 볼 수 있게 됩니다(반면 read-write 트랜잭션은 중단됨). 복제 정책을 충족하는 트랜잭션 로그가 살아있는지 확인함으로써, 복구가 없었음을 확인하고 read-only 트랜잭션도 최신 데이터를 받게 합니다.
참고: 클라이언트가 직접 마스터에 읽기 버전을 요청하는 것은 마스터의 부하를 증가시키기에 권장되지 않습니다. 마스터 역할은 확장이 불가하고, 읽기 버전 제공이 비교적 가볍다 해도 트랜잭션 예산 요청, 배치 처리, 클라이언트 네트워크 연결까지 모두 마스터가 처리해야 합니다.
클라이언트 트랜잭션 커밋은 다음과 같이 진행됩니다.
not_committed 오류를 클라이언트에 반환참고: Commit 프록시는 각 리졸버에 해당 키 범위만 전달하며, 리졸버 하나라도 충돌을 감지하면 커밋이 거부됩니다. 이 방식은 한 리졸버만 충돌을 감지해 불필요한 트랜잭션 거부가 발생할 수 있지만, 실제 워크로드에서 충돌 비중이 매우 낮으므로 성능에는 큰 영향이 없습니다. 또한 트랜잭션 컨플릭트 정보는 5초 뒤 리졸버에서 삭제되어 False Conflict의 확률도 낮아집니다.
트랜잭션 처리 이외에도 다양한 백그라운드 작업이 수행됩니다.
트랜잭션 시스템은 FoundationDB 클러스터의 쓰기 파이프라인을 실행하며, 그 성능은 트랜잭션 커밋 지연에 직접적입니다. 보통 수백 밀리초 이내에 복구가 완료되지만, 가끔 몇 초가 걸릴 수도 있습니다. 트랜잭션 시스템에 장애가 발생하면 복구 프로세스가 동작해 새로운 구성(클린 상태)으로 전환됩니다. 구체적으로, 마스터 프로세스는 GRV 프록시, Commit 프록시, Resolver, 트랜잭션 로그의 상태를 모니터링하다가 이 중 하나라도 장애가 발생하면 스스로 종료합니다. 클러스터 컨트롤러가 이를 감지하면 새로운 마스터와 트랜잭션 시스템 인스턴스를 할당하여 복구를 수행합니다. 즉, 트랜잭션 처리는 여러 에폭(epoch)으로 나뉘며 각 에폭은 고유한 마스터 프로세스를 가집니다.
각 에폭에서 마스터는 여러 단계의 복구를 시작합니다. 우선, 마스터는 코디네이터에서 이전 트랜잭션 시스템 상태를 읽고, 상태를 잠궈 동시에 복구가 일어나지 않도록 합니다. 이후, 이전 트랜잭션 시스템 상태(모든 로그 서버 정보 등)를 복구하고, 이들이 트랜잭션을 더이상 받지 않도록 중단시키며, 새로운 GRV 프록시, Commit 프록시, Resolver, 트랜잭션 로그를 할당합니다. 이전 로그 서버가 중단되고 새 트랜잭션 시스템이 준비되면, 마스터가 코디네이터에 현재 시스템 정보를 기록하고 새 트랜잭션 커밋을 허용합니다. 자세한 내용은 문서 참고.
GRV 프록시, Commit 프록시, Resolver는 무상태(stateless)이므로 단순히 프로세스를 교체하면 되지만, 트랜잭션 로그는 기존 커밋 내역을 저장하므로 이전에 Commit 프록시가 클라이언트에 커밋 응답을 보냈던 트랜잭션에 대해 모든 로그가 다수의 로그 서버(예: 복제도가 3이면 3개 서버)에 영속화되어야 합니다.
복구시에는 시간도 90초 앞으로(fast forward) 진행되어 진행 중이던 클라이언트 트랜잭션이 transaction_too_old 오류로 중단됩니다. 재시도 시 클라이언트는 새로운 세대의 트랜잭션 시스템을 찾아 커밋합니다.
commit_result_unknown 오류: 트랜잭션이 커밋 중 복구가 발생하면(예: Commit 프록시가 변이 내용을 로그에 보낸 직후) 클라이언트는 commit_result_unknown을 받게 되고, 트랜잭션을 재시도합니다. FDB는 첫 번째 시도와 재시도 둘 다 커밋할 수 있습니다. commit_result_unknown은 트랜잭션이 커밋되었는지 아닐 수 있음을 의미하므로, 트랜잭션은 멱등(idempotent)하게 설계되어야 합니다.