OpenData Log는 개별 키를 가진 순서 있는 로그 수백만 개를 유지하며, 단일 인스턴스에서 수만 개의 활성 리더까지 확장됩니다. MIT 라이선스로 제공되며, Object Storage 위에 직접 구축되었고, 단일 Rust 바이너리로 배포됩니다.
Opendata _Log_는 개별 키를 가진 순서 있는 로그 수백만 개를 유지하며, 단일 인스턴스에서 수만 개의 활성 리더까지 확장됩니다. MIT 라이선스로 제공되며, Object Storage 위에 직접 구축되었고, 단일 Rust 바이너리로 배포됩니다.
빠른 시작 가이드로 2분 안에 첫 로그를 만들어 보세요: https://www.opendata.dev/docs/log/quickstart
2013년 말, Jay Kreps는 데이터 엔지니어링 분야에서 가장 영향력 있는 블로그 글 중 하나를 발표했습니다. 그는 _The Log_가 거의 모든 데이터 시스템 아래에 있는 보편적인 구성 요소인 이유를 설명했습니다. 로그는 네트워크 전반에 걸쳐 상태 기계를 복제할 수 있고, 대량의 데이터를 다운스트림 시스템으로 흘려보낼 수 있으며, 실시간 처리에 효율적인 저장소 역할도 할 수 있습니다.
그는 추상화에 대해서는 옳았지만, 이 단일 추상화가 단일 시스템(Kafka)으로도 구현될 수 있다고 잘못 가정했습니다.
로그 시스템을 10년 동안 다루며 우리가 배운 것은, 실제로 로깅은 두 가지 유형으로 나뉜다는 점입니다:
| 유형 | 설명 | 예시 |
|---|---|---|
| 퍼널링 | 높은 카디널리티 소스에서 데이터를 수집해 낮은 카디널리티 파이프로 합치는 것 | 텔레메트리 파이프라인, 클릭스트림 수집, 웨어하우스 덤프 |
| 라우팅 | 주소 지정 가능한 소스에서 주소 지정 가능한 목적지로 이벤트를 전달하는 것 | 메시징, 피드, 에이전트 트레이스 |
이 두 패턴 모두 내구성 있는 로그를 필요로 하지만, 비기능적 특성이 꽤 달라서 한쪽에 맞게 설계된 시스템은 다른 쪽에는 잘 맞지 않습니다. 어떤 사용 사례는 가능한 한 가장 크고 가장 저렴한 파이프만 있으면 됩니다. 반면 어떤 경우에는 수백만 개의 작은 로그까지 확장되어야 합니다.
Kafka가 2011년에 출시되었을 때, 즉 15년 전에는 텔레메트리를 퍼널링하기 위해 만들어졌습니다. LinkedIn의 모든 서버에서 Hadoop 및 온라인 메트릭 데이터베이스로 클릭스트림, 페이지 뷰, 메트릭 데이터를 보내기 위한 것이었습니다.
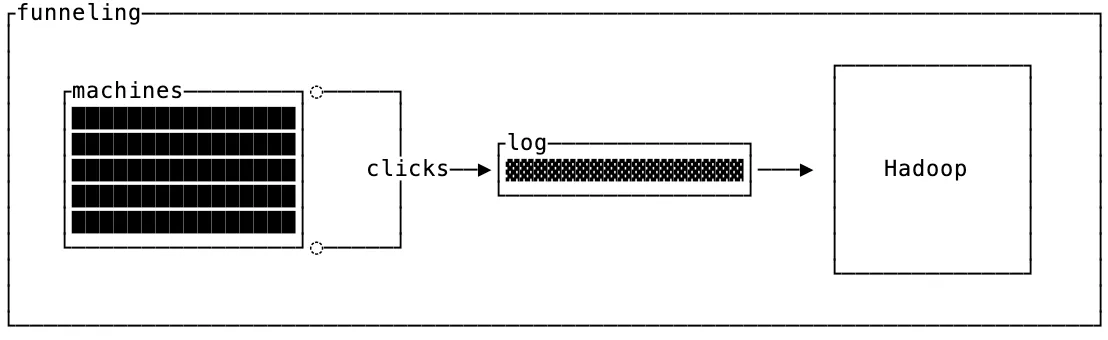
LinkedIn에서 Kafka의 초기 사용 사례들 사이에는 흥미로운 공통점이 있었습니다. Kafka로 보내는 메시지에는 키가 없었다는 점입니다. 실제로 초기 Kafka 구현은 파티션을 계산한 뒤 파티셔닝 키를 버리고, 저장소에는 페이로드만 남겼습니다. Kafka가 키와 컴팩션을 지원하게 된 것은 훨씬 나중의 일입니다.
퍼널링의 맥락에서는 이것이 놀랍지 않습니다. 소스에서 목적지로 데이터를 옮기는 것이 목적이라면, 균형 잡힌 처리량에 최적화된 단순한 파이프가 이상적이기 때문입니다.
로그의 또 다른 사용 사례는 라우팅이며, 이는 메시징 애플리케이션, 피드, 마이크로서비스 통신에서 자주 볼 수 있습니다. 입력 소스에서 이벤트를 받아 특정하게 지정된 목적지로 전달하거나, 나중에 다시 재생할 수 있도록 기록합니다.
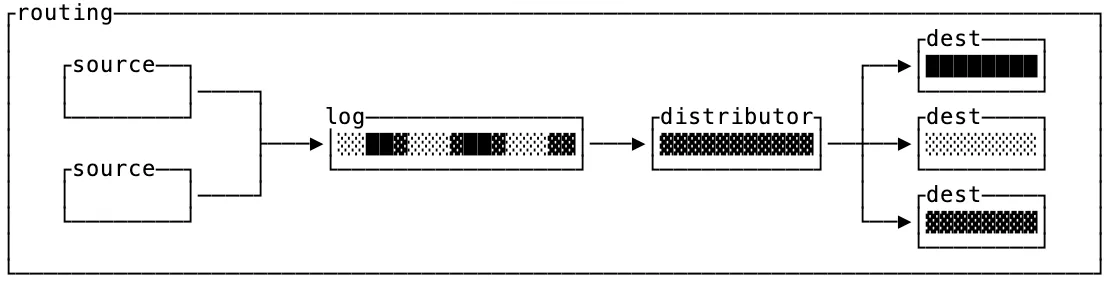
라우터의 결정적인 특징은 목적지가 특정 키의 부분집합에만 관심이 있다는 점입니다. 퍼널을 단순한 브로커로 생각한다면, 라우터는 로그의 메시지를 각 목적지로 분배하는 영리한 로직이 필요합니다.
우리는 저장소 시스템을 읽기, 쓰기, 공간 증폭 관점에서 생각하는 것을 좋아합니다. 시스템에서 이 세 가지를 모두 개선하는 유일한 방법은 사용 패턴을 제한하는 것입니다.
LinkedIn의 엔지니어들이 Kafka를 설계했을 때, 그들은 API를 제한하여 낮은 쓰기 증폭의 퍼널로 특히 잘 맞도록 만들었습니다. 데이터는 append-only 방식의 불변 파일을 통해 디스크에 기록되고, 보존 기간에서 벗어났을 때만 전체 정리되므로 쓰기 증폭 α_write는 거의 1x입니다.
이 낮은 쓰기 증폭 설계의 결과로 읽기는 크게 제한됩니다. 제공되는 유일한 읽기 API는 데이터가 기록된 순서대로 스캔하는 것이지만, 만약 그게 원하는 방식이라면 읽기 증폭 α_read도 역시 1x입니다.
라우터는 기반 로그에 대해 다른 접근 패턴이 필요합니다. 하나의 거대한 로그 대신, 라우터는 수십만 개 혹은 수백만 개의 개별 로그를 저장하고 싶어 합니다.
Kafka 파티션은 서로 격리되어 있으므로, 각 라우팅 로그를 자체 파티션에 저장하는 것은 현실적이지 않습니다. 즉, Kafka 같은 퍼널에서 키로 특정 메시지를 찾으려면 읽기 증폭은 전체 파티션 크기를 레코드 크기로 나눈 비율이 됩니다:
|partition|
α_read = ─────────────
|record|
이것은 거의 최악에 가까운 읽기 증폭이며, Kafka를 라우터로 사용하는 것을 비현실적으로 만듭니다.
오늘 우리는 라우팅 로그 사용 사례를 위한 더 나은 메커니즘인 OpenData _Log_를 발표합니다(퍼널링 사용 사례에서 Kafka를 대체할 더 나은 대안은 OpenData Buffer를 참고하세요).
_Log_는 SlateDB 위에 구축된 MIT 라이선스, object-native, key-oriented 로그입니다. 이를 역순으로 풀어보면 다음과 같습니다:
첫 번째 특징만으로도 Log는 Kafka와 뚜렷하게 다르며, 라우팅에 더 적합합니다. 다음 두 가지는 이것을 좋은 인프라이자 장기적으로 탄탄한 투자로 만들어 줍니다.
_Log_는 키 카디널리티가 높더라도 특정 키에 대한 순서 있는 레코드를 읽을 수 있게 해줍니다:
let log = LogDb::open(...);
// user-123의 로그를 스캔
let mut iter = log.scan(Bytes::from("user-123"), ..).await?;
while let Some(entry) = iter.next().await? {
println!("seq={}, value={:?}", entry.sequence, entry.value);
}
log.scan()의 매개변수에 파티션이 없다는 점에 주목하세요. 키로 로그를 지정하면 값을 돌려받습니다.
라우팅 사용 사례에서 파티셔닝은 좋지 않은 데이터 모델입니다. 대신 올바른 추상화 수준은 Kafka의 파티션보다 훨씬 더 많은 값을 지원할 수 있는 “키”입니다. 비교해 보면 다음과 같습니다:
| Partitions (Kafka) | Keys (Log) | |
|---|---|---|
| 포인트 읽기 | 특정 키의 값을 찾으려면 전체 파티션을 건초더미에서 바늘 찾기 식으로 스캔해 그 키의 데이터를 찾아야 함 | 개별 키는 LSM 인덱스에서 prefix로 효율적으로 스캔 가능 |
| 격리 | 문제 있는 키 하나가 전체 파티션의 head-of-blocking을 유발함 | 위치 메타데이터를 키별로 추적할 수 있어 poison-pill 메시지의 영향이 국소화됨 |
| 리스케일링 | 파티션 수 변경은 임의 규모의 데이터 셔플을 요구하고 모든 컨슈머를 교란하는 악몽 같은 작업임. 핫 파티션도 우회하기 어렵다 | 키는 range partition으로 할당되며, _Log_를 분할하거나 병합할 때 컨슈머 오프셋을 바꿀 필요가 없다. 리더는 개별 키 단위까지 확장 가능 |
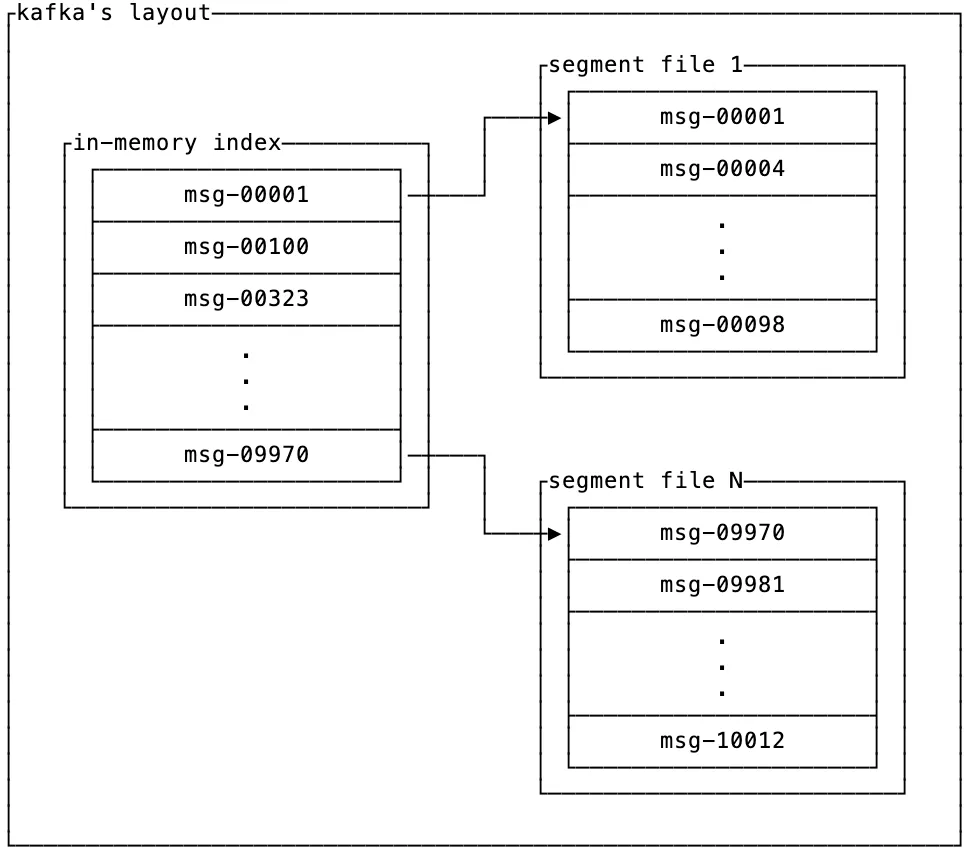
이를 지원하기 위해 _Log_는 (key, sequence)를 키로 하고 sequence 범위로 분할된 segmented LSM tree로 설계되었습니다.
LSM tree가 익숙하지 않다면 10초 버전 설명은 이렇습니다. 최근 데이터는 로그로 저장하고, 오래된 데이터는 정렬된 배열로 컴팩션하는 자료구조입니다(10분 버전이 궁금하다면 이 글을 읽어보세요).
실제로 이 아키텍처는 새 데이터를 빠르게 append하면서도, 오래된 데이터에는 이진 탐색으로 효율적으로 접근할 수 있음을 의미합니다. 그 결과 _Log_는 특정 로그의 데이터를 가져오는 지연 시간을 늘리지 않으면서 수백만 개의 독립적인 keyed log를 지원할 수 있습니다.
아래 차트(및 다른 모든 차트)는 AWS S3를 대상으로 m5n.xlarge 인스턴스 유형에서 실제 트래픽으로, 워크로드를 바꿔가며 이를 보여줍니다. 이벤트 분포는 키 기준으로 무작위 샘플링했습니다:
FIG — POLL LATENCY
고정된 20 MB/s 인제스트에서 키 수를 100K→1M으로 늘려도, 단일 키의 로그를 읽을 때 p50 poll latency는 저하되지 않습니다.
p50 latency
아키텍처에서 “segmented” 부분은 _Log_가 데이터를 효율적으로 만료 처리하는 방식입니다. 각 세그먼트는 독립적으로 컴팩션할 수 있는 완전한 LSM tree입니다. 시퀀스 번호 범위는 시간 구간에 깔끔하게 대응하므로, 더 이상 보존할 필요가 없는 오래된 LSM tree는 통째로 제거할 수 있습니다.
개념적으로는 다음과 같습니다. 오래된 세그먼트에서는 데이터가 키별로 깔끔하게 정렬되어 있고, 새로운 세그먼트는 키가 섞여 있을 수 있지만 시퀀스 번호 순으로 정렬되어 있습니다:
┌──────────────────┐ ╔═Log═══════════════════════════════╗
│ scan(key1, 1330) │ ║ ║
└──────────────────┘ ║ ┌seq [0-999]────────────────────┐ ║
│ ║ └───────────────────────────────┘ ║
│ ║ ║
│ ║ ┌seq [1000-1999]────────────────┐ ║
│ ║ │ ┌─────────────────────┐ │ ║
│ ║ │ │ key1@1002 : val11 │ │ ║
│ ║ │ │ ┌─────────────────┐ │ │ ║
└─────────────╬─┼───┼▶│key1@1499 : val13│ │ │ ║
║ │ │ │key1@1540 : val14│ │ │ ║
║ │ │ └─────────────────┘ │ │ ║
║ │ │ key2@1422 : val23 │ │ ║
║ │ └─────────────────────┘ │ ║
║ └───────────────────────────────┘ ║
║ ... ║
║ ┌seq [current]──────────────────┐ ║
║ │ ┌───────────────────────────┐ │ ║
║ │ │ key1@9100 : val31 │ │ ║
║ │ │ key2@9101 : val32 │ │ ║
║ │ ├───────────────────────────┤ │ ║
║ │ │ key1@9102 : val33 │ │ ║
║ │ │ key2@9103 : val34 │ │ ║
║ │ └───────────────────────────┘ │ ║
║ └───────────────────────────────┘ ║
╚═══════════════════════════════════╝
저장소 구현의 전체 세부 사항은 GitHub의 RFC를 확인하세요.
파티션은 최적이 아닌 데이터 모델링 개념이지만, 단일 머신을 넘어 수평 확장을 하려면 어떤 형태로든 데이터 분배는 필요합니다. _Log_를 수평 확장하는 첫 번째 전략은 여러 리더를 배포하는 것입니다. 데이터는 S3에서 직접 가져오므로 원하는 만큼 읽기 복제본을 띄울 수 있습니다.
특정 대상 키 범위로 한정된 리더를 배포하면 읽기의 캐시 지역성을 개선하여 read amplification을 줄이는 추가 이점이 있습니다. 해시 또는 무작위 파티셔닝과 달리, 범위 기반 리더에서 사전식으로 가까운 키에 대한 쿼리는 cold miss가 object storage에서 가져온 데이터를 이후 같은 리더를 조회하는 다른 클라이언트도 읽게 될 가능성이 높습니다(반대로 다른 범위의 블록으로 캐시를 흔들어 놓지 않게 됩니다).
FIG — SCALING READERS
reader ranges P
range-split random sharding
| read-amp | GETs / poll | poll p50 | |
|---|---|---|---|
| range | |||
| random |
범위 리더는 각각 키 공간의 연속된 1/P 조각을 스캔하므로, 더 작은 범위로 한정된 리더를 추가할수록 read amplification은 감소합니다.
_Log_의 아키텍처는 SlateDB 위에 구축되므로, 데이터를 셔플하지 않고도 스케일 아웃과 스케일 인이 가능한 능력을 그대로 물려받습니다. 메타데이터만 수정하는 작업으로 노드를 분할할 수 있습니다. 오래된 데이터는 결국 컴팩션되며 분할 작업이 실체화될 때까지 object storage에 손대지 않은 채 남아 있습니다.
그 결과 리스케일링 작업은 컨슈머에게 거의 투명합니다. 새로운 Log 인스턴스를 가리키게 하면, 이전에 멈춘 정확히 같은 오프셋에서 다시 이어갈 수 있습니다.
세부 사항이 궁금하다면 이 메커니즘이 어떻게 동작하는지 잘 이해할 수 있도록 문서를 읽어보세요.
_Log_는 운영 비용 측면에서 object storage의 뛰어난 특성 일부를 그대로 이어받습니다. 워크로드에는 변수가 너무 많아서 정확한 비용 추정치를 제시하기는 어렵지만, 감을 잡기 위해 말하자면 단일 m5n.xlarge 노드에서 거의 100 MB/s를 인제스트할 수 있었습니다(동시 읽기 없음). 읽기를 밀어붙이기 위해 20 MB/s를 인제스트했을 때는, 8GB 캐시와 100만 개의 키 환경에서 50,000개의 동시 follower가 각각 자신의 keyed log를 tailing하는 상황을 p50 latency 50ms 미만으로 지속할 수 있었습니다.
FIG — WHAT ONE BOX COSTS
| Line item | Driver | Est./mo |
|---|---|---|
| Compute | 1× m5n.xlarge, on-demand | $174 |
| S3 writes | flush every ~2–3 s ≈ 1.0M PUT | ~$10 |
| S3 storage | 1.73 TB/day × 1 day | ~$40 |
| Total | compute + S3 | ~$224/mo |
| + GETs for your read pattern — most reads hit the 8 GB cache, so this stays workload-dependent and sits outside the total. |
얻을 수 있는 것: 20 MB/s 인제스트 · 50,000 동시 follower · 1M 키. 비용의 대부분은 컴퓨트이며, S3 비용은 반올림 수준입니다. 리더 하나를 추가하면 약 50k follower를 더 지원하며 비용은 월 +$174입니다.
리더 노드는 선형적으로 확장되므로, 리더를 추가해 읽기 처리량을 늘릴 수 있습니다. 우리가 사용한 특정 구성은 약 2-3초마다 S3로 flush했지만, 더 빠른 내구성 보장을 위해 write-ahead-logging을 설정할 수도 있습니다. 다만 그 경우 추가적인 S3 PUT 요청 비용이 발생합니다.
높은 카디널리티 키를 처리할 수 있는 수준까지 _Log_를 만들기 위해 우리가 내린 몇 가지 결정이 있으며, 공짜는 없습니다. 특히 poll latency는 인제스트 속도에 따라 증가합니다. 인제스트 속도가 높아지면 컴팩션이 키를 효율적인 조회를 위해 한곳에 모아놓을 기회를 얻기 전에 캐시가 뜨거운 데이터를 내보내게 됩니다.
FIG — LATENCY vs INGEST
고정된 키 수에서 인제스트를 증가시킨 경우입니다. live tail이 캐시에 들어가는 동안(약 5 MB/s 이하) poll은 빠르지만, 그 지점을 넘으면 읽기가 object storage로 흘러나가며 MB/s가 늘어날 때마다 latency가 올라갑니다.
p99 latency p50 latency p50–p99 band
이에 대한 우회책은 위에서 설명했듯이, 읽기 복제본을 더 작은 범위로 한정해 다른 범위의 데이터를 담은 블록으로 캐시가 흔들리지 않게 하는 것입니다.
또한 _Log_는 object storage latency의 한계도 물려받지만, 실제로는 25 MiB/s 처리량에서 p50과 p99 poll latency를 각각 약 30ms와 약 300ms로 얻을 수 있습니다.
마지막으로 _Log_는 컨슈머 오프셋을 직접 추적하지 않습니다. 메타데이터와 데이터를 분리하면 더 유연한 배포 메커니즘이 가능해지며, 컨슈머 측 오프셋 추적에는 SlateDB 같은 Key-Value 저장소 사용을 권장합니다.
_Log_는 MIT 라이선스로 제공되며, 오늘 바로 OpenData의 일부로 사용할 수 있습니다. 빠른 시작 가이드를 따라 몇 분 안에 실행해 볼 수 있습니다.
질문이 있다면 Discord에서 찾아주세요. 그리고 _Log_가 유용하다면 GitHub에서 스타를 눌러 주세요.