넷플릭스의 Graph Search 플랫폼이 구조화된 DSL 기반 검색에서 LLM을 활용한 자연어 기반 필터 생성으로 진화한 과정을 소개하고, RAG 기반 컨텍스트 엔지니어링, 검증, 신뢰 구축 UI 전략, 엔드투엔드 아키텍처를 설명한다.
URL: https://netflixtechblog.com/the-ai-evolution-of-graph-search-at-netflix-d416ec5b1151

13분 읽기
7시간 전
작성자: Alex Hutter , Bartosz Balukiewicz
이전 블로그 글(파트 1, 파트 2, 파트 3)에서는 넷플릭스의 Graph Search 플랫폼이 기업(enterprise) 생태계 안에서 연합(federated) 데이터 세트 전반을 검색할 때의 과제를 어떻게 해결하는지 상세히 다뤘습니다. 플랫폼은 확장성이 높고 설정도 쉽지만, 입력으로 구조화된 쿼리 언어에 의존한다는 한계가 있습니다. 자연어 기반 검색은 이전부터 가능했지만, 구현에 필요한 노력 수준이 높았습니다. 이제는 쉽게 이용 가능한 AI, 특히 **대규모 언어 모델(LLM)**의 등장으로 더 적은 투자로도 AI 검색 기능을 통합하고 정확도를 개선할 수 있는 새로운 기회가 열렸습니다.
Text-to-Query와 Text-to-SQL은 이미 잘 알려진 문제이지만, GraphQL 생태계에서 분산된 Graph Search 데이터의 복잡성은 혁신적인 해법을 필요로 합니다. 이 글은 3부작 시리즈의 첫 번째 글로, 우리가 어떤 방식으로 해법을 구현했고 성능을 평가했으며, 궁극적으로 이를 자체 운영(self-managed) 플랫폼으로 발전시켰는지를 다룰 예정입니다.
자연어 검색이란, Graph Search Filter 도메인 특화 언어(DSL)처럼 복잡한 구조화 쿼리 언어 대신 일상적인 언어로 정보를 조회할 수 있는 능력을 말합니다. 사용자가 Content 및 Business Products 애플리케이션 제품군에 포함된 수백 개의 다양한 UI와 상호작용할 때, 자주 하는 작업 중 하나는 아래와 같은 데이터 테이블을 필터링하는 것입니다.
전체 크기로 보려면 Enter를 누르거나 클릭하세요
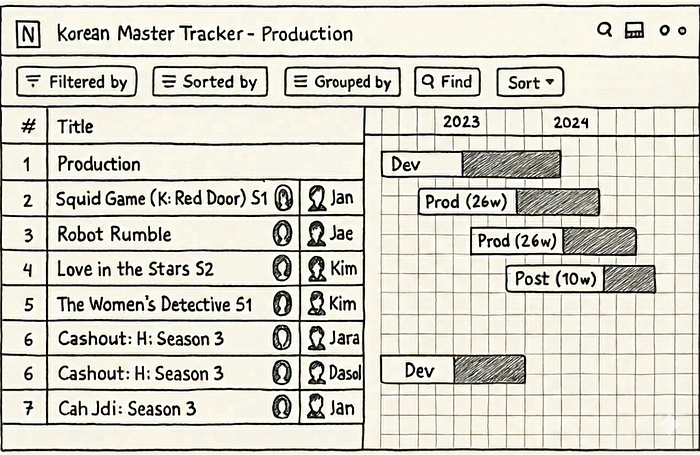
Content 및 Business Products 애플리케이션 화면 예시
이상적으로는 사용자가 “90년대에 나온 미국 로봇 영화 전부 보고 싶어.” 같은 질의를 만족시키고 싶을 뿐입니다. 하지만 기반 플랫폼이 Graph Search Filter DSL로 동작하기 때문에, 애플리케이션은 중간자 역할을 합니다. 사용자는 UI 요소(패싯 토글, 쿼리 빌더 등)를 통해 요구사항을 입력하고, 시스템은 그 상호작용을 프로그래밍 방식으로 유효한 DSL 쿼리로 변환하여 데이터를 필터링합니다.
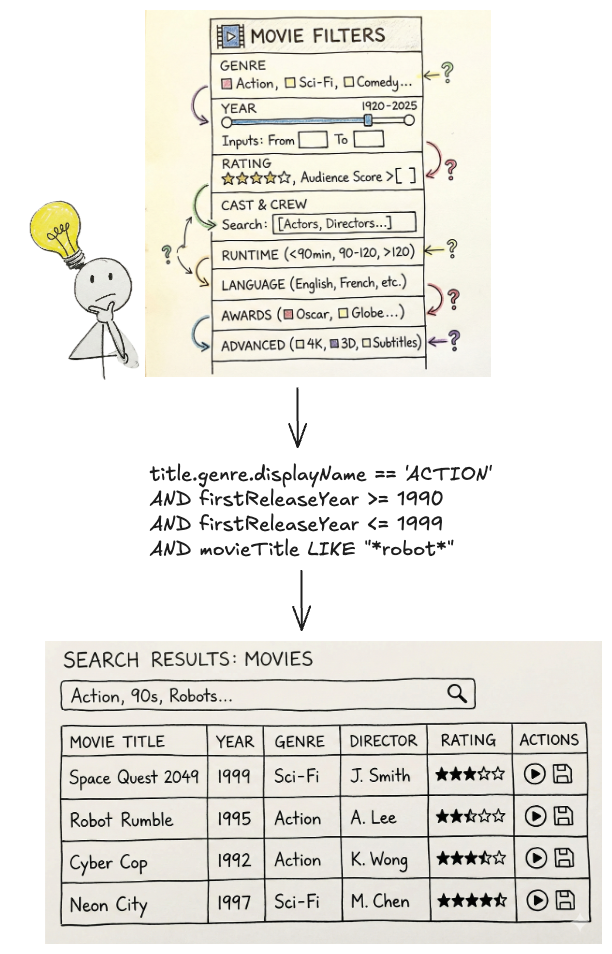
필터링 및 DSL 생성의 복잡성
이 과정에는 몇 가지 문제가 있습니다.
오늘날 많은 애플리케이션이 사용자 입력을 수집하기 위해 각자 맞춤형(bespoke) 컴포넌트를 사용합니다. 경험은 애플리케이션마다 다르고 DSL 지원도 일관되지 않습니다. 사용자는 목표를 달성하기 위해 각 애플리케이션의 사용법을 “학습”해야 합니다.
또한 어떤 도메인은 인덱스 내에 수백 개의 필드가 있어 패싯이나 필터 대상으로 사용할 수 있습니다. _도메인 전문가(SME)_는 무엇을 하고 싶은지 정확히 알고 있더라도, 대규모 UI 폼을 느린 속도로 채우고 질문을 번역해 Graph Search가 필요로 하는 표현으로 인코딩하는 과정에서 병목이 생길 수 있습니다.
무엇보다 중요한 점은 사용자는 쿼리 빌더, 컴포넌트, DSL 같은 기술적 구성 요소가 아니라 자연어로 생각하고 작업한다는 것입니다. 사용자에게 문맥 전환을 요구하면 마찰이 생겨 속도가 느려지거나 진행 자체가 막힐 수 있습니다.
이제 쉽게 이용 가능한 AI 구성 요소 덕분에 사용자는 자연어로 시스템과 상호작용할 수 있습니다. 이제 과제는 넷플릭스의 복잡한 엔터프라이즈 상태를 자연어로 검색하는 경험이 직관적이고 신뢰할 만하도록 만드는 것입니다.

자연어 질의를 Graph Search Filter DSL로 변환
우리는 이 요구를 충족하기 위해 자연어로부터 Graph Search Filter 문을 생성하는 방향을 선택했습니다. 목표는 RAG(Retrieval-Augmented Generation)을 통해 기존 애플리케이션을 대체하는 것이 아니라 **보강(augment)**하는 것입니다. 즉, 생태계의 애플리케이션들이 각 도메인 특성에 맞게 데이터를 처리·표현할 수 있도록 새로운 도구와 역량을 제공하려 합니다. 또한 여기서의 모든 작업은 향후 Graph Search 위에 RAG 시스템을 구축하는 데에도 직접적으로 적용 가능합니다.
text-to-query 프로세스의 핵심 기능은 사용자의(대개 모호한) 자연어 질문을 구조화된 쿼리로 변환하는 것입니다. 우리는 주로 LLM을 사용해 이를 수행합니다.
더 깊이 들어가기 전에 Graph Search Filter DSL의 구조를 빠르게 복습해 보겠습니다. 각 Graph Search 인덱스는 GraphQL 쿼리로 정의되며 필드들의 집합으로 구성됩니다. 각 필드는 boolean, string 같은 타입을 가지며, 일부는 통제된 어휘(Controlled Vocabulary)—표준화되고 관리되는 값 목록(열거형 또는 외래 키처럼)—에 의해 허용 값이 제한됩니다. 필드 이름은 비교(예: > 또는 ==)나 포함/제외 연산자(예: IN)를 사용해 표현식을 구성하는 데 사용됩니다. 그리고 이 표현식들은 논리 연산자(예: AND)로 결합해 복잡한 문장을 만들 수 있습니다.
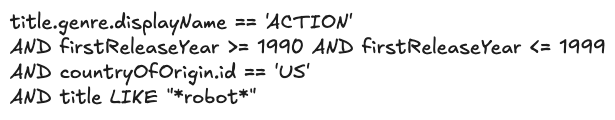
Graph Search Filter DSL
이제 변환 프로세스를 더 엄밀하게 정의할 수 있습니다. 우리는 LLM이 구문적으로(syntactic), 의미적으로(semantic), 실용적으로(pragmatic) 올바른 Graph Search Filter DSL 문장을 생성하도록 해야 합니다.
구문적 정확성은 쉽습니다—파싱이 되는가? 구문적으로 정확하려면 생성된 문장이 올바른 형태(well formed)여야 하며 Graph Search Filter DSL 문법을 따라야 합니다.
의미적 정확성은 인덱스 자체에 대한 지식이 필요해 추가 복잡성이 있습니다. 의미적으로 정확하려면:
실용적 정확성은 훨씬 더 어렵습니다. 생성된 필터가 사용자의 의도를 실제로 담고 있는가를 묻습니다.
다음 섹션에서는 LLM에 제공할 지시(instructions)에 맞는 적절한 컨텍스트를 만들기 위해 사용자 질문을 어떻게 전처리하는지(둘 다 LLM 상호작용에 핵심), 그리고 생성된 문장을 검증하고 사용자가 결과를 이해하고 신뢰하도록 돕기 위해 어떤 후처리를 수행하는지 설명합니다.
전체 프로세스는 높은 수준에서 다음과 같습니다.
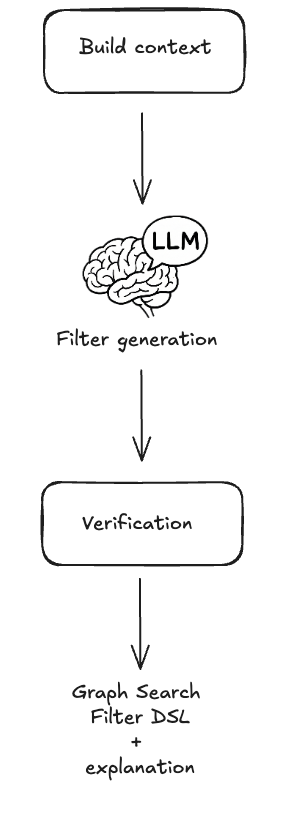
Graph Search Filter DSL 생성 프로세스
필터 생성 작업 준비는 대부분 적절한 컨텍스트를 엔지니어링하는 일입니다. LLM이 의미적으로 올바른 필터를 구성하려면 인덱스의 필드와 메타데이터에 접근해야 합니다. 인덱스는 GraphQL 쿼리로 정의되므로 GraphQL 스키마의 타입 정보를 사용해 필요한 정보의 상당 부분을 도출할 수 있습니다. 일부 필드의 경우 스키마에 없는 추가 정보도 제공할 수 있는데, 특히 통제된 어휘에서 가져오는 허용 값(permissible values)이 그렇습니다.
인덱스의 각 필드는 아래와 같은 메타데이터와 연관되며, 이 메타데이터가 컨텍스트로 제공됩니다.

Graph Search 인덱스 표현
_통제된 어휘(controlled vocabulary)_는 SME 또는 도메인 오너가 정의하는 유한한(한정된) 허용 값 집합으로 구성된 특정 필드 타입입니다. 인덱스 필드는 특정 통제된 어휘와 연결될 수 있습니다. 예를 들어 국가(countries)는 스페인(Spain), 태국(Thailand) 같은 구성원을 갖고, 생성된 문장에서 해당 필드를 사용할 때는 반드시 그 어휘의 값만 참조해야 합니다.
단순하게 모든 메타데이터를 LLM 컨텍스트로 제공하는 방식은 간단한 경우에는 잘 동작했지만 확장되지 않았습니다. 어떤 인덱스는 수백 개의 필드를 갖고, 어떤 통제된 어휘는 수천 개의 유효 값을 갖습니다. 특히 통제된 어휘 값과 그 부가 메타데이터까지 전부 제공하면 컨텍스트가 커집니다. 이는 지연 시간(latency)을 늘리고 생성된 필터 문의 정확성을 떨어뜨립니다. 그렇다고 값들을 제공하지 않을 수도 없습니다. LLM의 생성 결과를 그라운딩(grounding)해야 했고, 값이 없으면 LLM이 존재하지 않는 값을 자주 환각했기 때문입니다.
따라서 컨텍스트를 적절한 부분집합으로 큐레이션하는 문제를, 잘 알려진 RAG 패턴으로 해결했습니다.
앞서 언급했듯 일부 인덱스는 수백 개의 필드를 갖지만, 대부분의 사용자 질문은 보통 그중 몇 개만 참조합니다. 모든 필드를 포함하는 데 비용이 없다면 그렇게 하겠지만, 앞서 말했듯 지연 시간과 생성 쿼리의 정확성(예: 건초더미에서 바늘 찾기 문제), 그리고 비결정성 결과 측면에서 비용이 있습니다.
컨텍스트에 포함할 필드의 부분집합을 결정하기 위해 우리는 사용자 질문의 의도(intent)와 필드를 “매칭”합니다.
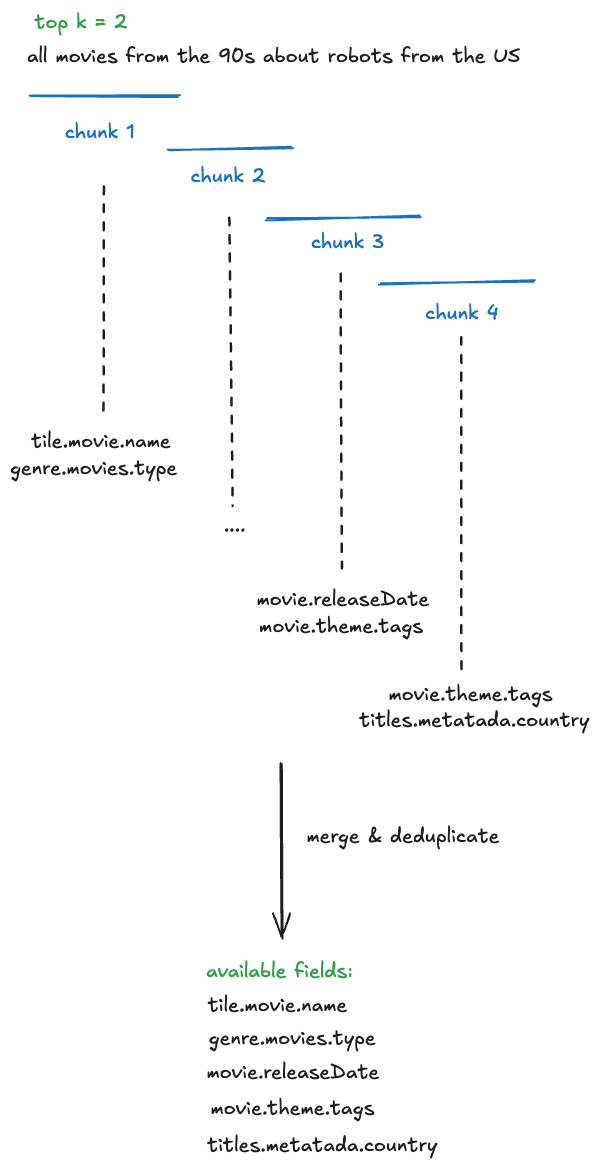
Field RAG 프로세스(청킹, 병합, 중복 제거)
통제된 어휘 타입의 인덱스 필드는 특정 통제된 어휘와 연결됩니다(다시 국가가 한 예). 사용자 질문이 특정 통제된 어휘의 값을 참조하는지 추론할 수 있습니다. 그리고 어떤 통제된 어휘 값이 존재하는지 알면, Field RAG 단계에서 식별되지 않았더라도 컨텍스트에 포함해야 할 추가 관련 인덱스 필드를 찾아낼 수 있습니다.
이 작성자의 업데이트를 무료로 받으려면 Medium에 가입하세요.
각 통제된 어휘 값은 다음을 가집니다.
통제된 어휘 필드에 대해 컨텍스트에 포함할 값의 부분집합을 결정하고(또한 추가 필드를 추론하기 위해), 사용자 질문과 값을 “매칭”합니다.
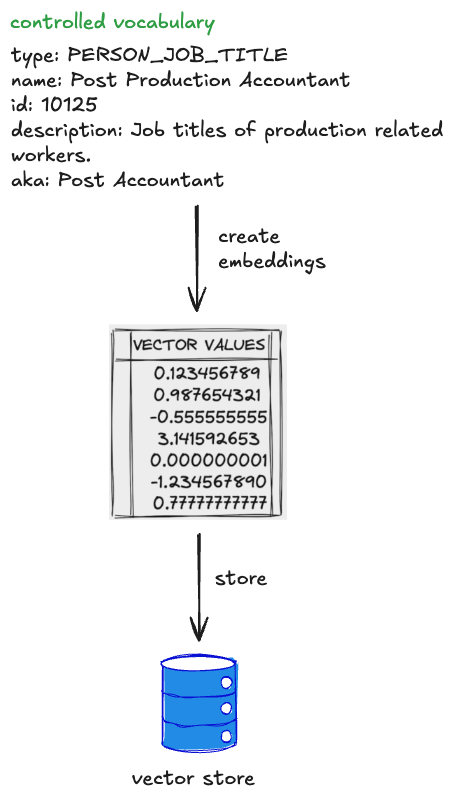
통제된 어휘 RAG
필드 RAG와 통제된 어휘 RAG 두 접근을 결합하면, 각 입력 질문은 사용 가능한(그리고 매칭된) 필드와 값으로 해석되는 솔루션을 얻게 됩니다.
전체 크기로 보려면 Enter를 누르거나 클릭하세요
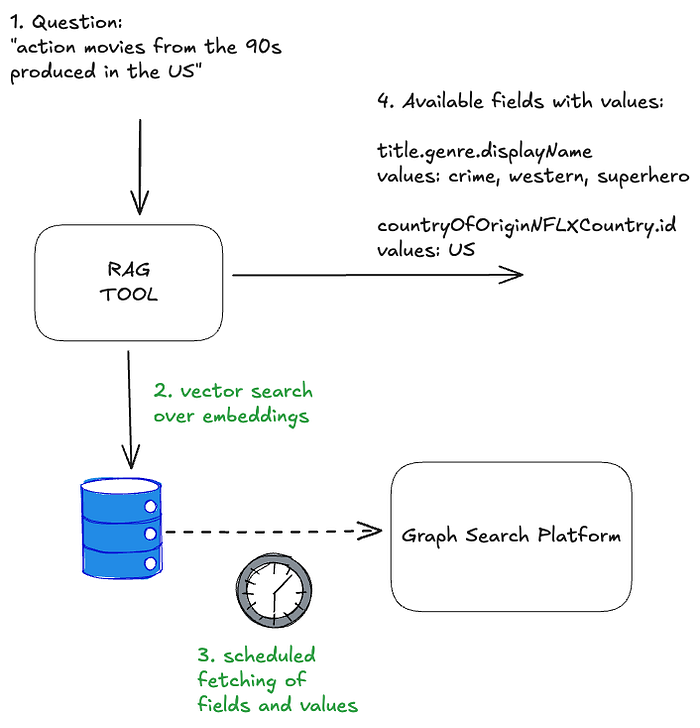
필드 및 CV RAG
RAG 도구가 생성하는 결과의 품질은 다양한 파라미터(또는 “레버”)를 튜닝함으로써 크게 향상될 수 있습니다. 여기에는 재정렬(reranking), 청킹, 다른 임베딩 생성 모델 선택 전략 등이 포함됩니다. 이러한 요소들에 대한 신중하고 체계적인 평가는 이 시리즈의 다음 파트에서 다룰 예정입니다.
컨텍스트가 구성되면, 지시문 세트와 사용자 질문과 함께 LLM에 제공됩니다. 지시문은 다음과 같이 요약할 수 있습니다. “자연어 질문이 주어졌을 때, 다음 인덱스 필드 및 메타데이터의 가용성을 기반으로 구문적으로, 의미적으로, 실용적으로 올바른 필터 문을 생성하라.”
전체 크기로 보려면 Enter를 누르거나 클릭하세요
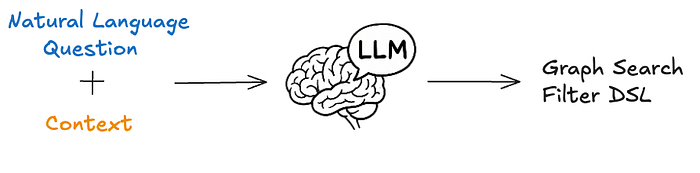
Graph Search Filter DSL 생성
LLM이 필터 문을 생성한 뒤, 우리는 사용자에게 반환하기 전에 결정론적으로(deterministically) 이를 검증합니다.
구문적 정확성은 LLM 출력이 파싱 가능한 필터 문인지 보장합니다. 우리는 커스텀 DSL을 위해 구축된 AST(Abstract Syntax Tree) 파서를 사용합니다. 생성된 문자열이 유효한 AST로 파싱되지 않으면 쿼리가 잘못 생성되었고 생성 단계에 근본적인 문제가 있음을 즉시 알 수 있습니다.
이 문제를 해결하는 또 다른 접근은 일부 LLM이 제공하는 structured outputs 모드를 사용하는 것입니다. 하지만 초기 평가 결과, 커스텀 DSL은 네이티브로 지원되지 않아 추가 작업이 필요했으며 결과도 엇갈렸습니다.
RAG 패턴으로 컨텍스트를 신중하게 엔지니어링하더라도, LLM은 생성된 필터 문에서 필드와 사용 가능한 값을 때때로 환각합니다. 이 현상을 막는 가장 직접적인 방법은 생성된 필터를 사용 가능한 인덱스 메타데이터에 대해 검증하는 것입니다. 우리는 이미 필터 문에 대한 AST를 갖고 있고, 메타데이터는 컨텍스트 엔지니어링 단계에서 쉽게 얻을 수 있으므로 이 방식은 시스템 전체 지연 시간에 영향을 주지 않습니다.
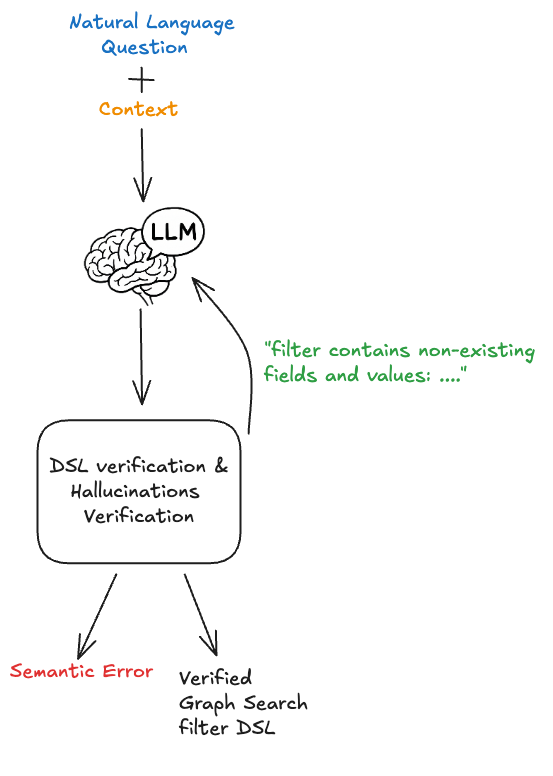
DSL 검증 및 환각
환각이 탐지되면 사용자에게 오류로 반환하여 쿼리를 다듬도록 안내할 수 있고, 또는 자기 교정(self correction)을 위한 피드백 루프 형태로 LLM에 다시 제공할 수도 있습니다.
이는 필터 생성 시간을 늘리므로 제한된 재시도 횟수로 신중하게 사용해야 합니다.
우리가 생성된 필터의 실용적 정확성은 검증하지 않는다는 점을 눈치챘을지도 모릅니다. 이 과제가 가장 어렵습니다. 필터는 파싱되고(구문적), 실제 필드를 사용하지만(의미적), 그것이 사용자가 의도한 바인가요? 사용자가 **“Dark”**를 검색하면, 특정 독일 SF 시리즈 _Dark_를 의미하는 걸까요, 아니면 분위기 카테고리인 **“어두운 TV 쇼”**를 탐색하는 걸까요?
사용자 의도와 생성된 필터 문 사이의 간극은 종종 모호성(ambiguity)에서 비롯됩니다. 모호성은 자연어의 압축(semantic compression)에서 발생합니다. 사용자는 **“실종된 소년과 동굴이 나오는 독일 시간여행 미스터리”**라고 말하지만, 인덱스는 releaseYear, genreTags, synopsisKeywords 같은 이산적인 메타데이터 필드를 갖고 있습니다.
그렇다면 사용자가 원치 않는 잘못된 답으로 유도되거나, 묻지 않은 질문에 대한 답을 받게 되는 일을 어떻게 방지할까요?
우리가 모호성을 다루는 방법 중 하나는 _작업 내용을 보여주는 것_입니다. 생성된 필터를 UI에서 사용자 친화적으로 시각화해, 사용자가 우리가 반환하는 답이 원하는 것인지 매우 명확히 확인할 수 있게 하여 결과를 신뢰하도록 합니다.
비기술 사용자에게는 원시 DSL 문자열(예: origin.country == ‘Germany’ AND genre.tags CONTAINS ‘Time Travel’ AND synopsisKeywords LIKE ‘*cave*’)을 보여줄 수 없습니다. 대신 그 기반이 되는 AST를 UI 컴포넌트로 반영합니다.
LLM이 필터 문을 생성한 뒤, 이를 AST로 파싱하고, 그 AST를 기존 UI의 “칩(Chips)”과 “패싯(Facets)”으로 매핑합니다(아래 참고). LLM이 origin.country == ‘Germany’ 같은 필터를 생성하면, 사용자는 “Country” 드롭다운이 “Germany”로 미리 선택된 것을 보게 됩니다. 이는 사용자에게 즉각적인 시각적 피드백을 제공하고, 결과 개선이나 추가 실험이 필요할 때 표준 UI 컨트롤로 쉽게 질의를 미세 조정할 수 있게 합니다.
전체 크기로 보려면 Enter를 누르거나 클릭하세요
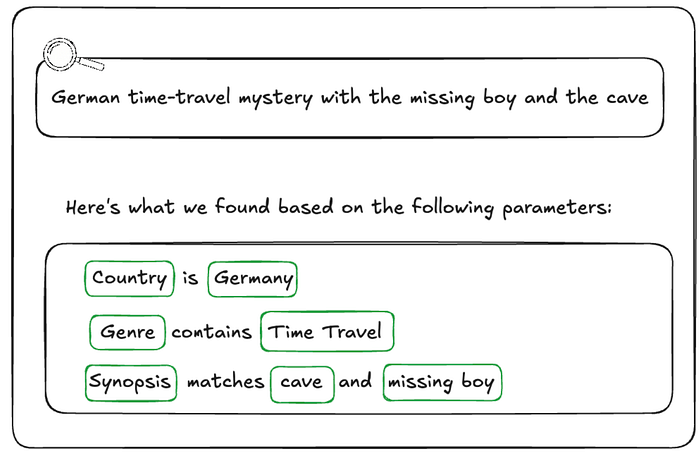
생성된 필터 시각화
우리가 개발한 또 다른 모호성 제거 전략은 쿼리 시점에 발생합니다. 사용자에게 “@mentions”를 사용해 입력이 알려진 엔티티를 참조하도록 제약할 수 있는 기능을 제공합니다. Slack과 비슷하게 @를 입력하면, 특화된 UI Graph Search 컴포넌트에서 엔티티를 직접 검색할 수 있어 여러 통제된 어휘(그리고 출시 연도 같은 다른 식별 메타데이터)에 쉽게 접근할 수 있습니다. 이를 통해 사용자는 자신이 의도한 엔티티를 선택하고 있다는 확신을 가질 수 있습니다.
사용자가 “_@dark_는 언제 제작됐어”라고 입력하면, 이는 Series 통제된 어휘를 참조한다는 것을 명확히 알 수 있습니다. 따라서 RAG 추론 단계를 건너뛰고 해당 컨텍스트를 하드코딩할 수 있어 실용적 정확성이 크게 향상되고(그리고 과정에 대한 사용자 신뢰도 높아집니다).
전체 크기로 보려면 Enter를 누르거나 클릭하세요

UI에서 @mentions 사용 예시
앞서 언급했듯 솔루션 아키텍처는 전처리, 필터 문 생성, 그리고 후처리 단계로 나뉩니다. 전처리는 컨텍스트 빌딩을 담당하며 유사도 검색을 위한 RAG 패턴을 포함합니다. 후처리 검증 단계는 LLM이 생성한 필터 문이 올바른지 확인하고, 최종 사용자에게 결과를 가시화합니다. 이 설계는 LLM의 개입과 더 결정론적인 전략의 균형을 전략적으로 맞춥니다.
전체 크기로 보려면 Enter를 누르거나 클릭하세요
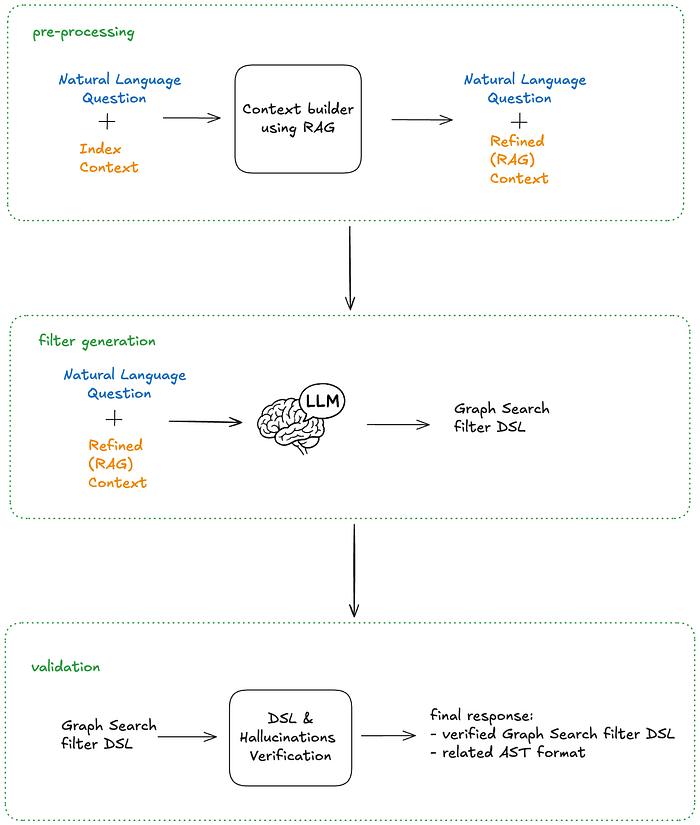
엔드투엔드 아키텍처
엔드투엔드 프로세스는 다음과 같습니다.
@mentions 문 포함)을 입력으로 받고, Graph Search 인덱스 컨텍스트를 함께 제공기존 Graph Search 인프라와 LLM의 강력함 및 유연성을 결합함으로써, 우리는 복잡한 필터 문과 사용자 의도 사이의 간극을 메웠습니다. 사용자가 우리의 언어(DSL)로 말해야 하던 단계에서, 시스템이 사용자의 언어를 이해하는 단계로 이동했습니다.
초기 사용자 과제는 성공적으로 해결했습니다. 하지만 다음 단계는 이 시스템을 포괄적이고 확장 가능한 플랫폼으로 전환하고, 실제 운영(production) 환경에서 성능을 엄격하게 평가하며, GraphQL-first 사용자 인터페이스를 지원하도록 역량을 확장하는 것입니다. 이러한 주제들과 그 밖의 내용은 이 시리즈의 후속 글에서 다룰 예정이니 계속 지켜봐 주세요.
또한 이 프로젝트에는 아직 할 일이 많습니다. 예를 들어 개체명 인식 및 추출(NER), 적절한 인덱스로 질문을 라우팅하기 위한 의도 탐지, 쿼리 리라이팅 등입니다. 이런 종류의 일에 관심이 있다면 연락 주세요! 바르샤바 오피스에서 채용 중이며, 여기에서 오픈 포지션을 확인할 수 있습니다.
특별히 감사드립니다: Alejandro Quesada, Yevgeniya Li, Dmytro Kyrii, Razvan-Gabriel Gatea, Orif Milod, Michal Krol, Jeff Balis, Charles Zhao, Shilpa Motukuri, Shervine Amidi, Alex Borysov, Mike Azar, Bernardo Gomez Palacio, Haoyun He, Eduardo Ramirez, Cynthia Xie.