Anthropic의 병렬 에이전트 기반 claude-code가 14일 만에 Rust로 C 컴파일러를 구축한 사례를 바탕으로, 커밋 히스토리 분석(코드 고고학)과 에이전트 수/시간에 따른 진행도 스케일링을 탐구한다.
Anthropic은 최근 데모에서 병렬 에이전트를 사용하는 claude-code가 Rust로 C 컴파일러를 맨바닥부터 단 14일 만에 만들 수 있음을 보여주었습니다. 헤드라인 수치는 시선을 끌기에 충분합니다 — 대략 20만 줄의 코드로, 리눅스 커널과 Doom, postgres 같은 다른 소프트웨어를 컴파일할 수 있습니다!
저는 Nicholas Carlini가 해당 블로그 글의 저자였기 때문에 즉시 주목했습니다. 그는 AI 레드팀(보안 평가)과 적대적 공격 분야에서 잘 알려져 있습니다. 그리고 Google DeepMind에서 그와 상호작용했던 경험으로, 그가 얼마나 뛰어난 연구자인지도 알고 있습니다.
보통 사람이 개발한 코드에서는 “왜” 어떤 선택이 이루어졌는지에 대한 많은 설계 결정이 구전 지식(tribal knowledge)으로 남기 때문에, 실제로는 “왜 이렇게 했지?”를 알아내기가 어렵습니다. 하지만 다행히도 이 코드가 개발된 방식 덕분에 드물게 가능한 일이 생겼습니다. 바로 코드 고고학(code archaeology) 입니다. 에이전트가 아이디어와 작업을 매우 꼼꼼하게 기록해 두었기 때문에, 시스템이 의사결정 하나하나, 레이어를 쌓아가며 어떻게 진화했는지를 분석할 수 있었습니다. 전체 커밋 히스토리를 분석하여 리포지토리를 생성하는 데 사용된 스캐폴딩(scaffolding)을 모델링할 수 있었고, 병렬 claude-code 에이전트에 대한 간단한 스케일링 법칙 분석도 할 수 있었습니다.
첫 번째 과제는 16개의 에이전트가 시간이 지나며 컴파일러 코드를 발전시키는 과정에서 어떻게 상호작용했는지 이해하는 것이었습니다. 이를 위해서는 시간이 흐르며 코드가 어떻게 진화했는지 시각화하는 것이 도움이 됩니다. 제가 한 첫 단계는 14일 개발 기간 전체에 대한 타임랩스 영상을 만들어 커밋 밀도, 활성 에이전트, 그리고 어떤 서브시스템에 집중했는지를 시각화한 것입니다. 영상은 여기에서 볼 수 있습니다:
타임랩스 영상: https://youtu.be/c9P89fe4WQk
전체 코드와 원본 인터랙티브 HTML도 https://github.com/pushpendre/claudes-c-compiler에서 확인할 수 있습니다.
이 시각화에서 흥미로운 점은, 처음 4시간 안에 LLM이 이미 첫 1만 줄의 코드를 작성했고 거의 전적으로 파서(parser)에만 집중했다는 것입니다. 체스에 비유하자면, LLM이 잘 알려진 이론을 초속도로(blitz) 훑고 지나가는 느낌이었습니다.
다만 이 영상은 대략 어떤 일이 일어났는지 감을 잡는 데는 좋지만, 아쉽게도 너무 빠르고 “정보 밀도”가 충분하지 않습니다. 아래 그래프는 훨씬 더 많은 정보를 전달합니다. 이 그래프는 시간의 함수로 다음을 플롯합니다: a) 서로 다른 테스트 스위트에 대한 테스트 통과율, b) 커밋 수와 코드 라인 수, c) 시간당 커밋 수. 또한 작업 목록이 수동으로 혹은 진행이 정체되어 자동으로 초기화(클리어)된 시점도 표시합니다.
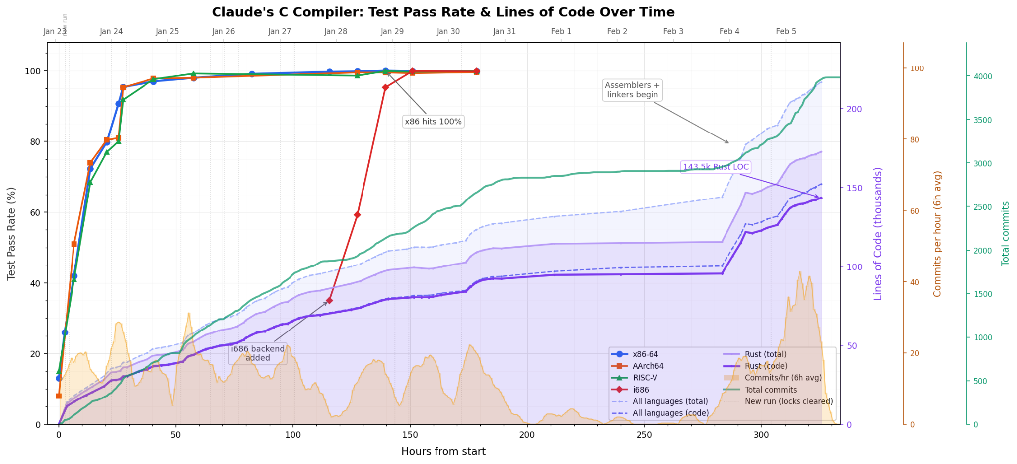
14일 개발 기간 동안의 테스트 통과율, 커밋 밀도, 코드 라인 수를 보여주는 코드 고고학 타임라인
단 24시간 만에 컴파일러가 이미 테스트의 95%를 통과하고 있음을 명확히 볼 수 있습니다. 2일 후에는 테스트에서의 진전이 빠르게 점근(asymptote)하는데, 흥미롭게도 50~100시간(즉 3~4일차) 사이에 코드가 훨씬 더 많이 추가됩니다. 알고 보니 에이전트가 리셋되고 컴파일러의 런타임 성능을 개선하는 작업이 부여되었던 것입니다. 100~150시간에는 주로 x86 백엔드를 올리는 작업이 진행되었습니다. 150~250시간은 리팩터링, 기술 부채 감소, 생성 코드 최적화에 집중했습니다. 마지막으로 250시간 이후에는 GCC의 어셈블러와 링커에 대한 의존성을 제거했습니다.
Anthropic은 컴파일러용 스캐폴딩을 공개하지 않았지만, 에이전트가 매우 꼼꼼히 기록을 남겼기 때문에 역공학이 가능합니다. 에이전트는 ideas/ 폴더를 제안 작업의 인입 큐로 유지했고, current_tasks/ 폴더에는 진행 중 작업이 나열되어 있었습니다. 이 정보만으로도 컴파일러를 생성했을 스캐폴딩을 재현해볼 수 있었습니다. 저희는 스캐폴딩 코드를 https://github.com/vizopsai/async_compiler_factory에 오픈소스로 공개했습니다.
비용을 낮추기 위해, 저희는 에이전트 1개로 60분만 실행하고 18개 테스트로 이루어진 작은 테스트 스위트로 진행 상황을 측정했습니다. 이 스캐폴딩을 이용해 “추론 시간(inference time)” 관점의 스케일링 법칙을 외삽(extrapolate)할 수 있습니다! 예를 들어 에이전트를 더 늘리면 테스트 통과율이 선형적으로 좋아지는지, 아니면 에이전트 수는 적게 유지하고 더 오래 작업하게 하는 편이 나은지 측정할 수 있습니다.
스캐폴딩을 시험하기 위해, 저는 1개 에이전트를 2시간 돌리는 경우와 2개 에이전트를 1시간 돌리는 경우의 효율을 비교하는 작은 테스트를 실행했고 결과는 아래와 같습니다. 두 실험 모두 fizzbuzz, 기본 재귀, 포인터, 배열, 구조체 등을 컴파일하는 16개 테스트를 통과하는 것이 목표였습니다. 재현된 스캐폴딩은 첫 20분 안에 이 테스트들을 통과할 수 있었고, 실제로는 1개 에이전트를 더 오래 돌린 실행이 더 많은 코드 라인을 생성했습니다. 따라서 병렬 에이전트의 효용에 대해서는 아직 결론을 내리기 어렵습니다.
이 두 번의 실행 비용은 총 $153이었습니다. 스캐폴딩, 생성된 코드, 분석 코드와 플롯도 모두 오픈소스로 공개되어 있으며 https://github.com/vizopsai/async_compiler_factory에서 확인할 수 있습니다.
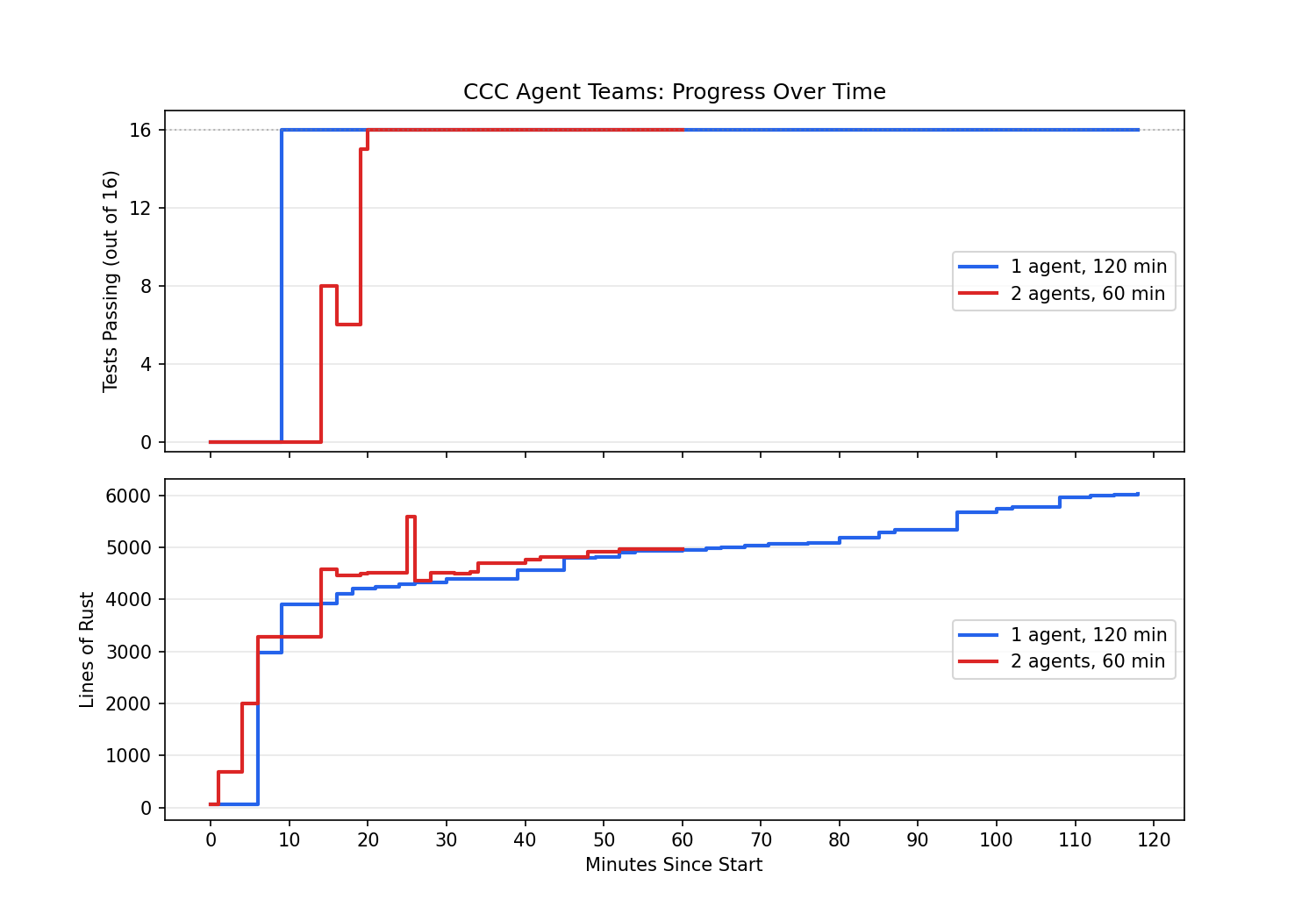
1개 에이전트 2시간 vs 2개 에이전트 1시간 비교 — 테스트 통과율과 코드 라인 수
소프트웨어 팩토리는 이미 도래했고, 앞으로도 계속될 것입니다. 최소한 Anthropic의 이번 데모는 205줄짜리 프롬프트와 매우 최소한의 스캐폴딩만으로 소프트웨어를 한 언어에서 다른 언어로 변환하는 “의미적 트랜스파일러(semantic transpiler)”로 볼 수 있습니다. 이는 또한 에이전트의 스케일링 법칙을 “액터 수 vs 단일 액터의 지속 시간”으로 비교하는 또 다른 방향을 열어줍니다.
제가 만든 스캐폴딩이 생성한 코드와 Anthropic의 C 컴파일러 커밋을 비교하면서 아주 분명해진 한 가지는 테스트 스위트와 초기 가이드의 중요성입니다. 원본 CCC 프로젝트에는 GCC torture suite에서 가져온 수천 개 테스트, 48개 실제 프로젝트(SQLite, Redis, FFmpeg, DOOM)에 대한 빌드 검증, 그리고 커널 컴파일 중 차분 테스트(differential testing)를 위한 GCC 오라클(oracle)이 있었습니다. 반면 저희 재현 실험은 16개의 수작업 테스트만 있었습니다. 에이전트는 16개를 모두 통과한 뒤, 남은 시간에는 새 기능을 추가하는 데 썼는데, 그 기능들이 실제로 동작하는지 알려주는 피드백 신호가 없었습니다. 테스트 스위트가 주말 해킹 수준을 리눅스 커널을 컴파일할 수 있는 컴파일러로 바꿔놓은 것입니다. 그리고 그 테스트 인프라를 구축하려면 깊은 도메인 전문성이 필요했는데, 에이전트 자체는 (적어도 아직은) 그런 전문성을 갖고 있지 않습니다.
병렬 스케일링에 대해서는, 저희 실험이 주의가 필요한 데이터 포인트를 제공합니다. 1-에이전트 실행은 9분에 16/16 테스트에 도달했습니다. 반면 2-에이전트 실행은 20분이 걸렸습니다 — 두 배 이상 오래 걸린 셈입니다 — 이유는 에이전트들이 서로 간섭했기 때문입니다. 한 에이전트가 다른 에이전트가 막 만든 AArch64 코드 생성기를 다시 작성해버려, 통과율이 8에서 6으로 일시적으로 떨어졌다가 다시 회복했습니다. 원래 CCC 프로젝트에서도 같은 패턴이 보였습니다. 16개 에이전트를 사용할 수 있었음에도, 첫 한 시간의 커밋은 사실상 단일 스레드였는데, 빈 리포지토리에서 컴파일러를 부트스트랩하는 과정은 본질적으로 직렬적(serial)이기 때문입니다. 병렬성은 테스트 스위트가 수백 개의 서로 독립적인 실패 테스트를 제공하여 이를 에이전트들에 분배할 수 있게 되었을 때에야 유용해졌습니다. 스케일링 법칙은 단순히 agents × time = progress가 아닙니다. 오히려 agents × independent_tasks_available = progress에 가깝고, 독립 작업의 수는 스캐폴딩이 아니라 테스트 인프라의 함수입니다.