Doug Lea가 설계한 C용 메모리 할당기(dlmalloc)의 목표, 알고리즘, 구현 상의 고려 사항을 설명한다.
by Doug Lea
[이 글의 독일어 번안 및 번역본이 unix/mail 1996년 12월 호에 실려 있다. 이 글은 현재는 구버전이며, 최신 버전의 malloc 세부 사항을 반영하지 않는다.]
메모리 할당기는 인프라 소프트웨어 공학에서 흥미로운 사례 연구가 된다. 나는 1987년에 하나를 작성하기 시작했고, (많은 자원 봉사 기여자의 도움을 받아) 그 이후 계속 유지·발전시켜 왔다. 이 할당기는 표준 C 루틴인 malloc(), free(), realloc()의 구현을 제공하며, 몇 가지 보조 유틸리티 루틴도 포함한다. 이 할당기는 특별한 이름을 가진 적은 없다. 대부분의 사람들은 그냥 Doug Lea의 malloc 또는 줄여서 dlmalloc 이라고 부른다.
이 할당기의 코드는 퍼블릭 도메인으로 공개되어 있으며(ftp://g.oswego.edu/pub/misc/malloc.c 에서 구할 수 있다), 널리 사용되고 있는 것으로 보인다. 몇몇 리눅스 버전에서는 기본(native) malloc 구현으로 사용되며, 여러 널리 사용되는 소프트웨어 패키지에 컴파일되어(네이티브 malloc을 대체하면서) 들어가 있고, 다양한 PC 환경과 임베디드 시스템에서도 사용되어 왔으며, 내가 알지 못하는 많은 곳들에서도 사용되고 있을 것이다.
나는 동적 메모리 할당에 거의 전적으로 의존하는 C++ 프로그램들을 작성한 후 첫 버전의 할당기를 만들게 되었다. 그런 프로그램들이 내가 예상한 것보다 훨씬 느리게 실행되거나 전체 메모리 소비가 훨씬 많다는 사실을 발견했다. 이는 내가 사용하던 시스템(주로 당시의 SunOS와 BSD)에서 제공하는 메모리 할당기의 특성 때문이었다. 이를 상쇄하기 위해, 처음에는 C++에서 여러 특수 목적 할당기를 작성했는데, 보통은 여러 클래스에 대해
operator
new를 오버로드하는 방식이었다. 이들 중 일부는 C++ 할당 기법에 관한 논문에서 설명되었고, 이는 1989년 C++ Report 에 실린 기사 Some storage allocation techniques for container classes 로 각색되었다.
그러나 곧, 동적으로 할당되고 많이 사용되는 새로운 클래스마다 별도 할당기를 만드는 전략은, 내가 당시 작성하던 범용 프로그래밍 지원 클래스들을 구축하는 데 별로 좋지 않다는 것을 깨달았다. (1986년부터 1991년까지, 나는 GNU C++ 라이브러리인 libg++의 주요 작성자였다.) 보다 폭넓은 해결책이 필요했다. 즉, 일반적인 C++ 및 C 부하 하에서 충분히 좋은 할당기를 작성하여, 프로그래머들이 아주 특별한 상황이 아닌 한 굳이 특수 목적 할당기를 작성할 유인이 없도록 하는 것이었다.
이 글에서는 이 할당기의 주요 설계 목표, 알고리즘, 구현상의 고려 사항 중 일부를 설명한다. 더 자세한 문서는 코드 배포본과 함께 제공된다.
좋은 메모리 할당기는 여러 목표 사이에서 균형을 잡아야 한다.
malloc(), free(), realloc 루틴은 평균적인 경우 가능한 한 빨라야 한다.%define 등) 혹은 동적으로(mallopt 와 같은 제어 명령) 제어할 수 있어야 한다.Paul Wilson과 동료들은 이러한 목표를 더 자세히 논의한 할당 기법에 관한 훌륭한 개관 논문을 집필했다. 참고: Paul R. Wilson, Mark S. Johnstone, Michael Neely, David Boles, "Dynamic Storage Allocation: A Survey and Critical Review", International Workshop on Memory Management, 1995년 9월 (또한 ftp로도 이용 가능). (단, 그들이 설명한 내 할당기 버전은 최신 버전이 아님 에 유의하라.)
그들이 논의하듯, 낭비(일반적으로는 단편화로 인한)를 최소화하여 공간을 최소화하는 것이 어떤 할당기에서든 가장 우선적인 목표가 되어야 한다.
극단적인 예를 들어 보자. 가능한 가장 빠른 malloc() 구현 중 하나는 항상 시스템에서 사용 가능한 다음 연속 메모리 위치를 할당하며, 이에 상응하는 가장 빠른 free() 구현은 아무 일도 하지 않는 것이다. 그러나 이런 구현은 거의 항상 용납될 수 없다. 사용하지 않는 공간을 절대 회수하지 않으므로 프로그램이 매우 빨리 메모리를 소진하게 된다. 실제로 사용되는 일부 할당기에서 특정 부하 하에 나타나는 낭비는 이 극단에 가깝기도 하다. Wilson이 지적하듯, 낭비는 금전적 비용으로 측정할 수도 있다. 전 세계적으로 보았을 때, 형편없는 할당 방식은 메모리 칩 비용 면에서 수십억 달러에 달하는 손실을 초래할 수도 있다.
시간–공간 이슈가 지배적이지만, 트레이드오프와 타협의 집합은 사실상 끝이 없다. 그 예를 몇 가지만 들면 다음과 같다.
free된 메모리에 대해 realloc을 허용했다. 1993년까지 나는 호환성을 위해 이 동작을 허용했다. (그러나 이 "기능"이 제거되었을 때 아무도 불평하지 않았다.)이와 같은 절충의 집합 중 어느 것도 완벽할 수는 없다. 그러나 수년 동안, 이 할당기는 대다수 사용자가 수용할 수 있는 트레이드오프를 취하도록 진화해 왔다. malloc의 지속적 진화에 영향을 주는 주요 요인은 다음과 같다.
malloc 알고리즘의 두 핵심 요소는 초기 버전부터 변하지 않았다.
메모리 청크는 그 앞과 뒤에 크기 정보를 담고 있는 필드를 함께 지닌다. 이를 통해 두 가지 중요한 기능이 가능해진다.

초기 버전은 경계 태그를 정확히 이런 방식으로 구현했다. 최근 버전에서는 프로그램이 사용 중인 청크에 대해서는 후미(trailer) 필드를 생략한다. 이것 역시 사소한 트레이드오프다. 청크가 활성 상태인 동안에는 이 필드들이 전혀 사용되지 않으므로 존재할 필요가 없다. 이를 제거하면 오버헤드와 낭비가 줄어든다. 그러나 이러한 필드가 없으면, 원래 알려진 값을 가져야 할 필드를 사용자가 실수로 덮어썼는지를 검사할 수 없게 되므로, 오류 탐지 능력이 약간 떨어진다.
사용 가능한 청크는 크기별로 묶어 bin에 보관한다. 놀랄 만큼 많은 고정 폭 bin(128개)이 있으며, 대략 로그 단위 간격으로 크기가 나뉘어 있다. 512바이트 미만 크기 bin은 각각 정확히 하나의 크기만을 담는데, 이들은 8바이트 간격으로 배치되어 있어 8바이트 정렬을 간단히 강제할 수 있다. 사용 가능한 청크 검색은 가장 작은 것부터 시작하는 best-fit 순서로 처리된다. Wilson 등이 보여 주었듯, 다양한 변형과 근사치가 존재하는 best-fit 방식은, first-fit 같은 다른 일반 접근법과 비교해 실제 부하에서 단편화를 가장 적게 일으키는 경향이 있다.
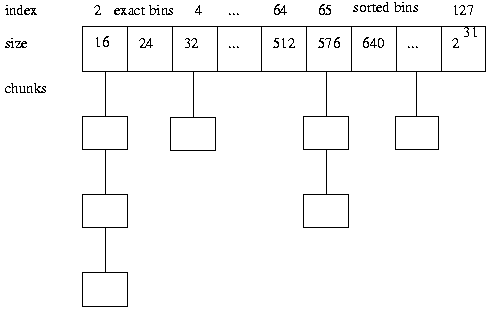
1995년에 공개된 버전까지는, bin 내에서 청크가 정렬되지 않았기 때문에, best-fit 전략은 근사적인 수준에 그쳤다. 이후 버전에서는 bin 내부의 청크를 크기 순으로 정렬하고, 동일 크기 간에는 가장 오래된 것부터 사용하는 규칙을 적용한다. (관찰 결과, 이 정도의 미미한 시간 투자가 나쁜 경우를 피하는 데 가치가 있다는 사실이 드러난 후 이렇게 변경되었다.)
따라서 이 알고리즘의 일반적인 분류는 best-first with coalescing 이라 할 수 있다. 즉, 반환된 청크는 인접한 것들과 병합되며, 크기 순으로 검색되는 bin에 보관된다.
이 접근법은 청크당 고정된 북키핑 오버헤드를 야기한다. 크기 정보와 bin 연결 정보가 모두 사용 가능한 각 청크에 저장되어야 하기 때문에, 32비트 포인터 시스템에서 할당 가능한 최소 청크는 16바이트이고, 64비트 포인터 시스템에서는 24바이트이다. 이러한 최소 크기는 대부분 사람들이 기대하는 것보다 크다. 예를 들어, 아주 작은 연결 리스트 노드를 많이 할당하는 애플리케이션에서는 상당한 낭비를 초래할 수 있다. 그러나 16바이트 최소 크기는, 8바이트 정렬을 요구하고 malloc 북키핑 오버헤드가 조금이라도 존재하는 어떤 시스템에서든 나타나는 특성이기도 하다.
이 기본 알고리즘은 매우 빠르게 만들 수 있다. 비록 best-fit를 찾기 위한 검색 메커니즘에 기반하지만, 인덱싱 기법 사용, 특수 경우 활용, 신중한 코딩을 통해, 평균적으로는 (물론 머신과 할당 패턴에 따라 다르지만) 수십 개 정도의 명령만으로 충분하다.
경계 태그를 통한 병합(coalescing)과 binning을 통한 best-fit가 알고리즘의 주요 아이디어이지만, 추가적인 고려 사항은 여러 휴리스틱 개선으로 이어진다. 여기에는 지역성 보존, "황무지"(wilderness) 보존, 메모리 매핑, 캐싱 등이 포함된다.
프로그램에서 비슷한 시점에 할당된 청크들은 비슷한 참조 패턴과 공존 생애를 갖는 경향이 있다. 지역성을 유지하면 페이지 폴트와 캐시 미스를 줄일 수 있고, 이는 현대 프로세서에서 성능에 극적인 영향을 줄 수 있다. 만약 지역성만이 유일한 목표라면, 할당기는 각 연속 청크를 가능한 한 이전 청크에 가깝게 할당하는 전략을 취할 것이다. 그러나 이러한 nearest-fit(종종 next-fit 으로 근사됨) 전략은 매우 나쁜 단편화를 초래할 수 있다.
현재 버전의 malloc에서는, 지역성이 다른 목표들과 가장 덜 충돌하는 제한된 상황에서만 next-fit의 변형을 사용한다. 즉, 정확히 원하는 크기의 청크가 없으면, 가장 최근에 잘려 나간(split-off) 공간이 충분히 크다면 이를 (다시 분할하여) 사용하고, 그렇지 않으면 best-fit를 사용한다. 이 제한된 사용 방식은, 사용할 수 있는 완전히 정상적인 청크가 할당되지 못하는 상황을 제거하므로, 적어도 이런 형태의 단편화를 없앤다. 그리고 이 형태의 next-fit는 best-fit bin 검색보다 더 빠르므로, 평균적인 malloc 속도를 높여 준다.
"황무지" 청크(이 용어는 Kiem-Phong Vo가 붙였다)는 시스템에서 할당된 최상위 주소 경계에 있는 공간을 의미한다. 가장자리에 있기 때문에, (물론 시스템의 모든 메모리가 고갈되어 sbrk가 실패하지 않는 한) 이 청크만이 임의로(sbrk를 통해, Unix에서) 더 크게 확장될 수 있다.
황무지 청크를 다루는 한 가지 방법은 이를 다른 청크와 거의 동일하게 처리하는 것이다. (이 방식은 1994년까지 대부분의 malloc 버전에서 사용되었다.) 이렇게 하면 구현이 단순해지고 빨라지지만, 주의를 기울이지 않으면 최악의 경우 매우 나쁜 공간 특성으로 이어질 수 있다. 예를 들어, 다른 사용 가능한 청크가 존재함에도 황무지 청크를 사용하면, 나중에 사실상 피할 수 있었던 sbrk 호출이 발생할 가능성이 커진다.
현재 사용되는 더 나은 전략은, 황무지 청크를 다른 모든 청크보다 "더 큰" 것으로 취급하는 것이다. 시스템 제약 범위 내에서는 실제로 그렇게 만들 수 있으며, best-first 검색에서 그렇게 사용한다. 이로 인해, 다른 청크가 전혀 없을 때에만 황무지 청크가 사용되므로, 피할 수 있는 단편화를 더 줄일 수 있다.
sbrk를 통해 일반 목적 할당 영역을 확장하는 것 외에, 대부분의 Unix 버전은 프로그램이 사용할 수 있도록 별도의 불연속 메모리 영역을 할당하는 mmap 같은 시스템 호출을 지원한다. 이는 malloc이 메모리 요청을 만족시키기 위한 두 번째 옵션을 제공한다. 매핑된(mmap된) 청크를 요청·반환하는 것은, 해제된 메모리 매핑이 관리해야 할 "구멍"을 만들지 않으므로, 이후의 단편화를 줄여 줄 수 있다. 그러나 mmap에는 기본적인 제약과 오버헤드가 있으므로, 매우 제한된 상황에서만 사용할 가치가 있다. 예를 들어, 모든 현재 시스템에서 매핑 영역은 페이지 단위로 정렬되어야 한다. 또한 mmap과 mfree 호출은 기존 메모리 청크에서 공간을 떼어 쓰는 것보다 훨씬 느리다.
이러한 이유로, 현재 버전의 malloc은 다음 두 조건을 모두 만족하는 경우에만 mmap에 의존한다. (1) 요청 크기가 (동적으로 조정 가능한) 임계값보다 클 것(현재 기본값은 1MB), (2) 요청한 공간이 기존 아레나(arena)에 이미 존재하지 않아 sbrk를 통해 새로 확보해야 할 것.
mmap이 대부분의 프로그램에서 항상 적용 가능한 것은 아니기 때문에, 현재 버전의 malloc은 또한 기본 아레나를 트리밍(trimming) 하는 기능도 지원한다. 이는 사용하지 않는 공간을 시스템에 돌려보낸다는 점에서 메모리 매핑과 비슷한 효과를 가진다. 수명이 긴 프로그램이 잠깐 동안 대량의 메모리를 할당했다가, 그 이후로는 더 적은 양의 메모리를 요구하는 긴 구간이 이어지는 경우, 사용하지 않는 황무지 청크의 일부를 시스템에 돌려보내 줌으로써 전체 시스템 성능을 개선할 수 있다. (거의 모든 Unix 버전에서, sbrk에 음수 인자를 주어 이 효과를 얻을 수 있다.) 공간을 해제하면, 기본 운영체제가 스왑 공간 요구를 줄이고 메모리 매핑 테이블을 재사용할 수 있다. 그러나 mmap과 마찬가지로, 이 호출 자체도 비용이 크므로, 끝부분의 미사용 메모리가 조정 가능한 임계값을 초과할 때에만 시도한다.
가장 직관적인 기본 알고리즘 버전에서는, 각 해제된 청크가 즉시 이웃 청크들과 병합되어 가능한 한 큰 미사용 청크를 이룬다. 마찬가지로, 청크는 오직 명시적으로 요청되었을 때만(더 큰 청크를 분할하여) 생성된다.
청크를 분할(splitting)하고 병합(coalescing)하는 연산은 시간이 든다. 이 시간 오버헤드는 두 가지 캐싱 전략(또는 둘 모두)을 사용하여 때때로 피할 수 있다.
할당기의 기본 자료구조는 malloc, free, realloc 어느 쪽에서든 언제든 병합을 허용하므로, 이에 대응하는 캐싱 휴리스틱을 적용하기가 쉽다.
캐싱의 효과는 분할·병합·검색 비용과 캐시된 청크를 추적하는 데 필요한 작업량의 상대적 크기에 분명하게 의존한다. 또한 효과는, 캐시할지 병합할지를 결정하는 데 사용하는 정책에 덜 분명하게 의존한다.
캐싱은 소수의 크기만을 계속 할당·해제하는 프로그램에서는 좋은 생각일 수 있다. 예를 들어, 많은 트리 노드를 할당·해제하는 프로그램을 작성한다면, 노드를 캐시하는 것이 이득일 수 있고, 이를 빠르게 구현하는 방법을 알고 있다고 가정하자. 그러나 프로그램에 대한 지식이 없다면, malloc은 캐시된 작은 청크들을 병합해 더 큰 요청을 만족시키는 것이 좋은지, 아니면 그 더 큰 요청을 다른 곳에서 가져와야 하는지 알 수 없다. 또 할당기가 이 문제에 대해 좀 더 정교한 추정을 하기란 어렵다. 예를 들어, 병합을 통해 얻을 수 있는 전체 연속 공간 크기를 파악하는 비용은, 그냥 병합해 놓고 나중에 다시 분할하는 비용과 거의 같다.
이전 버전의 할당기는 캐싱에 대해 그럭저럭 괜찮은 추정을 해 주는 몇 가지 검색 순서 휴리스틱을 사용했지만, 간혹 최악의 경우에는 나쁜 결과를 내기도 했다. 그러나 시간이 흐르면서, 이러한 휴리스틱은 실제 부하에서는 점점 덜 효과적인 것으로 보인다. 아마도 malloc에 크게 의존하는 실제 프로그램들이 점점 더 다양한 크기의 청크를 사용하는 경향이 있기 때문일 것이다. 예를 들어, C++ 프로그램의 경우, 이는 프로그램이 사용하는 클래스 수가 증가하는 추세와 관련 있을 것이다. 서로 다른 클래스는 서로 다른 크기를 갖는 경향이 있다.
[주의: 더 최근 버전의 malloc은 캐싱을 수행하지만, 아주 작은 청크에 대해서만 그렇다.]
일부 애플리케이션에서는 매우 바람직하지만 이 할당기는 구현하지 않은 캐싱 방식이 하나 남아 있다. 바로 아주 작은 청크에 대한 룩어사이드이다. 앞서 언급했듯, 기본 알고리즘은 매우 작은 요청에 대해서도 상당히 낭비적인 최소 청크 크기를 강제한다. 예를 들어, 4바이트 포인터를 사용하는 시스템에서, 두 개의 포인터만 담는 연결 리스트 노드(즉, 8바이트만 필요)를 할당한다고 하자. 최소 청크 크기가 16바이트이므로, 리스트 노드만을 할당하는 사용자 프로그램은 100% 오버헤드를 떠안게 된다.
이 문제를, 이식 가능한 정렬을 유지하면서 제거하려면, 할당기가 어떤 오버헤드도 부과하지 않아야 한다. 이를 구현할 수 있는 기법은 존재한다. 예를 들어, 주소 비교를 통해 청크가 더 큰 집합 공간에 속하는지 확인할 수 있다. 그러나 이렇게 하면 상당한 비용이 들 수 있으며, 이 할당기에서 그 비용은 받아들일 수 없을 정도다. 청크는 주소 기준으로 별도로 추적되지 않으므로, 임의로 제한하지 않는 한, 검사는 메모리를 무작위로 뒤지는 수준의 탐색으로 변할 수 있다. 또한, 작은 청크를 언제, 어떻게 병합할지 제어하는 하나 이상의 정책을 채택해야 한다.
이러한 문제와 제약으로 인해, 프로그래머가 자신의 특수 목적 메모리 관리 루틴을 일상적으로 작성해야 하는 몇 안 되는 상황 유형이 생긴다. 예를 들어 C++에서는 operator new()를 오버로드하는 식으로 구현할 수 있다. 매우 작은 청크를 대량으로, 그리고 대략적인 개수를 알고 사용하는 프로그램은, 매우 단순한 할당기를 직접 만드는 것이 유리할 수 있다. 예를 들어, 고정 배열에서 임베디드 freelist를 이용해 청크를 할당하고, 배열이 소진되면 백업 용도로 malloc에 의존하도록 할 수 있다. 좀 더 유연한 방식으로는, GNU gcc와 libg++에 포함된 C 또는 C++ 버전의 obstack 을 기반으로 구현할 수 있다.
마지막 수정: Tue Apr 4 06:57:17 EDT 2000