수학적 형식주의를 최대한 배제하고, 다양한 구체적 예로 모나드를 실용적으로 이해하는 입문서. Maybe/Either/리스트/ST/Identity/Free/IO 모나드와 do 표기법, 그리고 모나드를 효과적으로 학습·사용하는 방법을 다룹니다.

이 글은 전광석화 같은 속도로 모나드를 쓸 수 있게 되고 싶은 사람을 위한, 진지한 모나드 입문입니다. 수학 냄새 나는 얘기는 가능한 한 피했고, 함수형 언어에 대한 선행 지식이 없어도 읽을 수 있도록 썼습니다. 대상 독자는 다음과 같습니다.
덧붙여, 설명 보조로 왜인지 포켓몬이 등장하지만, 이 글을 읽는 데 포켓몬을 플레이한 경험은 전혀 필요 없습니다. 포켓몬 요소를 전부 무시해도 이해할 수 있도록 되어 있습니다.
삽화가 있으면 더 즐겁겠다 싶어, 포켓몬 다이스키 색칠놀이를 써서 모두가 좋아하는 피카츄를 그려 봤습니다. 꽤 귀엽게 그려졌다고 생각합니다.
모나드는 어렵지도, 복잡하지도 않습니다. 단 두 개의 함수만으로 설명이 끝나기 때문입니다. 다만 모나드는 매우 추상적인 개념이어서, 접근을 잘못하면 감을 잡기 어렵고 학습에 애를 먹기 쉽습니다. 특히 다음과 같은 돌아가는 학습을 하는 분이 많은데, 이런 방식은 피합시다.
모나드에만 국한되지 않지만, 추상적 개념을 배우는 요령은 구체例를 많이 학습하는 것입니다. ‘포켓몬’이 ‘피카츄’나 ‘레트라’ 같은 구체적 포켓몬들의 총칭이듯, 모나드란 Maybe 모나드나 List 모나드 같은 모나드의 구체例, 즉 인스턴스들의 총칭입니다. 모나드를 이해하려면 무엇보다 모나드 인스턴스를 많이 알고, 각각을 실제로 쓸 수 있게 되는 것이 중요합니다. 구체例를 여러 개 알다 보면, 그 공통점으로서 모나드가 무엇인지가 보이기 시작합니다.
“모나드를 공부해 봤지만 잘 모르겠다”는 사람이 있다면, 모나드의 구체例 다섯 가지를 말해 보라고 해 보세요. 즉시 다섯 개를 말하지 못한다면, ‘모나드를 배운 적이 있다’고 말하기도 애매합니다. 개별 모나드를 바로 떠올리지 못한다면, 모나드 전체에 대한 이해는 요원합니다. ‘포켓몬 이름 다섯 개 말해 봐’라고 했는데 대답하지 못한다면, ‘포켓몬을 해 본 적이 있다’고 말할 수 있을까요? 똑같은 얘기입니다.
그럼 먼저 모나드 도감을 휙휙 넘기며, 다양한 모나드를 빨리 맛만 보겠습니다.
프로그래밍에서는 연산이 항상 성공하는 것은 아닙니다. 예를 들어 리스트 요소 참조에서 인덱스가 범위 내면 성공하여 그 요소를 돌려주지만, 아니면 실패가 됩니다. 혹은 문자열 내에서 다른 문자열의 위치를 찾는 indexOf도, 찾으면 인덱스를 돌려주지만 찾지 못하면 실패입니다.
여기서는 리스트 xs의 i번째 요소 접근을, 연산자 !!를 써서 xs !! i처럼 쓰기로 하겠습니다. 또 문자열 y에서 문자열 x의 위치를 찾는 연산을 indexOf x y라고 쓰겠습니다. 이런 실패할 수 있는 계산이 여러 번 이어질 때, Haskell스러운 언어에서는 예를 들어 다음처럼 쓸 수 있습니다.
x <- ["Space", "World", "Universe"] !! 1
y <- indexOf x "Hello, World"
pure ("String \"" ++ x ++ "\" at " ++ show y)
이 프로그램은 다음 순서로 계산이 진행됩니다.
["Space", "World", "Universe"] !! 1에서 리스트의 1번째 요소를 참조하고, 그 결과 값 World가 변수 x에 바인딩됩니다.indexOf x "Hello, World"가 계산되어, 결과 값 7이 변수 y에 바인딩됩니다."String \"" ++ x ++ "\" at " ++ show y가 계산되어, 이것이 pure 함수에 건네집니다.그냥 위에서 아래로 순서대로 계산된 것뿐이지만, 이 일련의 계산 도중 실패가 일어나면 더 흥미로운 동작이 나옵니다. 예컨대 2행에서 "World"를 검색할 때, 도무지 "World"가 포함되어 있지 않은 문자열을 주어 봅시다.
x <- ["Space", "World", "Universe"] !! 1
y <- indexOf x "----"
pure ("String \"" ++ x ++ "\" at " ++ show y)
이때 계산이 indexOf x "----"에 도달하면, 그 계산은 실패하고 그 자리에서 일련의 계산이 중단되며, 호출자에게 실패했다는 정보만 전달됩니다. 일련의 계산이 실패하는 순간 계산을 중지하고 호출자로 되돌아가는 것입니다. 이는 단순한 크래시가 아니라, 호출자는 계산이 끝까지 성공했는지 실패했는지 조건 분기해 확인하고 안전하게 프로그램 실행을 계속할 수 있습니다.
또한 Nothing이라는 값을 사용하면 그 지점에서 확실히 계산을 실패시킬 수 있습니다. 다음 코드는 반드시 2행에서 계산이 실패하고, 거기서 중단되어 호출자로 돌아갑니다.
x <- ["Space", "World", "Universe"] !! 1
Nothing
pure ("String \"" ++ x ++ "\" at " ++ show y)
그런데 마지막 줄에서 pure라는 함수를 호출하고 있는데, 이는 반드시 성공하는 ‘실패할 수 있는 계산’을 표현하기 위한 것입니다. x + y + z 같은 평범한 계산을 pure에 넘김으로써, !!나 indexOf 같은 연산과 같은 종류의 계산으로 취급될 수 있게 변환하는 것입니다.
즉 이 일련의 ‘실패할 수 있는 계산’은 단순한 예외 처리 장치처럼 동작합니다. 도중에 실패하면 그 자리에서 중지되고, 호출자에서는 계산이 끝까지 성공했는지, 아니면 도중에 실패했는지를 알 수 있습니다. 끝까지 성공했다면 결과 값도 알 수 있습니다. 중간에 Nothing을 끼우면 마치 throw로 예외를 던지는 것처럼 도중에 계산을 중단할 수 있습니다. Maybe 모나드란 이런 구문을 실현해 주는 것입니다. Maybe 모나드는 모나드를 배우기 시작할 때 대체로 가장 먼저 다루는 단순한 모나드로, 이야기 초반에 모두가 마주치는, 최약 클래스지만 최약은 아닌 포켓몬, 꼬렛 같은 존재입니다(억지).
여기서는 더 이상 Maybe 모나드의 세부로 들어가지 않겠습니다. 여기서 확인하고 싶은 것은, Maybe 모나드의 동작이나 구현이 아니라 다음 두 가지입니다.
결과 <- 어떤 같은 종류의 계산이라는 문들의 연속으로 일련의 계산을 표현할 수 있다pure 함수로 임의의 식을 그 계산에 끼워 넣을 수 있다Maybe 모나드는 실패로 계산이 중단되어도, 호출자가 왜 실패했는지 알 수 없습니다. 실패 이유를 호출자에게 제대로 전달하고 싶다면 다음의 Either 모나드를 씁니다.
JSON 오브젝트의 프로퍼티를 읽는 readIntProp, readStringProp, readBooleanProp 같은 함수가 있다고 합시다. 이 함수들은, 지정한 이름의 프로퍼티가 없거나, 읽으려는 프로퍼티의 타입이 일치하지 않으면 실패합니다. 코드는 예를 들어 다음과 같습니다.
x <- readIntProp "x" json
y <- readStringProp "y" json
z <- readBooleanProp "z" json
pure { x: x, y: y, z: z }
이 코드도 위에서 아래로 한 줄씩 실행되고, 도중에 실패가 없으면 끝까지 계산이 진행되어 마지막 줄의 값이 최종 결과가 됩니다. 실패한 경우에는 어느 프로퍼티 읽기가 실패했는지가 호출자에게 전달됩니다.
Maybe 모나드에서는 Nothing으로 명시적으로 실패시킬 수 있었는데, Either 모나드에서도 마찬가지로 Left로 계산을 중단할 수 있습니다. 다만 Left는 함수 형태이며, 인수로 받은 데이터를 호출자에게 전달할 수 있습니다. 이 점이 Maybe 모나드와의 차이입니다.
x <- readIntProp "x" json
y <- Left "Some error" -- 계산은 여기서 중단되고, "Some error"라는 예외 정보가 호출자에게 전달됨
z <- readIntProp "z" json
pure { x: x, y: y, z: z }
즉 Either 모나드는 Maybe 모나드와 같은 기능을 갖출 뿐 아니라, 그 자연스러운 확장입니다. 포켓몬으로 치면 꼬렛의 진화형인 **레트라**라고 할 수 있겠죠. Haskell/PureScript에는 try-catch 같은 예외 처리 전용 구문이 없지만, 바로 throw와 똑같이 에러 오브젝트와 함께 도중에 빠져나오는 동작을 이 Either 모나드로 실현할 수 있습니다.
여기서도 중요한 것은 Either 모나드의 구체 동작이 아니라, 이 모나드 또한 ‘결과 <- 계산이라는 문들의 연속으로 계산을 표현할 수 있다’, ‘pure 함수로 임의의 값을 그 계산에 넣을 수 있다’는 공통점을 가진다는 사실입니다.
리스트 모나드는 각 계산이 복수 개의 결과를 가질 수 있는 계산을 표현할 수 있는 모나드입니다. 이름대로 각 줄의 계산이 리스트인 식이 되고, 이 리스트의 각 요소가 그 계산의 결과라고 생각합니다. 예를 들어 다음과 같이 쓸 수 있습니다.
x <- [1, 2, 3]
pure (x * x)
이 코드는 다음과 같이 동작합니다.
[1, 2, 3]의 첫 값 1이 x에 바인딩된다.x * x = 1 * 1 = 1이 계산된다.2가 x에 바인딩된다.x * x = 2 * 2 = 4가 계산된다.3이 x에 바인딩된다.x * x = 3 * 3 = 9가 계산된다.이 계산에서는 이상하게도 마지막 줄이 세 번 실행되고, 그 모든 결과가 리스트로 모여 반환됩니다. 줄이 더 늘어나면, 각 줄의 모든 요소에 대해 망라적으로 계산이 이루어집니다.
x <- [1, 2, 3]
y <- [7, 8]
pure (x + y)
예컨대 이 코드는 1행에 3개의 값, 2행에 2개의 값이 있으므로, 마지막 줄은 2 * 3 = 6번 계산되어 [8, 9, 9, 10, 10, 11]이 호출자에게 돌아옵니다.
이 모나드의 특징은, 각 줄의 계산이 반드시 위에서 아래로 한 번씩만 진행되는 것이 아니라는 점입니다. 각 계산이 여러 값을 반환할 수 있고, 그 모든 경우에 대해 망라적으로 계산이 수행됩니다. 이는 마치 연속 펀치로 한 턴에 여러 번 공격하는 **캥카**와 같습니다.
Maybe 모나드와 Either 모나드는 도중에 중단될 수 있었고, 리스트 모나드는 같은 줄을 여러 번 계산할 수 있습니다. 모나드가 어떤 순서로 계산을 진행하는지는 모나드마다 완전히 다릅니다. 하지만 여기서 중요한 것은 공통점이었습니다. 리스트 모나드가 이런 이상한 순서로 계산되더라도, ‘결과 <- 계산이라는 문들의 연속으로 일련의 계산을 표현할 수 있다’, ‘pure 함수로 값을 계산에 끼워 넣을 수 있다’는 두 점은 변하지 않습니다. 이번에 중요한 건 바로 그것입니다.
Haskell 같은 언어는 변수 재할당 금지라는 얘기를 들어 보셨을 수 있지만, ST 모나드를 쓰면 모든 오브젝트 변경 금지, 변수 재할당 금지라는 순수한 계산 안에서조차 변경 가능한 상태를 만들어 계산할 수 있습니다.
모나드 계산 안에서는, 모나드 종류에 따라 고유 기능을 쓸 수 있습니다. Maybe 모나드에서는 Nothing이, Either 모나드에서는 Left가 고유 연산으로 쓰였습니다. 리스트 모나드에서는 [1, 2, 3] 같은 리스트 리터럴을 그대로 쓸 수 있었고, 결과가 리스트인 식은 무엇이든 계산에 넣을 수 있습니다. 그리고 ST 모나드에서는 newSTRef, modifySTRef, readSTRef 같은 다양한 함수를 쓸 수 있습니다. newSTRef는 변경 가능한 영역을 만드는 함수로, C++의 new 연산자로 힙을 확보하는 것과 비슷합니다. modifySTRef는 이 영역의 값을 원하는 대로 바꿀 수 있습니다. readSTRef는 그 영역의 값을 읽어올 수 있습니다.
예를 들어 리스트 xs의 합을 ST 모나드로 구하면 다음과 같습니다.
n <- newSTRef 0
for xs $ \x ->
modifySTRef n (_ + x)
readSTRef n
여기서 영역 n에 저장된 값은, for 반복 안에서 사실상 반복적으로 변경된다고 볼 수 있습니다. 겉으로는 변경 불가 같은 불변성이 있지만 내부에서는 자유롭게 변경 가능한 오브젝트를 제공하는 ST 모나드는, 마치 바깥은 단단해서 이가 안 들어가지만 속은 부드러운 **셀러**와 꼭 닮았습니다(억지).
Identity 모나드는 세계에서 가장 약하고 초라한 모나드입니다. 말이 심하지만, 이 Identity 모나드는 pure 말고는 할 수 있는 게 거의 없습니다. **모나드계의 잉어킹**이 바로 Identity 모나드입니다. Maybe처럼 Nothing으로 도중에 빠져나올 수도 없고, 리스트 모나드처럼 여러 번 반복 계산하거나, ST처럼 상태를 바꾸어 갈 수도 없습니다. pure로 계산에 끼워 넣을 수는 있어도, 그게 그대로 <-로 나올 뿐입니다. 정말 그 정도밖에 못 합니다.
x <- pure 10
y <- pure 20
z <- pure 30
pure (x + y + z)
쓸모가 없어 보이지만, ‘결과 <- 계산으로 표현할 수 있다’, ‘pure를 쓸 수 있다’는 모나드의 공통점은 확실히 만족합니다. 아무것도 못 하지만 포켓몬이긴 하고 파티 칸을 채우긴 하는 잉어킹처럼, 아무것도 못 하지만 모나드이긴 한, 그런 이상한 모나드입니다. 이 모나드는 단독으로는 거의 의미가 없고, 다른 모나드 내부에 끼워 넣을 때 진가를 발휘합니다.
이 모나드는 포켓몬으로 치면 **메타몽**처럼, 스스로는 아무것도 못 하지만 어떤 모나드로든 변신할 수 있는, 아주 메타적인 성질을 가집니다. 신기하게도 이 Free 모나드를 변신시키면, Maybe 모나드든 리스트 모나드든 어떤 모나드든 만들어 낼 수 있습니다. 설명하려면 길어지니 생략하지만, 일단 메타몽도 포켓몬이라는 것만 기억하면 충분합니다.
메타몽 귀여워요 메타몽
IO 모나드는 readFile로 파일 읽기, putStrLn으로 표준 출력 등, 외부 세계와의 온갖 상호작용을 도맡는 매우 기능 많은 모나드입니다. 또한 Either처럼 예외를 던져 도중 탈출을 하거나, ST 모나드처럼 변경 가능한 영역을 만들어 내는 것조차 가능합니다.
또 IO 모나드는 프로그램의 엔트리포인트가 되는 모나드이며, 실제 코드에서는 이 IO 모나드가 프로그램 전반에 걸쳐 등장해서, 사용자는 IO와 떼려야 뗄 수 없는 관계를 맺게 됩니다. 애니 포켓몬에서 주인공 지우가 강제로 선택하게 되고, ‘볼에 들어가기 싫다’는 핑계를 대며 어쨌든 화면에 비치려 하는 피카츄 같은 모나드라 할 수 있습니다.
예를 들어 표준 입력에서 지정한 이름의 텍스트 파일을 복사하는 계산은 다음과 같습니다.
from <- getLine
to <- getLine
putStrLn ("copy " ++ from ++ " to " ++ to)
contents <- readFile from
writeFile to contents
이 모나드도, ‘결과 <- 계산이라는 문들의 연속으로 일련의 계산을 표현할 수 있다’, ‘pure 함수로 값을 계산에 끼워 넣을 수 있다’는 두 점을 만족합니다. 확인해 둡시다.
모나드 전체에 공통인 것은 다음 두 가지뿐이었습니다.
결과 <- 어떤 같은 종류의 작용의 연속으로 일련의 계산을 표현한다pure 함수로 임의의 값을 계산에 끼워 넣을 수 있다그리고 모든 모나드는 이 틀 안에서 서로 다른 ‘기술’을 갖고 있었습니다.
pure 외에는 아무것도 못 하는 최약의 모나드Nothing으로 계산 도중 빠져나올 수 있는 기능만 가진 아주 약한 모나드Left로 도중 탈출할 수 있고, 그때 추가 정보를 가져올 수 있는, Maybe보다 조금 강한 모나드newSTRef로 변경 가능한 데이터 영역을 원하는 만큼 만들고, modifySTRef로 변경할 수 있음readFile로 파일을 다루거나 print로 표준 출력하는 기능 외에도, throwError 같은 Either 모나드 상당의 기능, newIORef 같은 ST 모나드 상당의 연산도 가능한 만능 모나드즉 한 가지 관점으로는, 모나드는 계산 안에서 쓸 수 있는 연산과 계산 과정을 자유롭게 커스터마이즈할 수 있는 도메인 특화 언어(DSL)를 실현하기 위한 틀이라고 볼 수 있습니다.
모나드에 의한 추상화는,
var 변수 = 식;
var 변수 = 식;
var 변수 = 식;
...
같은 구문을 커스터마이즈 가능하게 만든 것이라고도 볼 수 있어, ‘프로그래머블 세미콜론’이라고 설명되기도 합니다. 문과 문 사이의 세미콜론을 일종의 중위 연산자로 보고, 그 세미콜론 연산자를 연산자 오버로드하는 것과 같다는 뜻입니다.
Haskell과 PureScript는 이 틀을 코드 전반에 일관되게 재사용하고, 목적에 따라 모나드를 골라 계산을 진행하는 언어입니다. 이 때문에 Haskell/PureScript에는 throw/catch 같은 예외 처리 전용 구문이 없는데도 예외를 던져 도중 탈출하거나 예외를 잡을 수 있고, await/async가 없어도 비동기 처리를 동기 처리처럼 평탄하게 쓸 수 있습니다.
그리고 목적에 맞게 커스터마이즈한 전용 모나드를 직접 만들어 쓸 수 있는 강력한 확장성도 갖추고 있습니다. 모나드를 직접 정의하면 어떤 연산을 허용하고 어떤 연산을 허용하지 않을지, 모든 것을 스스로 통제할 수 있습니다.
프로그래밍에서 모나드는 코딩 도구이지, 이론을 감상하며 도취하기 위한 것이 아닙니다. 사용하지 않으면 아무 의미도 없습니다. 이제부터 모나드를 사용해 코드를 어떻게 쓰면 되는지 구체적으로 설명합니다.
모나드는 여러 종류가 있고, 각각 다른 능력을 가지므로, 먼저 자신의 계산 목적에 맞는 적절한 모나드를 선택해야 합니다. 곧바로 떠올릴 수 있도록 모나드 도감을 머리에 잘 넣어 두는 게 중요합니다. 여기서는 설명을 위해 IO 모나드를 사용해 봅니다. Haskell에서는 IO 모나드, PureScript에서는 Effect 모나드가 유일하게 반드시 거쳐야 하는 모나드입니다. 이 언어들로 실용 코드를 쓰려면 우선 IO/Effect만이라도 쓸 수 있게 되는 것이 급선무이고, 하나만 익혀도 다른 모나드로 가는 디딤돌이 됩니다.
지금까지 여러 번 보았던 결과 <- 작용 같은 문들의 연속으로 이루어진 구문을, do 표기법이라고 부릅니다. 이 do 표기를 자유자재로 쓰는 것이 모나드를 실용에 쓰는 데 필수입니다. 겉보기엔 결과 <- 작용이 거의 전부인 단순한 구문이지만, 사실 코드에 드러나지 않는 숨은 규칙이 까다롭습니다.
Haskell에서는 코드에서 식의 타입을 명시할 때 더블 콜론 ::을 사용해 다음처럼 씁니다.
식 :: 타입
또 타입 변수 a를 포함하는 타입 m은, 공백을 사이에 두고 다음처럼 씁니다.
m a
이를 사용해 do 표기 안의 식에 빠짐없이 타입 주석을 붙이면, do 표기의 일반형은 다음과 같습니다.
(do
v0 :: a <- expr0 :: m a
v1 :: b <- expr1 :: m b
v2 :: c <- expr2 :: m c
...
exprZ :: m z) :: m z
여기서 m 자리에는 모나드에 결부된 타입 이름이 들어갑니다. IO 모나드를 쓰는 경우에는 m을 IO로 바꾸어 다음처럼 됩니다.
(do
v0 :: a <- expr0 :: IO a
v1 :: b <- expr1 :: IO b
v2 :: c <- expr2 :: IO c
...
exprZ :: IO z) :: IO z
IO a는 그 연산이 IO라는 종류의 작용이며, 결과로 a 타입의 값을 돌려준다는 뜻입니다.
do를 붙이고 들여쓰기를 맞춘다도감의 의사코드에서는 생략했지만, do 표기에는 맨 앞에 do 키워드를 붙입니다. 또한 do 블록 내부의 식들은 들여쓰기를 맞추어야 합니다.
각 계산의 결과는, 그 이후의 계산에서만 사용할 수 있습니다.
do
v0 <- expr0
v1 <- expr1
v2 <- expr2
exprZ
이런 코드에서는 예를 들어 변수 v1은 그보다 앞선 expr0, expr1 안에서는 참조할 수 없습니다. 그보다 뒤에 있는 expr2, exprZ에서만 참조할 수 있습니다. 이는 일반 언어에서 변수에 값을 대입할 때의 동작과 같습니다.
각 줄의 결과 <- 부분은 생략 가능합니다. 예컨대 표준 출력 함수 putStrLn의 결과 타입은 ()인데, 이는 C 언어의 void 같은 것으로 데이터에는 아무 의미도 없습니다. 이런 연산의 결과를 변수에 바인딩하는 것은 무의미하므로 결과 <- 부분을 생략할 수 있습니다. () 타입에 한정되지 않고, 연산 결과가 필요 없으면 어떤 줄이든 자유롭게 생략해도 됩니다.
마지막 줄은 결과 <- 식처럼 <-를 써서 쓸 수 없습니다. 그 마지막 줄의 결과가 do 블록 전체의 결과가 되기 때문입니다.
무슨 말이냐 하면, 아래 동그라미 친 부분의 타입은 모두 같아야 한다는 것입니다.
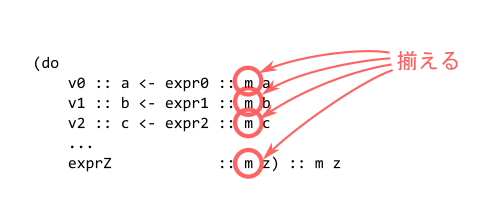
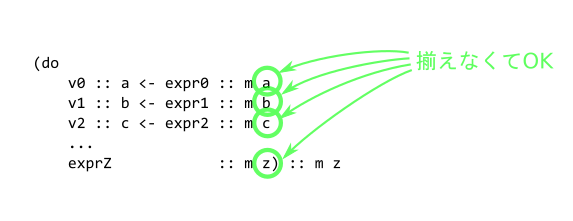
즉 Maybe 모나드와 Either 모나드처럼 서로 다른 종류의 모나드 계산을 직접 섞을 수 없다는 뜻입니다. 참고로 이 타입 생성자에 주어진, 연산 결과 타입 쪽은 각 줄마다 달라도 괜찮습니다.
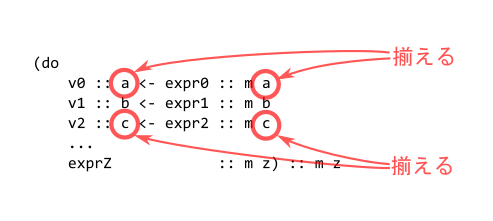
<- 오른쪽 식의 타입 m a는, 그 계산의 결과가 a 타입이 된다는 의미입니다. 이는 아래 동그라미 친 부분의 타입이 각각 일치해야 한다는 뜻입니다.
do 식은 그것 자체가 식이며, 그 타입은 do 식 마지막 줄의 식과 일치해야 합니다. 이 마지막 식의 값이 do 전체 계산의 결과가 되기 때문입니다.

이제 실제로 모나드를 쓰려면, 어떤 연산이 가능한지 문서에서 확인해야 합니다. 예컨대 Haskell에서는 기본으로 임포트되는 표준 모듈 Prelude에 표준 출력 함수나 간단한 파일 조작 함수가 정의되어 있습니다.
함수라면 인수를 주어 최종적으로 IO a 꼴이 되면 do 표기 안에 쓸 수 있고, 그중에는 처음부터 IO a 타입인 값도 있습니다. 이를 문서에서 찾습니다. 여기서는 다음 함수와 값을 쓰겠습니다.
readFile :: FilePath -> IO String
writeFile :: FilePath -> String -> IO ()
getLine :: IO String
putStrLn :: String -> IO ()
모두 타입 주석의 마지막이 IO a 꼴인 것을 볼 수 있습니다. 이들은 모두 IO 모나드 계산에서 쓸 수 있는 연산이라는 뜻입니다.
이 함수들을 사용해 텍스트 파일 복사를 하는 프로그램을 만들어 봅니다. 표준 입력에서 복사 원본 파일명과 목적지 파일명을 읽고, 그 이름에 따라 파일을 복사합니다.
main :: IO ()
main = do
from :: String <- getLine :: IO String
to :: String <- getLine :: IO String
putStrLn ("copy " ++ from ++ " to " ++ to) :: IO ()
contents :: String <- readFile from :: IO String
writeFile to contents :: IO ()
앞서 든 규칙들이 모두 지켜지는지 확인해 보세요.
여기서는 설명을 위해 과도하게 타입 주석을 붙였지만, 모두 타입 추론이 가능하므로 다음처럼 전부 없애도 됩니다.
main = do
from <- getLine
to <- getLine
putStrLn ("copy " ++ from ++ " to " ++ to)
contents <- readFile from
writeFile to contents
자신이 모나드를 이해했는지 확인하는 유일한 방법은, 스스로 실제 코드를 써 보는 것입니다. 모나드를 좀처럼 이해하지 못한다면, 가장 큰 이유는 스스로 모나드를 쓰는 코드를 작성하려 하지 않기 때문이라고 생각합니다. 계몽적인 글을 아무리 많이 읽어도 모나드를 이해하진 못합니다. 왜냐면 자신이 모나드를 쓰는 코드를 쓰지 않기 때문입니다. 모나드의 정의를 구멍 날 때까지 들여다봐도 이해하지 못합니다. 왜냐면 자신이 코드를 쓰지 않기 때문입니다. 아마 이 글을 연 분들은 모두 모나드를 이해하고 싶을 것입니다. 우선 코드를 써 봅시다.
Haskell 설치는 현재 Stack 일択입니다. 설치도 어렵지 않으니 후딱 설치합시다.
PureScript 설치는 npm이 있다면 npm install purescript 한 방입니다. 다만 생 컴파일러는 여러 준비가 번거로우니, pulp라는 도구로 빌드하는 것이 가장 빠릅니다.
PureScript는 후발인 만큼 라이브러리가 잘 정리되어 있고, 모나드 주변도 연륜 있는 Haskell 라이브러리군보다 이해하기 쉽다고 생각합니다. PureScript 라이브러리는 Pursuit라는 문서 검색 엔진으로 훑어보는 게 빠릅니다.
위 언어 외에는 모나드의 위력을 충분히 끌어내기 어렵습니다. 하지 맙시다.
모나드의 존재 의의에 대해 ‘언어 전반의 식에서 부작용을 제거했으므로, 그 대신 모나드를 도입해 부작용을 다룰 수 있게 했다’처럼 소개되는 경우가 있습니다. 그러면 처음부터 부작용 허용이면 모나드 같은 어려운 게 필요 없잖아!라고 생각할 수도 있겠죠. 도입 당시의 계기는 확실히 그랬던 것 같지만, 여러 것이 모나드로 다뤄질 수 있음이 밝혀진 지금은, 단지 순수 언어 위에서 부작용을 다루기 위한 것 이상의 장점이 모나드에는 있다고 봅니다.
분명한 장점을 들자면, 다른 언어에선 언어의 구문을 확장해야 겨우 도입되는 기능을, 언어 자체를 바꾸지 않고 단지 라이브러리를 추가하는 것만으로 실현할 수 있다는 점이 있습니다.
aff 패키지를 도입하면 비동기 처리를 평탄하게 쓸 수 있다!exceptions 패키지를 도입하면 throw로 예외를 던지고 try로 예외를 잡을 수 있다!lists 패키지를 도입하면 리스트 모나드로 비슷한 것을 할 수 있다! (구문 모양은 꽤 다르지만)st 패키지를 도입하면 pokeSTArray로 배열 일부를 바꿔 가며 처리할 수 있다!refs 패키지를 도입하면, writeRef로 변수의 내용을 바꿀 수 있다!물론, 특별한 구문이 필요해질 때마다 언어 사양을 고치고 컴파일러를 개량하는 방법도 있을 것입니다. 하지만 그러려면 몇 달, 몇 년의 논의와 컴파일러 자체를 고치는 노력이 필요하겠죠. 반면 작용을 모나드로 추상화한 언어라면, 라이브러리 하나 만드는 것으로 충분합니다. 게다가 새로운 구문을 도입해 봤지만 써 보니 불편해서 필요 없겠다거나, 더 새로운 방법이 나와서 옛 구문은 필요 없겠다, 같은 일도 생기겠죠. 한 번 언어 사양에 넣어 버리면 쉽게 폐지하기 어렵습니다. 언어는 복잡해지기만 합니다. 하지만 그냥 라이브러리라면 폐지도 훨씬 쉽습니다.
세상 ‘모나드 입문’의 많은 글이 ‘모나드 법칙’이라는 수학스러운 규칙을 설명합니다. 지나치게 추상적이라 초심자를 좌절시키는 모나드 법칙이지만, 사실 초심자는 전혀 알 필요가 없습니다.
모나드 법칙은 모나드 인스턴스를 ‘정의할 때’ 지켜야 하는 규칙일 뿐, 이미 정의된 모나드를 ‘사용할 때’에는 자동으로 만족되어 있습니다. 그리고 Haskell/PureScript/Scala 정도라면 모나드 관련 라이브러리가 풍부하므로, 스스로 모나드 인스턴스를 정의할 일은 거의 없습니다. 모나드 법칙이 필요해지는 때란, 지금까지 아무도 만든 적 없는 새로운 모나드를 떠올렸다는 뜻이고, 이는 매우 고급 주제입니다. 기존 라이브러리에 없는 새 모나드를 생각해 낸다는 것은, 전혀 새로운 정렬 알고리즘을 고안했다든가, 완전히 새로운 자료구조를 고안했다든가 하는 수준의 얘기입니다. 보통은 그 정도 지식이 필요하지 않습니다.
게다가, 모나드 구현이 제대로 모나드 법칙을 만족하는지 간단히 확인할 방법도 없습니다. 그 때문에 Haskell 표준 라이브러리에서 제공되던 ListT라는 모나드(정확히는 ‘모나드 변환자’)가 모나드 법칙을 만족하지 않는 버그가 뒤늦게 발각된 일도 실제로 있었습니다. 함수형 프로그래밍에 숙련된 사람도 무심코 모나드 법칙을 어길 수 있는 것입니다. 이런 난해한 주제를 초심자가 파고들 필요는 전혀 없습니다.
물론 지식으로서 모나드 법칙을 알아 두면 좋고, 스스로 모나드 인스턴스를 정의해 보면 더 깊은 이해를 얻을 수 있다고 생각합니다. 수학적 내용을 좋아하는 분은 그쪽 개념을 공부해 보면 재미있을 것입니다. 하지만 모나드 법칙 이해에 막혀 함수형 프로그래밍 습득을 포기할 바엔, 그런 건 훌훌 넘기고 실제로 모나드를 쓰는 연습을 하는 편이 훨씬 이해로 이어집니다.
여러 모나드를 묵묵히 진흙내 나게 배우고 마침내 모나드 개념을 체득한 사람들 중에는, ‘모나드란 무엇인지는 모나드 법칙을 보면 전부 알 수 있어야 한다’ 같은 멋들어진 말을 하며 폼을 잡는 분도 적지 않은 듯합니다. 물론 모나드 정의가 모나드 법칙으로 서술된 대로라는 점은 틀렸다 하기 어렵지만, 모나드 법칙만 보고 이해할 수 있는 천재는 극소수입니다. 그 외의 보통 사람은 다양한 구체 모나드를 실제로 써 보면서 비로소 이해에 이르게 됩니다. 그런 번쩍이고 스마트하고 세련된 입문은 보통 사람에게는 지름길 같아 보여도 돌아가는 길이니, 각 모나드를 실제로 써 보며 차근차근 배워 갑시다.
모나드란, 결과 <- 작용이라는 문들의 연속으로 이루어진 계산에서, 그 계산 안에서 어떤 작용(연산)이 가능한지, 어떤 순서로 계산이 진행되는지를 자유롭게 제어 가능하게 하는 틀입니다. 앞서 본 7개의 모나드 중 IO 모나드를 제외하면 모두 스스로 정의할 수 있습니다. 하고 싶은 계산에 맞춰 맞춤형 모나드를 정의하는 것도 가능합니다. 이 틀 하나만 있으면, for문 같은 반복도, try-catch 같은 예외 처리 기구도, 쓰기 가능한 영역도, async/await 같은 비동기 처리나 문자열 구문 분석에 특화된 DSL까지, 전부 스스로 만들어 낼 수 있습니다.
아무리 정의를 들여다봐도, 상자니 포켓몬이니 하는 은유에 기대 봐도, 모나드 이해로 이어지지 않습니다. 각 모나드를 실제로 사용해 보며, 당신의 모나드 도감을 하나하나 꾸준히 채워 가는 것이, 모나드 마스터로 가는 유일한 길이라 할 수 있습니다.
포켓몬 마스터는 여러 포켓몬을 자유자재로 다룰 수 있지만, 초보 포켓몬 트레이너가 ‘내가 포켓몬을 못 쓰는 건 내가 포켓몬 마스터가 아니기 때문이다. 포켓몬을 쓸 수 있게 되려면 먼저 포켓몬 마스터가 되자’고 생각한다면, 인과관계가 거꾸로입니다. 포켓몬 마스터가 되었기 때문에 포켓몬을 쓸 수 있는 게 아니라, 포켓몬을 쓸 수 있기 때문에 포켓몬 마스터인 것입니다. 마찬가지로, 모나드를 이해했기 때문에 모나드 인스턴스를 잘 쓰는 것이 아니라, 각 모나드 인스턴스를 잘 쓸 수 있게 되었기 때문에 모나드를 이해한 모나드 마스터가 되는 것입니다. 어떤 초보 트레이너도 처음엔 꼬렛부터 잡듯이, 먼저 각 모나드를 직접 쓰며 꾸준히 연습해 봅시다.
우선 스스로 코드를 써 보는 것이 최우선이지만, 물론 문헌도 모나드 이해에 필수입니다. 필자의 개인적 추천은, ‘모나드의 모든 것’을 열심히 완독해 보는 것입니다.
----------------------------------------------- キリトリセン ---------------------------------------------------------------
평소 저는 설명이 과한 편이라, 긴 글을 어려워하는 분도 읽을 수 있도록 이번엔 문장을 가능한 한 줄여 보았습니다. 처음 쓴 분량의 절반 이하입니다. 자신이 모르는 언어는 몇 줄이어도 읽지 않고, 동작을 유추하지도 않는 분도 있는 듯한데, 샘플 코드도 최대한 줄였으니 어떻게든 상상하며 읽어 주세요. 부정확한 내용에 대한 주석도 과감히 날렸으니, 세세한 부분은 신경 쓰지 말아 주세요.
또 이 글에서는 수학스러운 이야기야 물론, ‘타입 클래스’ 같은 Haskell 냄새 나는 기능, Functor/Applicative/Monad라는 타입 클래스 계층, 모나드의 정의, 모나드 법칙 같은 내용도 싹 뺐습니다. 타입 클래스 계층을 차례로 따라가며 정의와 모나드 법칙/펑터 법칙으로 기초를 다지는 입문은, 이미 알고 있는 사람에게는 간결·명료·합리적이고 정연한 과정으로 보이지만, 초심자에게는 추상성의 늪일 뿐입니다. 초등 1학년에게 공리적 집합론과 페아노 산술을 가르친 다음 덧셈을 가르치는 친절하고 얌전한 입문 따위는 창밖으로 던져 버립시다. 모나드 법칙에 이르면, 현실 코딩에서는 거의 도움이 되지 않는 지식입니다. 이해에도 도움이 되지 않습니다. 이런 것을 얼마나 대단한 것인 양 가르치는 것은, 가르칠 내용의 우선순위를 잘못 잡은 것입니다.
포켓몬 요소는, 20주년이라는 소식을 글 쓰는 중에 듣고 후입으로 설명에 붙였습니다. ‘이 글, 포켓몬 요소 필요 없지 않나?’라고 생각하셨겠지만, 이런 건 임팩트가 중요합니다. 뭐 이 텍스트의 개그는 꽤 억지라서 보시다시피 ‘모나드=포켓몬 이론’은 무사히 파산했습니다. ギエピー! 또, 맨 앞의 이미지는 피카츄가 아니라 야돈 아니냐! 하고, 하테나 북마크 같은 데서 태클 걸어 주시길 바랐는데, 아무도 태클을 안 걸어 주셨습니다! 정말 감사합니다!