Rust의 트리형 소유권, 가변 빌림의 배타성, 빌림의 전파성(전염성)을 출발점으로, 빌림 검사기에 불친절한 공유·순환·자기 참조·컨테이너 순회·브랜치 간 빌림 등 현실 문제를 피하거나 해결하는 여러 전략을 정리합니다. 분할 빌림, 게터/세터 제거, ID/핸들+아레나, 변이 지연(명령화), 제자리 변이 회피(영속 자료구조), 인덱스 수동 관리, 얕은 복제, 내부 가변성(RefCell/Mutex/QCell), ECS, bump allocator, unsafe 주의점, async Send+'static 제약, Send/Sync, Arc 성능, 잠금 재진입성 등까지 폭넓게 다룹니다.
Rust의 3가지 중요한 사실:
먼저 메모리 내 데이터의 참조 2 모양을 고려하자.
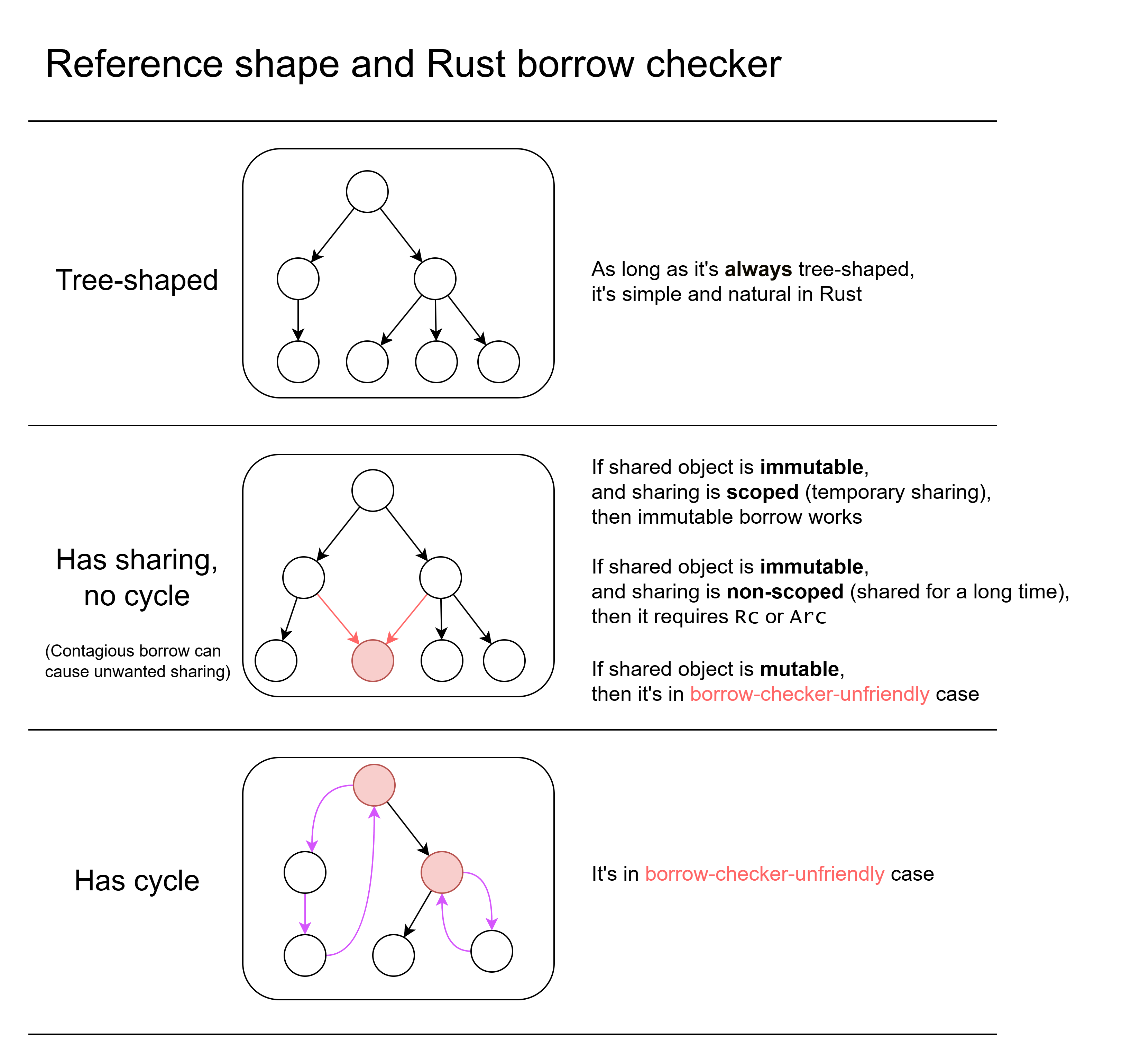
참조가 트리형이면, Rust에서 단순하고 자연스럽다.
참조 모양에 공유가 있으면, 다소 복잡해진다.
공유란 동일 객체를 가리키는 참조가 둘 이상 존재함을 의미한다.
공유되는 객체가 불변일 때:
공유되는 객체가 가변이라면, 빌림 검사기에 불친절한 경우다. 해결책은 아래에서 자세히 다룬다.
전파적 빌림 때문에 의도치 않은 공유가 발생할 수 있다(아래에 설명).
참조 모양에 순환이 있으면, 이것 또한 빌림 검사기에 불친절한 경우다. 해결책은 아래에서 자세히 다룬다.
빌림 검사기와의 대부분의 싸움은 빌림 검사기에 불친절한 경우에서 일어난다.
빌림 검사기에 불친절한 경우의 해결책(아래에서 자세히 설명):
데이터 지향 설계. 불필요한 게터/세터를 피하라.
바깥 스코프에서 분할 빌림을 하고 각 컴포넌트의 빌림을 따로 전달하라.
빌림을 ID/핸들로 대체하라. 데이터를 아레나에 보관하라.
변이를 지연하라. 변이를 명령으로 바꿔 나중에 실행하라.
제자리 변이를 피하라. 재생성(mutant-by-recreate) 방식으로 변경하라. 불변 데이터 공유에는 Arc를 쓰라. 지속(persistent) 자료구조를 사용하라.
순환 참조의 경우:
가능한 한 빌림을 짧게 하라. 예를 들어, 컨테이너 for 루프 for x in &vec {} 대신 원시 인덱스 루프를 사용한다.
Arc<QCell<T>>
Arc<RwLock<T>>(정말 필요할 때만)
unsafe와 생 포인터(정말 필요할 때만)
전파적 빌림 문제는 Rust에서, 특히 초보자에게 아주 흔하고 중요한 좌절의 원인이다.
앞서 말한 두 가지 중요한 사실:
간단한 예시:
pub struct Parent { total_score: u32, children: Vec<Child> }pub struct Child { score: u32 }impl Parent { fn get_children(&self) -> &Vec<Child> { &self.children } fn add_score(&mut self, score: u32) { self.total_score += score; } }fn main() { let mut parent = Parent{total_score: 0, children: vec![Child{score: 2}]}; for child in parent.get_children() { parent.add_score(child.score); }}
컴파일 에러:
25 | for child in parent.get_children() { | --------------------- | | | immutable borrow occurs here | immutable borrow later used here26 | parent.add_score(child.score); | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ mutable borrow occurs here
(이 단순화된 예시는 전파적 빌림 문제를 설명하기 위한 것이다. total_score는 실제 애플리케이션에 존재하는 복잡한 상태에 비유된다. 이후의 예시도 마찬가지. 단순 정수 합산은 .sum()이나 로컬 변수를 쓰면 된다. 단순 정수 가변 상태는 Cell로 우회할 수도 있다.)
이 코드는 완전히 메모리 안전하다. .add_score()는 total_score 필드만 건드리고, .get_children()은 children 필드만 건드린다. 서로 다른 데이터에 동작한다. 그러나 빌림 검사기는 전파적 빌림 때문에 겹친다고 판단한다:
당신은 특정 필드만 빌리고 싶었지만, 전체 객체를 빌리도록 강제된 것이다.
만약 get_children과 add_score를 인라인하면 어떨까? 그러면 컴파일된다:
pub struct Parent { total_score: u32, children: Vec<Child> }pub struct Child { score: u32 }fn main() { let mut parent = Parent{total_score: 0, children: vec![Child{score: 2}]}; for child in &parent.children { let score = child.score; parent.total_score += score; } }
왜 컴파일될까? 분할 빌림을 수행하기 때문이다. 컴파일러는 하나의 함수(main()) 안에서 개별 필드의 빌림을 보고, 전파적 빌림을 하지 않는다.
더 깊은 원인:
전파적 빌림 문제의 해결책(우회책) 요약(아래에서 자세히 설명):
불필요한 게터/세터 제거
변이 지연
제자리 변이 피하기
바깥 스코프에서 분할 빌림을 하라. 또는 아예 struct를 없애고 필드를 별도 인수로 전달하라(불편함).
컨테이너 for 루프에서 인덱스(또는 키)를 수동으로 관리하라. 가능한 한 빌림을 짧게 유지하라.
데이터를 그냥 복제하라(얕은 복제 가능).
내부 가변성(셀과 락) 사용.
다른 해결책은 변이를 데이터로 취급하는 것이다. 무언가를 변이하려면, 변이 명령을 커맨드 큐에 추가하라. 그런 다음 변이 명령을 한 번에 실행한다. (커맨드는 베이스 데이터를 간접적으로 빌리지 않도록 주의하라.)
큐의 명령을 실행하기 전에 최신 상태가 필요하면? 커맨드 큐와 베이스 데이터를 함께 검사해서 최신 상태를 얻는다(LSM 트리가 유사한 일을 수행한다). 보통 처리 과정에서 최신 상태가 필요하지 않도록, 여러 단계로 분리할 수 있다.
앞선 코드를 지연 변이로 다시 쓰면:
pub struct Parent { total_score: u32, children: Vec<Child> } pub struct Child { score: u32 } pub enum Command { AddTotalScore(u32), // can add more kinds of commands } impl Parent { fn get_children(&self) -> &Vec<Child> { &self.children } fn add_score(&mut self, score: u32) { self.total_score += score; } } fn main() { let mut parent = Parent{total_score: 0, children: vec![Child{score: 2}]}; let mut commands: Vec<Command> = Vec::new(); for child in parent.get_children() { commands.push(Command::AddTotalScore(child.score)); } for command in commands { match command { Command::AddTotalScore(num) => { parent.add_score(num); } }; } }
지연 변이는 “빌림 검사기 우회용 꼼수”만은 아니다. 변이를 데이터로 다루는 것의 다른 장점:
변이를 데이터로 취급하는 아이디어의 다른 적용:
앞선 문제는 부분적으로 가변 빌림의 배타성 때문에 발생한다. 모든 빌림이 불변이라면, 전파적 빌림은 보통 문제가 되지 않는다.
변이를 피하는 일반적 방법은 재생성에 의한 변이(mutate-by-recreate)다. 모든 데이터는 불변이며, 무언가를 변이하려면 새로운 버전을 만든다. Haskell 같은 순수 함수형 언어처럼.
안타깝게도 재생성에 의한 변이도 전염적이다. 자식의 새 버전을 만들면, 그 자식을 보유하는 부모의 새 버전도 만들어야 하고, 부모의 부모도, … 계속된다. 이런 연쇄적 재생성을 편리하게 해주는 추상화로 lens 같은 것이 있다.
재생성에 의한 변이는 다음 같은 경우에 유용하다:
지속(persistent) 자료구조: 변하지 않은 부분 구조를 공유(구조적 공유)해 재생성 변이를 더 빠르게 만든다. 관련 크레이트: rpds, im, pvec.
rpds를 사용해, 복제한 해시 맵을 순회하며 동시에 변이하는 예:
let mut map: HashTrieMap<i32, i32> = HashTrieMap::new(); map = map.insert(2, 3); for (k, v) in &map.clone() { if *v > 2 { map = map.insert(*k * 2, *v / 2); } }
구조체의 필드 분할 빌림: 앞서 말했듯, 하나의 스코프(예: 함수) 내에서 구조체의 두 필드를 개별로 빌리면 Rust는 분할 빌림을 수행한다. 이는 전파적 빌림 문제를 해결할 수 있다. 게터/세터 함수는 빌림 정보를 함수 시그니처에서 거칠게 만들기 때문에 분할 빌림을 깨뜨린다.
전파적 빌림은 컨테이너에서도 일어난다. 컨테이너의 한 요소를 빌리면, 다른 요소를 가변으로 빌릴 수 없다. 컨테이너를 분할 빌림하는 방법:
컨테이너 순회는 매우 흔하다. Rust는 간결한 컨테이너 for 문법 for x in &container {...}를 제공한다. 하지만 이는 암묵적으로 컨테이너 전체를 계속 빌리는 이터레이터를 갖는다.
한 가지 해결책은, 이터레이터를 쓰지 않고 루프에서 인덱스(키)를 수동으로 관리하는 것이다. Vec이나 슬라이스는 인덱스를 가변 로컬 변수로 두고 while 루프로 배열을 순회할 수 있다.
앞선 예시를 수동 루프로 다시 쓰면:
pub struct Parent { total_score: u32, children: Vec<Child> } pub struct Child { score: u32 } impl Parent { fn get_children(&self) -> &Vec<Child> { &self.children } fn add_score(&mut self, score: u32) { self.total_score += score; } } fn main() { let mut parent = Parent{total_score: 0, children: vec![Child{score: 2}]}; let mut i: usize = 0; while i < parent.get_children().len() { let score = parent.get_children()[i].score; parent.add_score(score); i += 1; } }
여기서는 .get_children()을 여러 번 호출한다. 매번 반환된 빌림은 짧은 시간만 유지된다. 요소의 score 필드를 복사하면 그 요소에 대한 빌림을 중지하고, 이는 간접적으로 부모에 대한 빌림도 중지한다.
변이 전에 요소에 대한 빌림을 멈춰야 한다는 점에 유의. 이 예시는 score 정수를 복사해 자식에 대한 빌림을 멈춘다. 더 큰 자료구조에서도 빌림을 멈추려면 복사/복제가 필요하다(참조 카운팅과 지속 자료구조는 복제 비용을 줄일 수 있다).
(Rust에는 C 스타일 for (int i = 0; i < len; i++) 루프가 없다.)
비슷한 일을 BTreeMap에서도 할 수 있다. 최소 키를 얻고, 다음 키를 반복적으로 얻는다. 이렇게 하면 BTreeMap을 계속 빌리지 않고 순회할 수 있다.
BTreeMap을 순회하며 변이하는 예:
let mut map: BTreeMap<i32, i32> = BTreeMap::new();map.insert(2, 3);let mut curr_key_opt: Option<i32> = map.first_key_value().map(|(k, _v)| *k); while let Some(current_key) = curr_key_opt { let v: &i32 = map.get(¤t_key).unwrap(); if *v > 2 { map.insert(current_key * 2, *v / 2); } curr_key_opt = map.range((Bound::Excluded(¤t_key), Bound::Unbounded)) .next().map(|(k, _v)| *k);}
키를 복사/복제해야 하고, 변이 전에 요소 빌림을 중지해야 한다는 점에 유의.
이 방식은 HashMap에는 통하지 않는다. HashMap은 순서를 보장하지 않고 다음 키 얻기를 지원하지 않는다. 하지만 indexmap의 IndexMap에는 통한다. 정수 인덱스로 키를 얻을 수 있어(내부적으로 배열 사용), 중간에서 제거/추가는 빠르지 않다.
데이터를 복제하면 그 데이터를 계속 빌리지 않아도 된다. 불변 데이터는 Rc(또는 Arc)로 감싸고 복제하는 방법이 통한다:
앞선 예시를 컨테이너를 Rc로 감싸고 for 루프를 쓰도록 다시 쓰면:
pub struct Parent { total_score: u32, children: Rc<Vec<Child>> } pub struct Child { score: u32 } impl Parent { fn get_children(&self) -> Rc<Vec<Child>> { self.children.clone() } fn add_score(&mut self, score: u32) { self.total_score += score; } } fn main() { let mut parent = Parent{total_score: 0, children: Rc::new(vec![Child{score: 2}])}; for child in parent.get_children().iter() { parent.add_score(child.score); } }
가변 데이터의 경우, 복제와 변이를 더 효율적으로 하기 위해 앞서 말한 지속 자료구조를 쓸 수 있다.
데이터가 작으면 깊은 복제도 보통 괜찮다. 핫 코드가 아니라면 깊은 복제도 대개 괜찮다.
일부는 “순환 참조는 나쁜 것이다. 수학에서 순환 참조가 얼마나 많은 문제를 만드는지 보라”고 주장할 수 있다:
Details
순환 논법: A면 B, B면 A. 순환 증명은 잘못되었고, A도 B도 증명할 수 없다.
자신을 간접적으로 포함하는 집합은 러셀의 역설을 일으킨다: R을 ‘자기 자신을 원소로 포함하지 않는 모든 집합의 집합’이라 하자. R이 R을 포함하면 R은 R을 포함하지 않아야 하고, 그 반대도 성립한다. 집합론은 신중하게 순환 참조를 피한다.
정지 문제는 순환 참조를 이용해 풀 수 없음을 증명한다:
halts(program, input)라는 함수가 존재한다고 가정하자. program과 input을 받아 program(input)이 결국 정지하는지 여부를 불리언으로 알려준다.
이제 역설 프로그램 paradox를 구성하자:
fn paradox(program: Program) { if halts(program, program) { while true {} // dead loop } else { return; // halts }}
그러면 halts(paradox, paradox)는 역설에 빠진다. true를 반환하면 paradox(paradox)는 정지하는데, paradox 정의상 데드루프여야 한다.
Rice의 정리는 정지 문제의 확장이다: 모든 비자명한 프로그램 의미 속성은 결정 불가능하다(최종 정지 여부 포함).
정지 문제, 러셀의 역설, 괴델의 불완전성 정리에는 공통점이 있다. 모두 자기 지시와 자기 부정이 결합돼 역설을 만든다.
수학에서 순환 참조가 나쁘다고 해서, 프로그래밍에서도 나쁘다는 뜻은 아니다. 수학 이론의 순환 참조와 데이터의 순환 참조는 다르다. 프로그래밍에는 유효한 순환 참조의 사례가 많다(예: 리눅스 커널에서 잘 동작하는 이중 연결 리스트).
하지만 순환 참조는 메모리 관리에 위험을 추가한다:
흔한 순환 참조 사례:
앞선 사례 1: 자식이 편의를 위해 부모를 참조하는 경우. OOP 코드에서 자식 객체 참조만 있고 부모의 데이터가 필요할 때, 자식이 부모를 들고 있으면 편하다. 그렇지 않으면 부모를 인수로 함께 넘겨야 한다.
OOP 언어에서의 그 편의성은 Rust에서는 곤란을 부른다. 순환 참조 대신 추가 인수를 넘기는 것을 권장한다.
앞서 말한 전파적 빌림 문제 때문에, 내부 가변성을 쓰지 않는 한 자식과 부모를 동시에 가변으로 빌릴 수 없다. 우회책은 1) 부모에서 분할 빌림을 수행하고 부모의 개별 컴포넌트를 넘긴다(다른 언어보다 인수가 많고 장황해진다) 2) 내부 가변성을 사용한다(RefCell, Mutex, QCell 등).
옵저버 패턴은 GUI와 기타 동적 반응 시스템에서 흔히 사용된다. 부모가 자식에서 어떤 이벤트가 발생했을 때 통지를 받고 싶다면, 부모가 콜백을 자식에 등록하고, 자식은 이벤트가 일어나면 콜백을 호출한다.
그러나 콜백 함수 객체는 종종 부모를 참조해야 한다(부모의 데이터를 사용해야 하므로). 그러면 앞서 사례 2에서 말했듯 부모→자식, 자식→콜백, 콜백→부모의 순환이 생긴다.
해결책:
예: GUI 앱에서 카운터와 버튼이 있고, 버튼 클릭이 카운터를 증가시킨다:
struct ParentComponent { button: ChildButton, counter: u32, } struct ChildButton { on_click: Option<Box<dyn FnMut() -> ()>>, } fn main() { let mut parent = ParentComponent { button: ChildButton { on_click: None }, counter: 0 }; parent.button.on_click = Some(Box::new(|| { parent.counter += 1; })); }
컴파일 오류
error[E0597]: parent.counterdoes not live long enough --> src\main.rs:19:9 |13 | let mut parent = ParentComponent { | ---------- bindingparentdeclared here...18 | parent.button.on_click = Some(Box::new(|| { | - -- value captured here | ___________________________________| | |19 | | parent.counter += 1; | | ^^^^^^^^^^^^^^ borrowed value does not live long enough20 | | })); | |______- coercion requires thatparent.counteris borrowed for'static21 | } | - parent.counterdropped here while still borrowed | = note: due to object lifetime defaults,Box<dyn FnMut()>actually meansBox<(dyn FnMut() + 'static)>``
Rc<RefCell<>>로 해결하는 것은 번거롭고 “시끄럽다”:
struct ParentComponent { button: Rc<RefCell<ChildButton>>, counter: u32, } struct ChildButton { on_click: Option<Box<dyn Fn() -> ()>>, } fn main() { let button: Rc<RefCell<ChildButton>> = Rc::new(RefCell::new( ChildButton { on_click: None } )); let parent: Rc<RefCell<ParentComponent>> = Rc::new(RefCell::new( ParentComponent { button: button.clone(), counter: 0 } )); let weak_parent: Weak<RefCell<ParentComponent>> = Rc::downgrade(&parent); button.clone().borrow_mut().on_click = Some(Box::new(move || { weak_parent.upgrade().unwrap().borrow_mut().counter += 1; })); if let Some(f) = &button.borrow().on_click { f() } assert!(parent.borrow().counter == 1); }
upgrade, downgrade, unwrap, borrow, borrow_mut 같은 번거로운 요소가 많다. 권장하지 않는다.
부모 컴포넌트의 상태를 콜백이 캡처하는 대신 콜백의 인수로 넘기면, 순환 참조가 없어지고 훨씬 단순해진다:
struct ParentState { counter: u32, } struct ParentComponent { button: ChildButton, state: ParentState, } struct ChildButton { on_click: Option<Box<dyn Fn(&mut ParentState) -> ()>>, } fn main() { let mut parent = ParentComponent { button: ChildButton { on_click: None }, state: ParentState { counter: 0 }, }; parent.button.on_click = Some(Box::new(|state| { state.counter += 1; })); parent.button.on_click.unwrap()(&mut parent.state); assert!(parent.state.counter == 1); }
또 다른 해결책은 콜백을 없애고 이벤트 처리(참조 대신 ID 사용)로 대체하는 것이다:
enum Event { ButtonClicked { button_id: Uuid }, // ... } struct ParentComponent { id: UUid, button: ChildButton, counter: u32, } struct ChildButton { id: Uuid, } impl ParentComponent { fn handle_event(&mut self, event: Event) -> bool { match event { Event::ButtonClicked { button_id } if button_id == self.button.id => { self.counter += 1; true } _ => false, } } }
앞서 말한 사례 3과 4처럼, 자료구조가 순환 참조를 필요로 하는 경우가 있다.
해결책:
자기 참조란, 구조체가 자신이 소유한 데이터의 다른 부분을 가리키는 내부 포인터를 포함하는 것을 의미한다.
제로 오버헤드 자기 참조는 Pin과 unsafe가 필요하다. 일반적인 Rust 가변 빌림은 값 이동을 허용한다(mem::replace, mem::swap 등). Pin은 이를 금지한다. 이동으로 자기 참조 포인터가 무효화될 수 있기 때문이다. 복잡하고 사용이 어렵다. 우회책은 자식을 분리하고 참조 카운팅을 써서 자기 참조가 아니게 만드는 것이다.
데이터 지향 설계:
일부는 핸들/ID 사용을 “빌림 검사기가 강제한 불쾌한 우회책”으로 여길 수 있다. 하지만 GC 언어에서도 객체를 ID로 참조하는 건 흔하다. 참조는 DB에 저장하거나 네트워크로 보낼 수 없기 때문이다. 5
아레나의 한 종류로 slotmap이 있다:
HashMap이나 TreeMap 같은 다른 맵 구조도 아레나가 될 수 있다.
아레나에서 요소 제거가 없다면, Vec도 아레나가 될 수 있다.
아레나에서 중요한 점:
일부는 “아레나는 ‘use-after-free에 상응하는 것’을 막지 못하니 문제를 해결하지 못한다”고 생각할 수 있다. 그러나 아레나는 버그의 결정성을 크게 높여 디버깅을 훨씬 쉽게 만든다. 무작위로 발생하는 메모리 안전 하이젠버그는 산티나이저를 켜면 더는 발생하지 않을 수 있다. 산티나이저가 메모리 배치를 바꾸기 때문이다.
ECS는 OOP와 다른 방식의 데이터 구성법이다. OOP에서는 객체의 필드가 메모리에 함께 놓이지만, ECS에서는 객체가 컴포넌트들로 분리된다. 서로 다른 엔티티의 같은 종류 컴포넌트는 함께 관리되며(종종 메모리에 연속 배치), 캐시 친화성이 좋아질 수 있다(성능은 많은 요인과 구체적 상황에 좌우됨).
ECS는 상속보다 합성을 선호한다. 상속은 코드를 특정 타입에 묶어 합성이 어렵게 되는 경향이 있다.
(예: OOP 게임에서 Player는 Entity를 상속하고, Enemy도 Entity를 상속한다. 충돌 무시 특수 적 Ghost는 Enemy를 상속한다. 어느 날 플레이어 스킬로 일시적으로 Ghost처럼 충돌을 무시하게 하려면, Player를 Ghost로 상속시킬 수 없어 코드를 중복해야 한다. ECS에서는 특수 충돌 컴포넌트를 조합하는 것만으로 해결된다.)
일반화된 참조(generalized reference)의 개념:
일반화된 참조는 강한 것과 약한 것으로 나뉜다:
여기에는 GC 언어의 일반 참조(널이 아닐 때), Rust의 빌림과 소유권, 강한 참조 카운팅(Rc, Arc, shared_ptr이 널이 아닐 때), 외래 키 제약이 있는 DB ID가 포함된다.
여기에는 외래 키 제약 없는 ID, 핸들, GC 언어의 약한 참조, 약한 참조 카운팅(Weak, weak_ptr)이 포함된다.
주요 차이점:
약한 일반화 참조는 모든 데이터 접근이 실패할 수 있어, 매번 오류 처리가 필요하다(panic도 오류 처리의 일종).
강한 일반화 참조는 참조된 객체의 라이프타임이 참조의 존재와 강하게 결합된다:
약한 일반화 참조는 객체 라이프타임이 참조와 디커플된다.
객체 라이프타임과 그것을 참조하는 방식의 디커플링을 설계하고 싶다면:
앞서 말했듯, Rust에는 가변 빌림의 배타성이 있다:
이를 “변이 XOR 공유”라고도 한다. 변이와 공유는 공존할 수 없다.
멀티스레드 상황에서는 자연스럽다. 여러 스레드가 같은 불변 데이터를 읽는 건 문제가 없다. 한 스레드가 데이터를 변이하는 순간, 다른 스레드는 동기화(원자성, 락 등) 없이는 안전하게 읽거나 쓸 수 없다.
하지만 단일 스레드에서는 이 제약이 자연스럽지 않다. Rust 이외의 주류 언어에는 이런 제약이 없다.
변이 XOR 공유는 어떤 의미에서는 필요충분하지 않다. 필요하지 않다: Java로 작성된 모든 프로그램처럼 데이터를 광범위하게 공유해도 잘 작동하는 프로그램이 많다. 충분하지도 않다: 어느 정도 공유가 필요한 문제가 많기 때문이다. 그래서 Rust에는 Arc<Mutex<T>>, AtomicU32, 그리고 궁극의 백도어인 unsafe같은 백도어가 존재한다.
- The borrow checker within
가변 빌림의 배타성은 단일 스레드에서도 내부 포인터의 안전을 위해 중요하다:
Rust에는 내부 포인터가 있다. 내부 포인터는 다른 객체 내부의 일부 데이터를 가리키는 포인터이다. 변이는 내부 포인터가 가리키는 메모리 레이아웃을 무효화할 수 있다.
예: Vec의 원소에 대한 포인터를 얻을 수 있다. Vec이 커지면 새 메모리를 할당해 기존 데이터를 복사할 수 있고, 그러면 그 내부 포인터는 무효화(가리키는 레이아웃 붕괴)될 수 있다. 가변 빌림의 배타성은 이를 방지한다:
fn main() { let mut vec: Vec<u32> = vec!(1, 2, 3); let interior_pointer: &u32 = &vec[0]; vec.push(4); print!("{}", *interior_pointer); }
컴파일 에러:
3 | let interior_pointer: &u32 = &vec[0]; | --- immutable borrow occurs here4 | vec.push(4); | ^^^^^^^^^^^ mutable borrow occurs here5 | print!("{}", *interior_pointer); | ----------------- immutable borrow later used here
또 다른 예는 enum에 관한 것이다. enum 내부를 가리키는 내부 포인터도 무효화될 수 있다. enum 변형마다 메모리 레이아웃이 다르기 때문이다. 한 레이아웃에서 처음 8바이트가 정수일 수 있지만, 다른 레이아웃에서는 처음 8바이트가 포인터일 수 있다. 임의의 정수를 포인터로 취급하는 것은 확실히 메모리 안전하지 않다.
enum DifferentMemoryLayout { A(u64, u64), B(String) } fn main() { let mut v: DifferentMemoryLayout = DifferentMemoryLayout::A(1, 2); let interior_pointer: &u64 = match v { DifferentMemoryLayout::A(ref a, ref b) => {a} DifferentMemoryLayout::B(_) => { panic!() } }; v = DifferentMemoryLayout::B("hello".to_string()); println!("{}", *interior_pointer); }
컴파일 에러:
9 | DifferentMemoryLayout::A(ref a, ref b) => {a} | ----- vis borrowed here...12 | v = DifferentMemoryLayout::B("hello".to_string()); | ^v is assigned to here but it was already borrowed13 | println!("{}", *interior_pointer); | ----------------- borrow later used here
때로는 변이가 내부 포인터의 유효성을 유지하기도 한다. 예: Vec<u32>의 원소를 변경해도 내부 포인터가 무효화되지 않는다(메모리 레이아웃 변화 없음). 하지만 Rust는 기본적으로 내부 포인터가 존재할 때 모든 변이를 막는다(내부 가변성 사용 제외).
Golang도 내부 포인터를 지원하지만, 이런 제약은 없다. 예: 슬라이스 내부 포인터:
package mainimport "fmt"func main() {\tslice := []int{1, 2, 3}\tinteriorPointer := &slice[0]\tslice = append(slice, 4)\tfmt.Printf("%v\n", *interiorPointer)\tfmt.Printf("old interior pointer: %p new interior pointer: %p\n", interiorPointer, &slice[0])}
출력
1old interior pointer: 0xc0000ac000 new interior pointer: 0xc0000ae000
슬라이스가 재할당된 후에도, 이전 슬라이스는 메모리에 남아있다(즉시 해제되지 않는다). 이전 슬라이스로의 내부 포인터가 있으면, GC는 이전 슬라이스를 해제하지 않는다. 내부 포인터는 항상 메모리 안전하다(하지만 오래된 데이터를 가리킬 수 있다).
Golang에는 합타입이 없으므로, 앞선 Rust 예시처럼 enum 레이아웃 변경에 해당하는 것이 없다.
또한, Golang은 맵 엔트리 값으로의 내부 포인터 획득을 허용하지 않지만, Rust는 허용한다. Rust의 내부 포인터는 Golang보다 강력하다.
Java에는 내부 포인터가 없다. 따라서 내부 포인터로 인한 메모리 안전 문제도 없다.
다만 Java에 논리적으로 내부 포인터와 유사한 것이 있다: Iterator. 컨테이너 변이는 이터레이터 무효화를 초래할 수 있다:
public class Main { public static void main(String[] args) { List<Integer> list = new ArrayList<>(); list.add(1); Iterator<Integer> iterator = list.iterator(); while (iterator.hasNext()) { Integer value = iterator.next(); if (value < 3) { list.remove(0); } } } }
java.util.ConcurrentModificationException이 발생한다. Java의 ArrayList는 내부 버전 카운터가 있고, 변경될 때마다 증가한다. 이터레이터는 버전 카운터로 동시 수정 여부를 검사한다.
버전 검사가 없어도, 배열 접근은 범위 체크가 있어 메모리 안전하다.
Java의 컨테이너 for 루프는 내부적으로 이터레이터를 사용한다(원시 배열 제외). 순회 중 컨테이너 삽입/제거는 이터레이터 무효화를 초래할 수 있다.
이터레이션 무효화는 메모리 안전 여부와 무관하게 논리 오류라는 점에 유의.
Java에서는 이터레이터를 통해 요소를 제거할 수 있고, 그러면 이터레이터는 컨테이너와 함께 업데이트되어 더 이상 무효화되지 않는다. 또는 removeIf를 사용해 이터레이터 관리를 피할 수 있다.
요컨대, 내부 포인터 때문에 단일 스레드에서도 가변 빌림의 배타성이 중요하다. 하지만 내부 포인터를 전혀 쓰지 않는다면, 단일 스레드에서 메모리 안전을 위해 가변 빌림의 배타성은 필수는 아니다.
그래서 주류 언어는 가변 빌림의 배타성이 없어도 단일 스레드에서 잘 동작한다. Java, JS, Python에는 내부 포인터가 없다. Golang과 C#은 내부 포인터가 있지만 GC가 있고 내부 포인터를 제한하므로, 가변 빌림의 배타성 없이도 메모리 안전이 유지된다.
Rust의 가변 빌림 배타성은 단일 스레드에서 많은 골칫거리를 만든다. 하지만 이점도 있다(단일 스레드에서도):
가변 빌림의 배타성은 과도하게 제한적이다. 내부 포인터를 사용하지 않는 단일 스레드 코드에서 메모리 안전에 필수적이지 않다. 내부 가변성이 있어 그 제약을 벗어날 수 있다.
내부 가변성은 불변 참조로도 무언가를 변이할 수 있게 한다. (그래서 불변 빌림이라도 실제로 불변이 아닐 수 있어 혼동을 초래할 수 있다.)
내부 가변성 수단:
이들은 보통 참조 카운팅(Arc<...>, Rc<...>) 안에서 사용된다.
Rust GUI 프레임워크의 내부 가변성 처리:
RefCell is not panacea앞선 전파적 빌림 사례에서 부모를 RefCell<>로 감싸면 코드가 컴파일된다. 그러나 이는 문제를 해결하지 않는다. 단지 컴파일 에러를 런타임 패닉으로 바꿀 뿐이다:
use std::cell::RefCell; pub struct Parent { total_score: u32, children: Vec<Child> } pub struct Child { score: u32 } impl Parent { fn get_children(&self) -> &Vec<Child> { &self.children } fn add_score(&mut self, score: u32) { self.total_score += score; } } fn main() { let parent: RefCell<Parent> = RefCell::new(Parent{total_score: 0, children: vec![Child{score: 2}]}); for child in parent.borrow().get_children() { parent.borrow_mut().add_score(child.score); } }
RefCell already borrowed 에러로 패닉한다.
RefCell도 여전히 가변 빌림 배타성 규칙을 따른다. 단지 컴파일 시가 아니라 런타임에 검사할 뿐이다. RefCell의 한 필드를 빌리는 것도 RefCell 전체를 빌린 것으로 간주된다.
부모를 RefCell로 감싸는 것은 전파적 빌림을 해결하지 못하지만, 개별 자식을 RefCell에 넣는 것은 빌림을 더 세분화하므로 효과가 있다.
참고: Dynamic borrow checking causes unexpected crashes after refactorings
Rust는 &mut T 가변 빌림이 있으면 언제든 그 참조를 사용할 수 있다고 가정한다. 하지만 “참조를 보유하는 것”과 “참조를 사용하는 것”은 다르다. 동일 객체에 대한 가변 참조를 둘 가지고도, 한 번에 하나씩만 사용할 수도 있다. 이 경우 RefCell이 해결책이 된다.
다른 문제: RefCell에서 얻은 빌림은 직접 반환할 수 없다.
pub struct Parent { entries: RefCell<HashMap<String, Entry>>, ...} pub struct Entry { score: u32 } impl Parent { fn get_entries(&self) -> &HashMap<String, Entry> { self.entries.borrow() } ...}
컴파일 오류:
error[E0308]: mismatched types --> src\main.rs:10:9 |9 | fn get_entries(&self) -> &HashMap<String, Entry> { | ----------------------- expected &HashMap<String, Entry>because of return type10 | self.entries.borrow() | ^^^^^^^^^^^^^^^^^^^^^ expected&HashMap<String, Entry>, found Ref<', HashMap<String, Entry>> | = note: expected reference&HashMap<, > found structRef<', HashMap<_, _>>help: consider borrowing here |10 | &self.entries.borrow() | +
RefCell에서 얻은 빌림은 일반 빌림이 아니라 Ref다. Ref는 Deref를 구현하므로 일반 빌림처럼 사용할 수 있다.
“여기서 빌리라는” 컴파일러의 도움말은 오류를 해결하지 못한다. 컴파일러 제안을 맹신하지 말라.
한 가지 해결책은 &HashMap<String, Entry> 대신 &RefCell<HashMap<String, Entry>>를 반환하는 것이다.
Ref<HashMap<String, Entry>>를 반환하거나 impl Deref<Target=HashMap<String, Entry>>를 반환하는 것도 가능하지만 권장하지 않는다.
Rc<RefCell<...>> and Arc<Mutex<...>> are not panaceaRc<RefCell<...>>와 Arc<Mutex<...>>는 다른 언어처럼 참조를 자유롭게 복사하고 자유롭게 변이할 수 있게 해준다. 드디어 “빌림 검사기의 족쇄에서 벗어난” 느낌을 줄 수 있다. 그러나 함정이 있다:
QCellQCell<T>은 내부 ID를 가진다. QCellOwner도 ID다. 일치하는 ID를 가진 QCellOwner를 통해서만 QCell을 사용할 수 있다.
QCellOwner에 대한 빌림이, 그것과 연관된 여러 QCell들의 빌림을 “중앙집중화”하여 가변 빌림의 배타성을 보장한다. 사용하려면 QCellOwner의 빌림을 쓰이는 곳마다 인수로 전달해야 한다.
QCell은 소유자 ID가 일치하지 않으면 빌림에 실패한다. RefCell과 달리, ID가 일치하면 중첩 빌림이라고 해서 패닉하지 않는다.
런타임 비용은 낮다. 빌림 시 셀의 id가 오너의 id와 일치하는지만 확인한다. 각 셀에 오너 ID만큼의 메모리 비용이 있다.
QCell의 장점 하나는, 중복 빌림이 런타임 패닉이 아니라 컴파일 에러가 된다는 점이다. 문제를 더 일찍 잡을 수 있다. 앞선 RefCell 패닉 예시를 QCell로 바꿔보자:
pub struct Parent { total_score: u32, children: Vec<Child> }pub struct Child { score: u32 }impl Parent { fn get_children(&self) -> &Vec<Child> { &self.children } fn add_score(&mut self, score: u32) { self.total_score += score; }}fn main() { let owner: QCellOwner = QCellOwner::new(); let parent: QCell<Parent> = QCell::new(&owner, Parent{total_score: 0, children: vec![Child{score: 2}]}); for child in parent.ro(&owner).get_children() { parent.rw(&mut owner).add_score(child.score); }}
컴파일 에러:
17 | for child in parent.ro(&owner).get_children() { | -------------------------------- | | | | | immutable borrow occurs here | immutable borrow later used here18 | parent.rw(&mut owner).add_score(child.score); | ^^^^^^^^^^ mutable borrow occurs here
런타임 패닉을 컴파일 에러로 바꿔, 문제 발견을 더 빠르게 한다.
GPUI의 Model<T>는 Rc<QCell<T>>와 유사하며, GPUI의 AppContext는 QCellOwner에 해당한다.
멀티스레드에서도 RwLock<QCellOwner>를 써서 동작시킬 수 있다. 이렇게 하면 여러 장소의 많은 데이터를 하나의 락으로 보호할 수 있다. 7
Ghost cell과 LCell은 QCell과 유사하지만, 클로저 라이프타임을 오너 ID로 사용한다. 제로 오버헤드지만 더 제한적이다(오너가 클로저 스코프에 묶이고 동적 생성/수명이 어렵다).
재진입 가능한 락이란, 한 스레드가 한 락을 잠근 뒤 같은 락을 또 잠그고, 두 번 풀어도 데드락이 나지 않는 것을 말한다. Rust의 락은 재진입 불가다. (Rust의 락은 가변 빌림의 배타성을 지키는 역할도 한다. 재진입을 허용하면 동일 객체에 대한 두 개의 &mut가 생길 수 있다.)
예: Java에서는 2중 잠금이 데드락을 일으키지 않는다:
public class Main { public static void main(String[] args) { Object lock = new Object(); synchronized (lock) { synchronized (lock) { System.out.println("within two layers of locking"); } } System.out.println("finish"); } }
하지만 Rust의 동등 코드는 데드락이 난다:
fn main() { let mutex: Mutex<u64> = Mutex::new(0); { let mut g1: MutexGuard<u64> = mutex.lock().unwrap(); { println!("going to do second-layer lock"); let mut g2 = mutex.lock().unwrap(); println!("within two layers of locking"); } } println!("finish"); }
“going to do second-layer lock”까지 출력하고 데드락.
Rust에서는 어느 스코프가 락을 보유하는지 분명히 하는 것이 중요하다. Golang의 락도 재진입 불가다.
또 다른 중요한 점은 Rust는 기본적으로 스코프 끝에서만 언락한다는 것이다. mutex.lock().unwrap()은 MutexGuard<T>를 준다. MutexGuard는 Drop을 구현해, 스코프 끝에서 드롭된다. Drop을 구현하지 않은 지역 변수는(빌리지 않았다면) 마지막 사용 이후 드롭된다. 이를 NLL(비-어휘적 라이프타임)이라 한다.
Arc is not always fastArc는 참조 카운트를 바꾸기 위해 원자 연산을 사용한다(Arc의 복제/드롭은 카운트를 바꾸지만, Arc의 빌림은 바꾸지 않는다).
그러나 많은 스레드가 같은 원자 카운터를 자주 바꾸면 성능이 저하될 수 있다. 이를 건드리는 스레드가 많을수록 더 느려진다.
현대 CPU는 캐시 일관성 프로토콜(MOESI 등)을 사용한다. 원자 연산은 종종 CPU 코어가 해당 캐시 라인에 대한 “배타적 소유권”을 가져야 한다(하드웨어에 따라 다를 수 있다). 많은 스레드가 자주 그렇게 하면 하드웨어 수준에서 락 경쟁과 유사한 캐시 경합이 생긴다.
예시 1, 예시 2
원자 참조 카운팅은 경합이 없다면(대부분 한 스레드만 카운트를 바꾸는 경우) 여전히 빠르다. Apple Silicon에서 원자 참조 카운팅은 인텔 CPU보다 빠른 편이다. 8
해결책:
이런 지연된 메모리 회수(hazard pointer, epoch-based)는 락-프리 자료구조에도 쓰인다. 한 스레드가 요소를 읽는 동안 다른 스레드가 같은 요소를 제거·해제한다면 메모리 안전하지 않다(GC 언어에는 없는 이슈).
“GC”라는 단어에는 약간의 모호함이 있다. 참조 카운팅을 GC로 보기도, 아니라고 보기도 한다.
정의와 무관하게, 참조 카운팅은 트레이싱 GC(Java/JS/C#/Golang 등)와 다르다:
| Reference counting | Tracing GC |
|---|---|
| 즉시 해제 | 지연·배치 해제 9 |
| 큰 구조 전체 해제가 큰 지연을 유발할 수 있음 10 | 높은 성능엔 더 많은 메모리가 필요(그렇지 않으면 GC 지연이 큼) |
| 최대 고정점(greatest fixed point)을 찾음 | 최소 고정점(least fixed point)을 찾음 |
| “죽음”을 전파(한 객체 해제가 자식 해제를 유발) | “생존”을 전파(살아있는 객체가 자식도 살게 함, 약한 참조 제외) |
| 참조 복제/드롭에 원자 연산(단일 스레드 Rc 제외) | 힙 참조 읽기/쓰기에 read/write barrier가 개입(대개 분기, 원자 접근 아님) |
| 순환을 자동 처리 못함. 약한 참조로 끊어야 함 | 순환을 자동 처리 |
| 비용은 대략 O(참조 카운트 변경 빈도) 11 | 비용은 대략 O(살아있는 객체 수 × GC 빈도) 12 |
bumpalo는 bump allocator를 제공한다. bump allocator에서 할당은 보통 정수 하나를 증가시키는 것으로 빨라진다. 전체 아레나를 빠르게 해제할 수 있지만, 개별 객체 해제를 지원하지 않는다.
일반 할당자보다 보통 빠르다. 일반 할당자는 각 할당·해제마다 많은 부기 작업을 한다. 개별 영역을 따로 해제하고 재사용할 수 있어, 정보 기록·갱신이 필요하다.
bump allocator는 메모리를 지연·배치 해제한다. 개별 객체 해제가 불가하므로 일시적으로 더 많은 메모리를 쓸 수 있다.
bump allocator는 임시 객체에 적합하며, 작업이 끝난 뒤 이 임시 객체가 전혀 필요 없다는 확신이 있을 때 유용하다.
명확성을 위해 바꾼 할당 함수 시그니처:
impl Bump { ... pub fn alloc<T, 'bump>(&'bump self, val: T) -> &'bump mut T { ... }}
이는 Bump의 불변 빌림을 받는다(내부 가변성 보유). val을 bump 할당된 메모리로 이동시킨다. 반환은 bump allocator와 동일 라이프타임의 가변 빌림이다. 이 라이프타임이 메모리 안전을 보장한다(할당 결과의 빌림이 bump allocator보다 오래 살 수 없음).
할당 결과 빌림을 오래 보유하고 싶다면 라이프타임 표기가 흔히 필요하다. Rust에서 라이프타임 표기도 전염적이다:
어떤 것에 라이프타임을 추가/제거하는 리팩토링은, 이를 사용하는 많은 코드 변경을 수반할 수 있어 큰 작업이 될 수 있다. 어떤 라이프타임 파라미터가 필요한지 신중히 계획하라.
Bump는 Sync를 구현하지 않아 &Bump는 Send가 아니다. 스레드 간 공유할 수 없다(공유하더라도 구조적 동시성 강제가 있을 것이다). 각 스레드에 로컬 bump allocator를 두는 것을 권장한다.
Bump와 그로 할당된 참조를 함께 두면 자기 참조가 되는데, 이는 어렵고 unsafe가 필요하다. Bump를 스택에 두고 임시로 사용하는 것을 권장한다.
unsafe를 사용하면 포인터를 자유롭게 다루고 빌림 검사기의 제약을 벗어날 수 있다. 하지만 unsafe Rust를 작성하는 건 C를 쓰는 것보다 더 어렵다. 안전한 Rust 코드가 기대하는 제약을 깨지 않도록 매우 주의해야 하기 때문이다. unsafe 코드의 버그가 안전 코드에도 문제를 일으킬 수 있다.
unsafe를 올바르게 작성하는 것은 어렵다. 몇 가지 함정:
가변 빌림 배타성을 위반하지 말라.
포인터 출처(provenance).
서로 다른 출처로 생성된 두 포인터는 절대 별칭(alias)하지 않는 것으로 간주된다. 주소가 같으면 정의되지 않은 동작.
정수→포인터 변환은 출처 없는 포인터를 만들며, 이를 사용하는 것은 정의되지 않은 동작이다. 단, 다음 두 경우 예외:
포인터에 정수를 더해도 출처는 바뀌지 않는다.
출처는 컴파일러가 컴파일 타임에 추적한다. 실제 실행에서는 포인터는 여전히 출처 정보 없는 정수 주소다. 13
미초기화 메모리 사용은 정의되지 않은 동작. MaybeUninit 참조.
a = b는 a의 기존 객체를 그 자리에 드롭한다. a가 미초기화 상태이면, 미초기화 객체를 드롭하게 되어 정의되지 않은 동작. addr_of_mut!(...).write(...)를 써라.
패닉 언와인딩 처리.
멀티스레드에서 공유 가변 데이터의 읽기/쓰기에는 원자 또는 volatile 접근(read_volatile, write_volatile)이나 다른 동기화(락 등)를 사용해야 한다. 그렇지 않으면 최적화기가 읽기/쓰기 병합과 재배치를 잘못할 수 있다. volatile 자체로는 메모리 순서를 보장하지 않는다(Java volatile과 다름).
……
현대 컴파일러는 가능한 한 많이 최적화하려 한다. 이를 위해 가능한 한 많은 가정을 한다. 어떤 가정이든 깨면 잘못된 최적화로 이어질 수 있다. 그래서 복잡하다.
불행히도 Rust의 생 포인터 문법 인체공학은 아직 좋지 않다:
현재 빌림 검사기는 분기에서 거친 분석을 한다. 한 분기의 출력 빌림이 다른 분기에 전파된다.
현재(링크 참고) 아래 코드는 컴파일되지 않는다:
fn get_default<'r, K: Hash + Eq + Copy, V: Default>( map: &'r mut HashMap<K, V>, key: K,) -> &'r mut V { match map.get_mut(&key) { // -------------+ 'r Some(value) => value, // | None => { // | map.insert(key, V::default()); // | // ^~~~~~ ERROR // | map.get_mut(&key).unwrap() // | } // | } // |}
첫 분기 Some(value) => ...의 반환값이 map을 간접적으로 가변 빌리므로, 두 번째 분기도 map을 간접적으로 가변 빌리게 되어, 스코프의 다른 가변 빌림과 충돌한다.
이는 Polonius 빌림 검사기가 해결할 예정이다. 현재(2025년 8월) 나이틀리에서 옵션으로 활성화 가능하다.
Send and SyncRust는 트리형 소유권을 선호한다. 각 객체는 정확히 한 곳에서만 소유된다. 트리형 데이터를 다른 스레드로 보내면 오직 한 스레드만 접근하므로 스레드 안전하다. 데이터 레이스가 없다.
불변 빌림을 다른 스레드로 보내는 것도, 공유 데이터가 실제로 불변이라면 괜찮다.
하지만 예외가 있다. 하나는 내부 가변성이다. 내부 가변성 때문에 &T가 가리키는 데이터가 실제로 불변이 아닐 수 있다. 그래서 Rust는 Cell<T>와 RefCell<T>를 Sync가 아니게 만들어 &Cell<T>, &RefCell<T>의 공유를 막는다. X가 Sync라면 &X는 Send다. X가 Sync가 아니면 &X는 Send가 아니다. 이는 Cell과 RefCell의 스레드 간 공유를 막는다.
Rc도 내부에 공유 가변 참조 카운터가 있다. 원자적이지 않으므로 Rc는 스레드 간에 전달될 수 없다. Send도 Sync도 아니다.
하지만 &Mutex<T>는 락이 보호하므로 공유 가능하다. &AtomicU32 같은 원자 셀의 불변 참조도 원자성 때문에 공유 가능하다. Mutex<T>와 AtomicU32는 Sync이므로 &Mutex<T>와 &AtomicU32는 Send다.
Sync지만 Send가 아닌 것도 있다. 예: MutexGuard. 이미 잠겨 있는 것을 다른 스레드에 잠시 공유하는 건 괜찮다. 하지만 MutexGuard를 다른 스레드로 이동시키는 것은, 락이 스레드에 묶여 있으므로 허용되지 않는다.
Send + 'staticTokio는 인기 있는 async 런타임이다. Tokio에서 태스크 제출은 미래(future)가 Send이면서 'static이어야 한다.
pub fn spawn<F>(future: F) -> JoinHandle<F::Output> where F: Future + Send + 'static, F::Output: Send + 'static,
스폰된 future는 오래 보관될 수 있다. 스코프 내에서만 잠깐 존재하는 게 아닐 수 있다. 그래서 'static이 필요하다. tokio_scoped는 'static이 아닌 future 제출을 허용하지만, 스코프 내에서 완료되어야 한다.
future가 외부와 데이터를 공유해야 한다면, &Arc<T>가 아니라 Arc<T>를 이동시켜 넘겨라.
C/C++/Java/C#의 “static”은 보통 전역 변수를 의미하지만, Rust에서는 의미가 다르다.
Send는 future를 스레드 간 이동하지 않는 async 런타임에서는 필요 없다.
Rust는 async 함수를 상태 머신(= future)으로 변환한다. async 함수에서 await 사이에 사용되는 지역 변수는 future의 필드가 된다. future가 Send여야 한다면, 이 지역 변수들도 Send여야 한다.
C와 GC 언어에서:
하지만 Rust는 다르다.
임시 값은 평가 직후 드롭된다. 다만 그 값에 대한 빌림이 있으면 빌림만큼 라이프타임이 연장된다(임시 라이프타임 확장).
지역 변수에 담긴 값:
정리:
보통 &mut T 가변 빌림은 이동만 가능하고 복사할 수 없다.
하지만 재빌림(reborrow) 기능이 있어 때로는 가변 빌림을 여러 번 사용할 수 있다. 재빌림은 실전 Rust 코드에서 매우 흔하다. 재빌림은 명시적으로 문서화되어 있지 않다. 참고.
예:
fn mutate(i: &mut u32) -> &mut u32 { *i += 1; i } fn mutate_twice(i: &mut u32) -> &mut u32 { mutate(i); mutate(i) }
이 코드는 동작한다. Rust는 첫 번째 mutate(i)를 암묵적으로 mutate(&mut *i)로 취급하여 i가 이동되지 않아 다시 사용할 수 있게 한다.
하지만 두 번째 i를 미리 지역 변수로 추출하면 컴파일되지 않는다:
fn mutate_twice(i: &mut u32) -> &mut u32 { let j: &mut u32 = i; mutate(i); mutate(j) }
7 | fn mutate_twice(i: &mut u32) -> &mut u32 { | - let's call the lifetime of this reference '18 | let j: &mut u32 = i; | - first mutable borrow occurs here9 | mutate(i); | ^ second mutable borrow occurs here10 | mutate(j) | --------- returning this value requires that *iis borrowed for'1``
tokio::spawn은 future가 독립적이고('static) 다른 것을 빌리지 않기를 요구한다.
나중에 사용할 Arc를 이동 캡처로 클로저에 넘기면, 클로저가 그 Arc를 소유한다. 빌림을 포함하는 데이터는 독립적이지 않다('static이 아니다).
#[tokio::main] async fn main() { let data: Arc<u64> = Arc::new(1); let task1_handle = tokio::spawn(async move { println!("From task: Data: {}", *data); }); println!("From main thread: Data: {}", *data); }
컴파일 오류
6 | let data: Arc<u64> = Arc::new(1); | ---- move occurs because datahas typeArc<u64>, which does not implement the Copy trait7 |8 | let task1_handle = tokio::spawn(async move { | ---------- value moved here9 | println!("From task: Data: {}", *data); | ---- variable moved due to use in coroutine...12 | println!("From main thread: Data: {}", *data); | ^^^^ value borrowed here after move
Arc<T>를 수동으로 복제해 지역 변수에 넣으면, 복제본이 future로 이동된다:
#[tokio::main] async fn main() { let data: Arc<u64> = Arc::new(1); let data2 = data.clone(); // this is necessary let task1_handle = tokio::spawn(async move { println!("From task: Data: {}", *data2); }); println!("From main thread: Data: {}", *data); }
data2 지역 변수를 인라인하면 컴파일되지 않는다:
#[tokio::main] async fn main() { let data: Arc<u64> = Arc::new(1); let task1_handle = tokio::spawn(async move { println!("From task: Data: {}", *data.clone()); }); println!("From main thread: Data: {}", *data); }
5 | let data: Arc<u64> = Arc::new(1); | ---- move occurs because datahas typeArc<u64>, which does not implement the Copy trait6 | let task1_handle = tokio::spawn(async move { | ---------- value moved here7 | println!("From task: Data: {}", *data.clone()); | ---- variable moved due to use in coroutine8 | });9 | println!("From main thread: Data: {}", *data); | ^^^^ value borrowed here after move
문법 인체공학 개선 제안이 있다.
“Rust는 unsafe 코드를 안전하게 보장하지 않으니, unsafe를 쓰면 Rust를 쓰는 의미가 없다.” 아니다. unsafe를 소량으로 제한하면, 메모리/스레드 안전 문제가 생길 때 검사해야 할 unsafe 코드의 양이 작아진다. C/C++에서는 관련 모든 코드를 살펴봐야 한다. Rust에서 다량의 unsafe 사용은 권장하지 않지만, 그렇다고 의미가 사라지는 건 아니다.
“아레나는 use-after-free에 상응하는 문제를 여전히 겪으니, 문제를 해결하지 못한다.” 아니다. 아레나는 이런 버그를 훨씬 결정적으로 만들어, 메모리 안전 하이젠버그를 막고 디버깅을 크게 쉽게 만든다. 15
“Rust 빌림 검사기가 코드를 거부하는 건 코드가 틀려서다.” 아니다. Rust는 유효하고 안전한 코드도 거부할 수 있다.
“이중 연결 리스트는 쓸모없다.” 아니다. 유용한 경우가 많다. 리눅스 커널도 사용한다. 다만 트리나 해시맵이 수동 구현 이중 연결 리스트를 대체할 수 있는 때가 많다.
“순환 참조는 나쁘니 피해야 한다.” 아니다. 순환 참조는 유용한 경우가 많다. 다만 위험을 수반한다.
“Rust는 높은 성능을 보장한다.” 아니다. Arc<Mutex<>>를 남발해 빌림 검사기를 피하면, 일반 GC 언어보다 느릴 수 있고 데드락 위험도 크다. 하지만 Rust에서 높은 성능을 달성하기가 더 쉽다. 다른 언어에서는 높은 성능을 내려면 언어 기능을 많이 우회(핵)해야 하는 경우가 잦다.
“Rust는 보안을 보장한다.” 아니다. 모든 보안 이슈가 메모리/스레드 안전 이슈는 아니다. CWE 2024에 따르면, 실제 취약점의 상당수는 XSS, SQL 인젝션, 디렉터리 트래버설, 커맨드 인젝션, 인증 누락 등 메모리/스레드 안전과 무관하다.
“Rust는 메모리/스레드 안전 외엔 도움을 주지 않는다.” 아니다.
“불변 자료구조는 Rust가 강요한 꼼수다.” 아니다. 불변 자료구조는 우발적 변이에 의한 많은 버그를 예방한다. 올바르게 쓰면 복잡도를 줄인다. 지속 자료구조는 롤백 같은 작업에도 효율적이다.
“메모리 안전은 Rust에서만 가능하다.” 아니다. 대부분의 GC 언어는 메모리 안전하다. 16 기존 C/C++ 애플리케이션의 메모리 안전은 Fil-C로 달성 가능하다.
Rust는 데이터 지향 설계를 선호한다. Rust는 OOP에 맞지 않는다. Rust는 가변 데이터 공유를 달가워하지 않는다. Rust는 순환 참조를 달가워하지 않는다. Rust는 옵저버 패턴에 불친절하다. 게터/세터는 전파적 빌림 문제를 쉽게 야기한다. 공유와 변이에는 많은 제한이 있다.
Rust는 유연성이 낮고, 빠른 반복(quick iteration)에 잘 맞지 않는다(숙련자라면 예외).
Rust의 제약은 인간과 AI 모두에 적용된다. 큰 C/C++ 코드베이스에서는, 인간도 AI도 비자명한 방식으로 메모리/스레드 안전을 깨뜨리기 쉽다. Rust는 이를 막아준다. 인기 OSS는 종종 AI 생성 PR의 홍수에 시달린다. Rust는 PR 리뷰를 쉽게 만든다: CI가 통과하고 unsafe를 쓰지 않았다면, 메모리/스레드 안전을 깨뜨리진 않는다. 물론 Rust가 논리 오류를 막아주지는 않는다.
네이티브 Rust 소유 관계는 트리를 이룬다. 참조 카운팅(Rc, Arc)은 공유 소유를 허용한다. ↩
여기서 “참조”는 일반 OOP 문맥의 참조(소유권과 비소유 참조를 구분하지 않는, Java/C#/JS/Python의 참조)를 뜻한다. Rust의 참조와는 다르다. 본 글에서는 Rust의 참조는 “빌림”으로 부를 것이다. ↩
구체적으로, 괴델은 기호·명제·증명을 정수(괴델 수)로 인코딩한다. 기호/명제/증명을 데이터로 인코딩하는 방법은 여럿 있고, 구체적 방법은 중요치 않다. 단순화를 위해 여기서는 모두 “데이터”로 취급하고, 데이터와 기호/명제/증명 사이의 변환은 무시하겠다. ↩
여기서 x(x)는 기호 치환이다. 자유 변수 x를 x로 치환하되, 필요한 경우 이름 충돌을 피하기 위해 바꿔 단다. Y 콤비네이터와도 유사: Y = f -> (x -> f(x(x))) (x -> f(x(x))). 이때 f = unprovable, H = x -> f(x(x)), Y(f) = H(H), Y(f)는 f의 고정점: f(Y(f)) = Y(f). G = Y(f), f(G) = G. ↩
ID와 객체 참조를 함께 쓰면 마찰이 생긴다: ID와 참조 간 변환. 일부 ORM은 같은 기본 키를 가진 객체가 둘 존재하면 오동작한다. ↩
각 슬롯맵은 키의 고유성을 보장하지만, 서로 다른 슬롯맵의 키를 섞으면 다른 슬롯맵의 키가 중복될 수 있다. 잘못된 키를 사용해도 요소를 “성공적으로” 얻을 수 있지만, 논리적으로는 틀릴 수 있다. ↩
때로는 미세한 락이, 락/언락이 많아져 더 느리다. 하지만 때로는 미세한 락이 더 높은 병렬성을 가능하게 해 더 빠르다. 때로는 미세한 락이 데드락을 만들지만, 굵은 락은 데드락이 없다. 구체적 경우에 달려 있다. ↩
참고. 2020년 당시 내용이며, 지금은 달라졌을 수 있다. 한 가지 가능성은 ARM이 x86보다 약한 메모리 순서를 허용한다는 점. 또한 Swift/Objective-C가 거의 모든 곳에서 참조 카운팅을 쓰므로, Apple이 원자 참조 카운팅 최적화에 더 공을 들였을 가능성. ↩
트레이싱 GC는 단명 프로그램(일부 CLI나 서버리스 함수)에 더 빠를 수 있다. 종료 시 개별 객체 메모리 해제가 필요 없기 때문이다. 예: My JavaScript is Faster than Your Rust. 같은 최적화는 Rust에서도 가능하지만(mem::forget, bump allocator 등) 추가 작업이 필요하다. ↩
큰 지연은 각 개별 객체마다 카운터 감소와 해제를 수행해야 하기 때문이다. Arc를 다른 스레드로 보내 그 스레드에서 드롭하는 우회책이 있다. 또한 깊은 구조에서는 드롭 중 스택 오버플로가 날 수 있다. ↩
경합된 원자 연산(여러 스레드가 동시에 한 원자 값을 만지는 것)은 경합이 없을 때보다 훨씬 느리다. 메모리 블록 할당/해제 비용도 포함된다. ↩
GC 빈도는 대략 할당 속도/여유 메모리에 비례한다. 세대별 GC에서 마이너 GC는 젊은 세대만 스캔하며, 비용은 대략 살아있는 젊은 세대 객체 수에 비례한다. 다만 가끔 전체 GC도 필요하다. ↩
Miri 같은 도구에서 실행할 때는 포인터 출처가 런타임에 추적된다. ↩
a() || b()에서 a()가 true면 b()는 실행되지 않는다. a() && b()에서 a()가 false면 b()는 실행되지 않는다. ↩
하이젠버그는 릴리스 빌드에서만, 디버그 빌드/산티나이저 켠 상태/로깅 켠 상태/디버거 켠 상태에서는 재현되지 않을 수 있다. 최적화, 산티나이저, 디버거, 로깅이 타이밍과 메모리 배치를 바꿔, 메모리/스레드 안전 버그가 더 이상 발생하지 않을 수 있기 때문이다. 큰 코드베이스에서 하이젠버그 디버깅은 수주, 수개월이 걸릴 수 있다. 모든 메모리/스레드 안전 버그가 하이젠버그인 것은 아니다. 쉽게 재현되는 것도 많다. ↩
Golang은 데이터 레이스 하에서 메모리 안전하지 않다. ↩