FoundationDBの動作原理とその優れた設計選択について詳細に解説します。設計の核心部分、失敗時のリカバリー、驚くべき主張の真相を掘り下げます。
FoundationDBは非常に優れたデータベースです。その論文はSIGMOD’21のベスト産業論文賞を受賞しました。本記事では、FDBがどのように動作するのかを詳細に説明し、彼らが取った興味深い設計選択について考察します。論文には含まれていない多くの詳細や(ときには正しさの証明すら)必要に応じて補いました。
非シャーディング型、厳格な直列化可能性を持つ、障害耐性のあるキーバリューストアで、ポイント書き込み、読み取り、範囲リードに対応しています。SQLではなくキーバリューAPIを提供。非シャーディングのため、すべてのキー空間は一つの論理的シャードに存在します。厳格直列化可能な(必要に応じて緩和可能)KVストアがあれば、その上にSQLエンジンやセカンダリインデックス等を積み重ねて分散データベースを構築できます。これは優れた設計選択です。
論文は冒頭で、いくつか驚異的な主張をしています。
これらの主張については本文を通じて検証します。
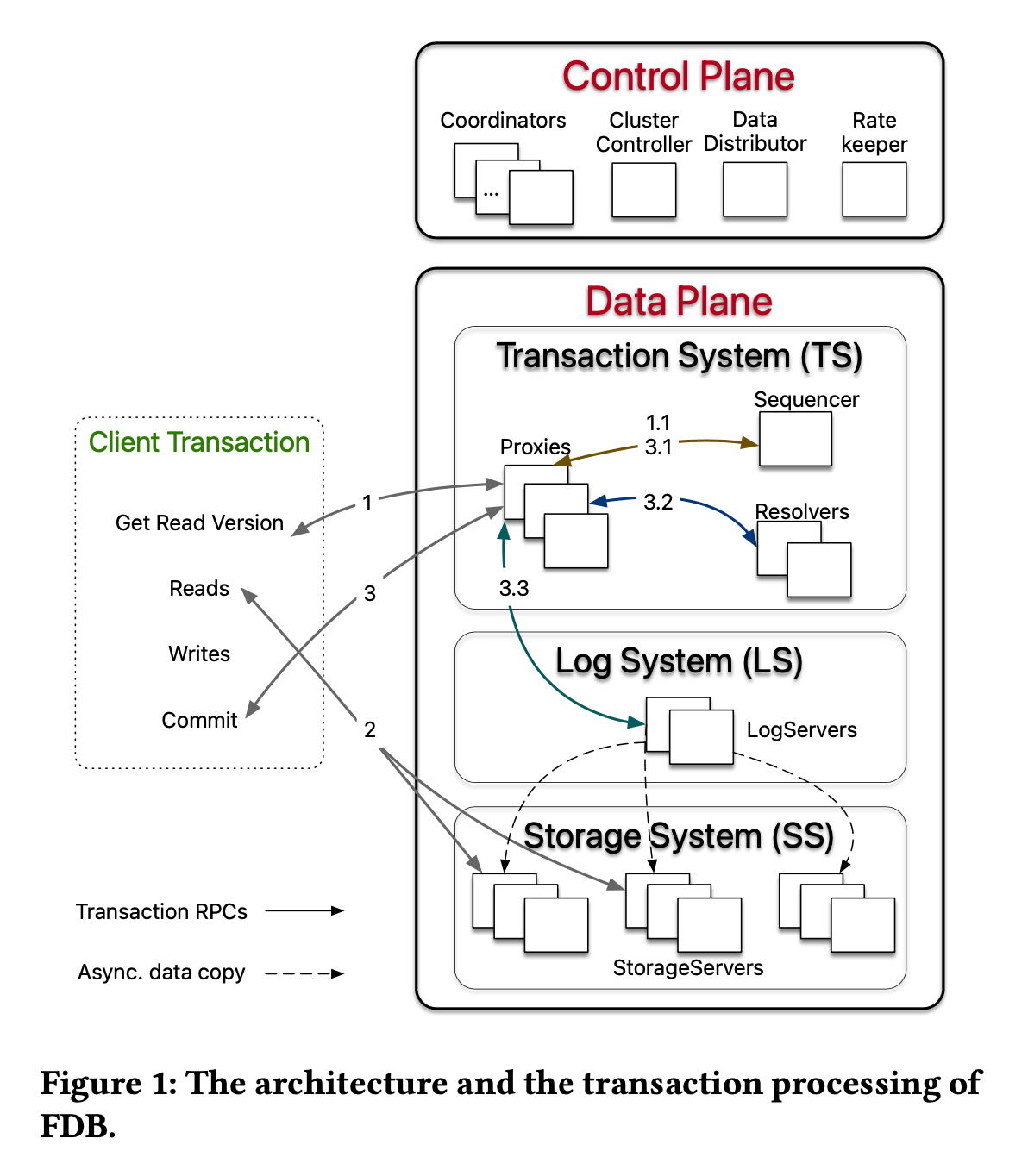
FDBはマイクロサービス(論文ではデカップリング)設計を極限まで推し進めており、ほぼ全ての機能が独立したサービス(ステートフルまたはステートレス)で処理されます。
図中で最も重要なControl Planeのサービスは「Coordinator」です。全体設定の小規模メタデータ(例:エポック情報など)を管理します。ClusterControllerは各サーバのヘルス状態を監視します。
Data Planeは“トランザクションシステム”、“ログシステム”、“ストレージシステム”に分かれます。ログ/ストレージシステムは分散ログ、および分散シャーディングされたストレージ構成。最も興味深いのはトランザクションシステムで、なかでも「Sequencer」が重要です。
クライアントは常にProxyに接続。Proxyが内部サービスと通信。
ProxyはSequencerからHLC(ハイブリッド論理クロック)形式でリードバージョンを取得。Sequencerは唯一無二の物理プロセスで、すべてのイベントのシリアライズ順序(直列化順序)を提供します。
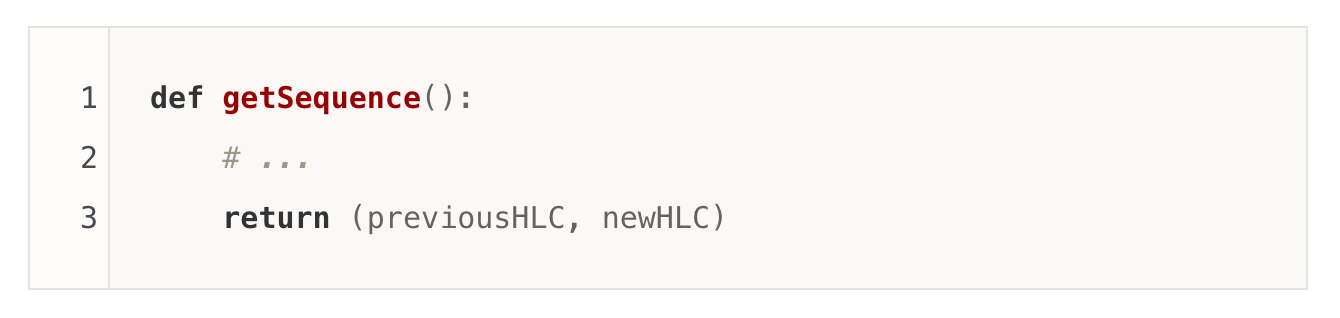
クライアントは取得したリードバージョンでストレージに読み取り要求(MVCCによる過去時点のデータ取得)。
再度Sequencerにコミットバージョンを要求。
書き込みセット&リードセットをResolverへ送信。Resolverはレンジごとにシャーディングされ、直近の書き込み履歴を短期間保持。ここで競合(リードセット対象データが[read-version, commit-version]間で変更された場合)を検出。
競合なしなら、コミットバージョンでLog Systemに書き込み。十分なACKを受信後、Proxyがクライアントに成功を返却。
これは楽観的並行制御(OCC)の非常にストレートな実装です。
Bhaskar Muppana氏の指摘に従い、一部文章を訂正しています。
Proxyが必要な理由は、ほとんどのRDBMSが提供する、「トランザクション中に未コミットの自身の書き込みを読める」機能を実現するためです。それはProxyサーバで未コミットの書き込みをローカルバッファに保持し、リード時にストレージのデータとマージして返すことで実現します。また、クライアントは未コミット書き込みをキャッシュし、同一トランザクション中の読込に対応します。
Proxyはクライアントとトランザクションシステムの仲介です。また、リクエストバッチ化(Sequencerに対するQPS軽減)などの役割も担います。
Resolverはレンジ単位でシャーディングされており、競合判定を並列化できます。Proxyはあらゆる関連Resolverからの応答を待つ必要があります。Resolverは最近の「書き込み試行」を記録し、それによって競合検出のみロック無しで実現。競合チェックは本当にロックフリーですが、Sequencerやシステム全体の順序付けには“どこかで”ロックや排他制御が必須です(OSカーネルやハードウェアのアトミック操作も広義のロック)。
SequencerやResolver故障時にも後ほど触れます。
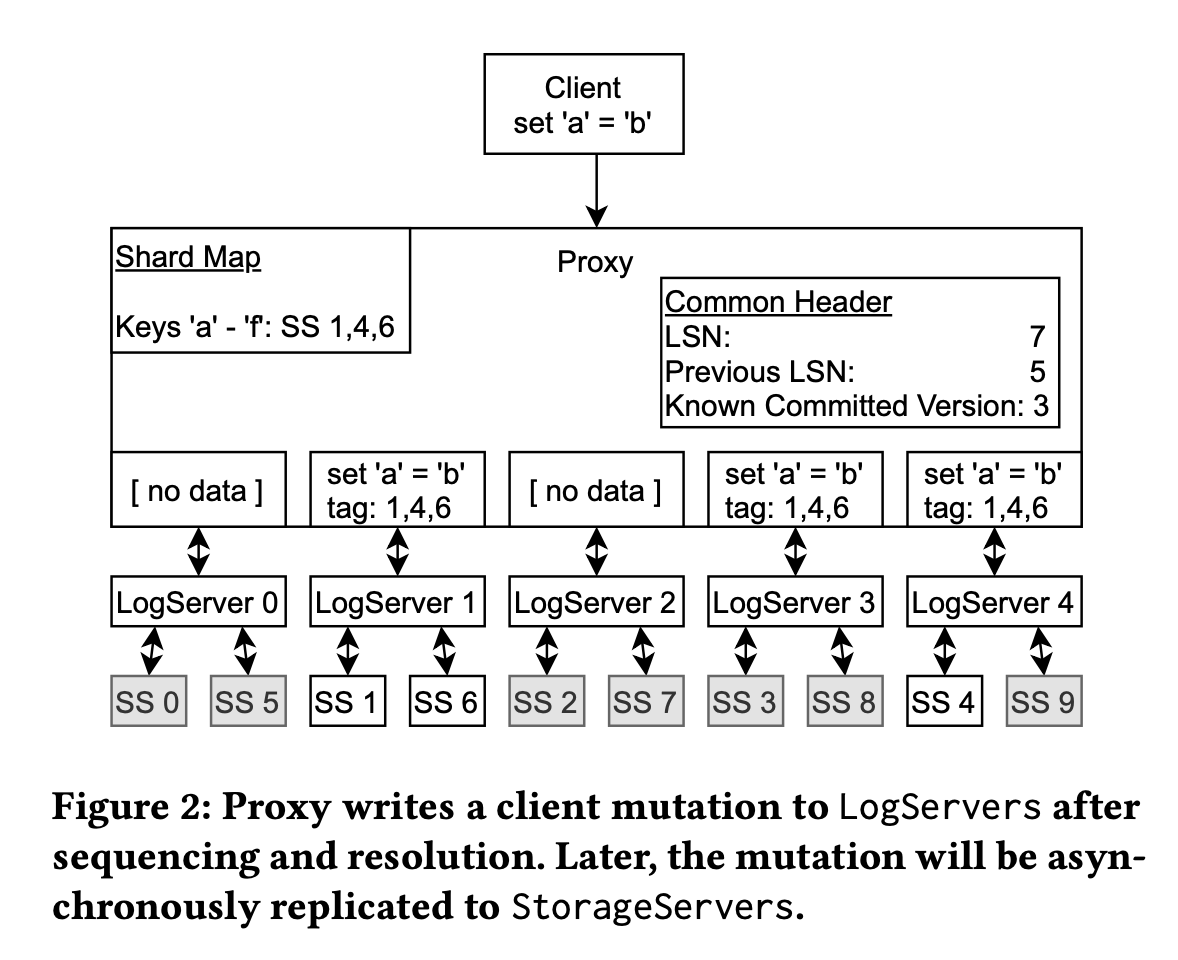
一見シンプルなログ&ストレージ分離ですが、FDBは「シーケンス」と「ログ」を本質的に分離しています。Sequencerは唯一。それ以外のLogServerはただデータを蓄積するのみで順序制御をしません。この分離により高スループット・低レイテンシを実現します。各LogServerには全Key用メッセージがブロードキャストされますが、実データは該当ストレージシャードに関連するLogServerにのみ送信されます。
ここで2PCは不要です。Proxyが複数ログに"盲目的"に書き込む(失敗しても再試行可能)ため、完全な分散コミット合意は無くても構いません。
この設計により、ログコミットの本当の障害はログサーバの実障害時のみです(その際は後述のリカバリープロセスが走る)。
「Sequencer1個で複数ログ・複数ストレージを支える」設計になっている点に注意してください。
SequencerやResolver/LogServerがダウンした際の流れは以下です:
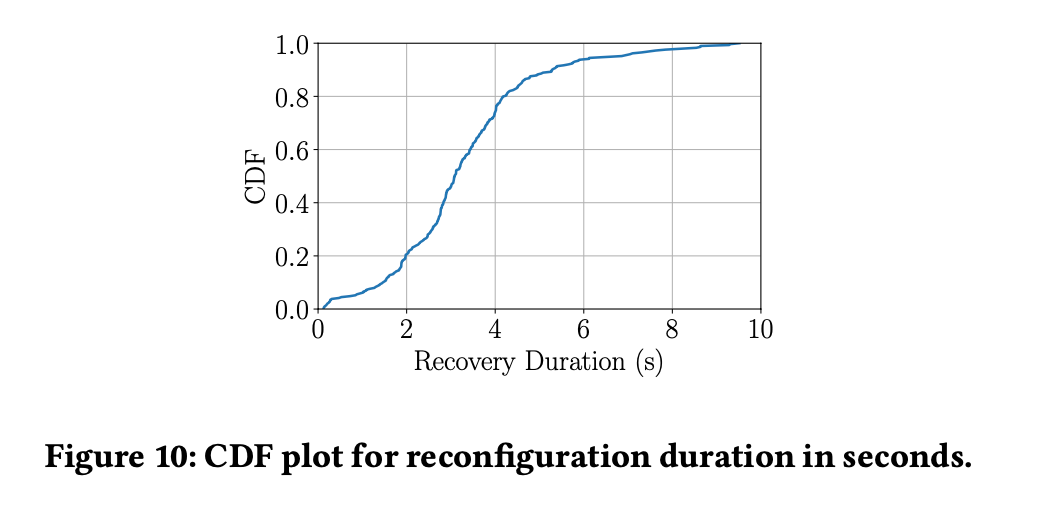
FDBのリカバリには「ダウンタイム」があります(P50で3.08秒)。この間、書き込みができません。ただしストレージノードからのスナップショットリードは可能であるため、FDBが読み中心のシーンに適している根拠とも言えます。
Proxyはステートレスなので再始動容易。Resolverは前エポック分を捨てて良い(エポックを跨いだトランザクション不可なため)。ログとSequencerのみが復旧の要。
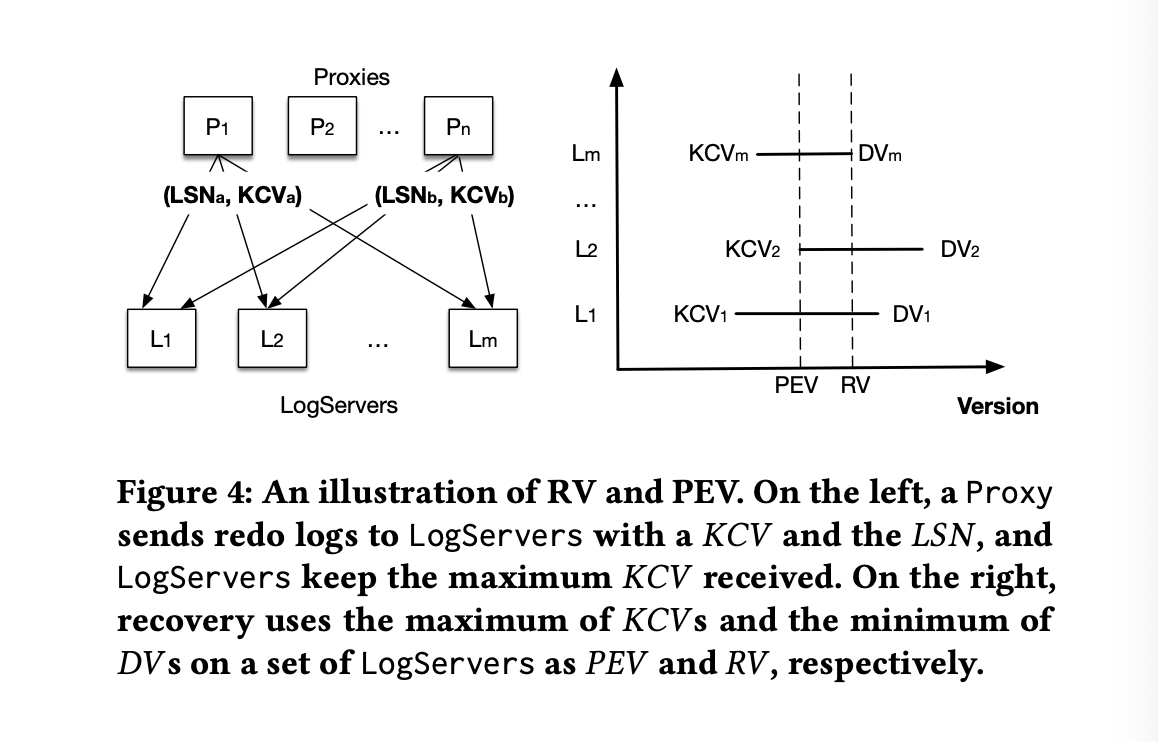
m台のLogServerとレプリカ数kの場合:
DV(Durable Version: 永続化済み最大LSN)とKCV(Proxyが知りうる最新Commit version)を保持。max(KCVs)までコミットされていたことが判明→新Sequencerは次バージョンから始動。論文で扱われているRV(Recovery Version)はmin(DVs)で、[PEV+1, RV]のデータを新ログに複製し、以降を破棄します。詳細は省略しますが以下2点のための措置です:
max(KCVs)までが完全コミット済とみなせる[PEV+1, RV]は安全側に倒してコミット済扱いとする・以降破棄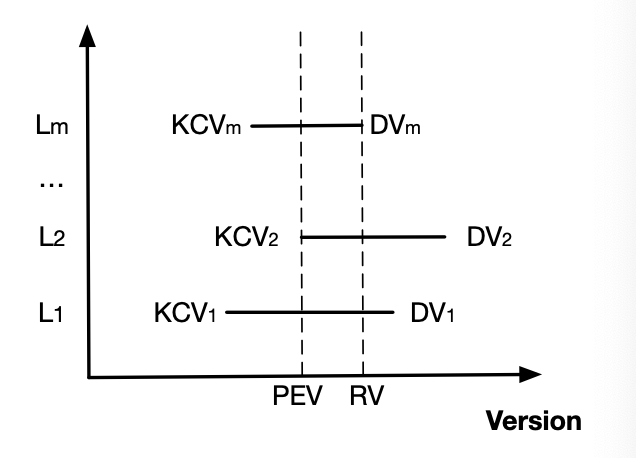
FDBは非常に優れたKVストアですが、論文冒頭のキャッチコピーはやや誇張・ミスリーディングな面があります。
FDBはおそらく、リージョナルなKVストアとして現存最良でしょう。シミュレーション基盤の堅牢性、優れた設計選択、密度の高い論文内容など、非常に高い評価に値します(一部仕様・細部・証明などが論文誌面の都合でカットされています)。FoundationDBチームに賛辞を送ります。